1. Mysql介绍
• MySQL是一款开源的关系型数据库管理系统,由瑞典MySQL AB公司1995年研发• 2008年被Sun公司收购,2009年Sun公司被Oracle公司收购.之后因担心有闭源的分险,由开发了MySQL的分支Maria DB
• MySQL6.x版本之后分为社区版和商业版
• MySQL是一种关联性数据库,将数据保存在不同的表中,而不是将所有的数据保存在一个大仓库内,增加了速度,提高了灵活度
• MySQL提供开源版本,不收取费用
• MySQL是可定制的,采用了GPL(GNV General Public Lincense)协议,可修改源代码来开发自己的MySQL
• MySQL支持大型数据库,可处理拥有上千万条的数据
• MySQL支持大数据,支持5000万条记录的数据包,32位表文件最大可支持4GB,64位支持8TB
• MySQL使用标准的SQL数据语言形式
• MySQL从5.7直接到了8.0
• 功能做出了显著的改进与增强
• 对MySQL的源代码进行了重构,对MySQL optimizer 优化器进行了改进,不仅速度提升,为用户带来更多更好的性能体验
Why choose Mysql?
-
MySQL是开源的,使用成本低
-
性能卓越,服务稳定
-
体积小,使用简单,并且易于维护
-
历史悠久,社区用户活跃,可以在其中寻求帮助
-
经过了时间的验证
Oracle 更适合大型的跨国公司使用,性能更加强大,更加安全:MySQL 体积小,速度快,总体来说是一款有成本低,可处理上万条记录的大型数据库,并且还是开源的.
2. Mysql配置
https://blog.csdn.net/weixin_48152652/article/details/125068472 3
3. MySQL的数据类型
主要包括以下五大类:
整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮点数类型:FLOAT、DOUBLE、DECIMAL
字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期类型:Date、DateTime、TimeStamp、Time、Year
其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
各数据类型及字节长度一览表:
| 数据类型 | 字节长度 | 范围或用法 |
| Bit | 1 | 无符号[0,255],有符号[-128,127],天缘博客备注:BIT和BOOL布尔型都占用1字节 |
| TinyInt | 1 | 整数[0,255] |
| SmallInt | 2 | 无符号[0,65535],有符号[-32768,32767] |
| MediumInt | 3 | 无符号[0,2^24-1],有符号[-2^23,2^23-1]] |
| Int | 4 | 无符号[0,2^32-1],有符号[-2^31,2^31-1] |
| BigInt | 8 | 无符号[0,2^64-1],有符号[-2^63 ,2^63 -1] |
| Float(M,D) | 4 | 单精度浮点数。天缘博客提醒这里的D是精度,如果D<=24则为默认的FLOAT,如果D>24则会自动被转换为DOUBLE型。 |
| Double(M,D) | 8 | 双精度浮点。 |
| Decimal(M,D) | M+1或M+2 | 未打包的浮点数,用法类似于FLOAT和DOUBLE,天缘博客提醒您如果在ASP中使用到Decimal数据类型,直接从数据库读出来的Decimal可能需要先转换成Float或Double类型后再进行运算。 |
| Date | 3 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Date Time | 8 | 以YYYY-MM-DD HH:MM:SS的格式显示,比如:2009-07-19 11:22:30 |
| TimeStamp | 4 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Time | 3 | 以HH:MM:SS的格式显示。比如:11:22:30 |
| Year | 1 | 以YYYY的格式显示。比如:2009 |
| Char(M) | M |
定长字符串。 |
| VarChar(M) | M | 变长字符串,要求M<=255 |
| Binary(M) | M | 类似Char的二进制存储,特点是插入定长不足补0 |
| VarBinary(M) | M | 类似VarChar的变长二进制存储,特点是定长不补0 |
| Tiny Text | Max:255 | 大小写不敏感 |
| Text | Max:64K | 大小写不敏感 |
| Medium Text | Max:16M | 大小写不敏感 |
| Long Text | Max:4G | 大小写不敏感 |
| TinyBlob | Max:255 | 大小写敏感 |
| Blob | Max:64K | 大小写敏感 |
| MediumBlob | Max:16M | 大小写敏感 |
| LongBlob | Max:4G | 大小写敏感 |
| Enum | 1或2 | 最大可达65535个不同的枚举值 |
| Set | 可达8 | 最大可达64个不同的值 |
使用建议
1、在指定数据类型的时候一般是采用从小原则,比如能用TINY INT的最好就不用INT,能用FLOAT类型的就不用DOUBLE类型,这样会对MYSQL在运行效率上提高很大,尤其是大数据量测试条件下。
2、不需要把数据表设计的太过复杂,功能模块上区分或许对于后期的维护更为方便,慎重出现大杂烩数据表
3、数据表和字段的起名字也是一门学问
4、设计数据表结构之前请先想象一下是你的房间,或许结果会更加合理、高效
5、数据库的最后设计结果一定是效率和可扩展性的折中,偏向任何一方都是欠妥的
4. MySQL分库分表
https://blog.csdn.net/qq_53267860/article/details/125121030
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
1.IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
2.CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组成的拆分策略最终如下:
垂直拆分(强调库和表不一样,数据不一样)、水平拆分(强调库和表一样,数据不一样)
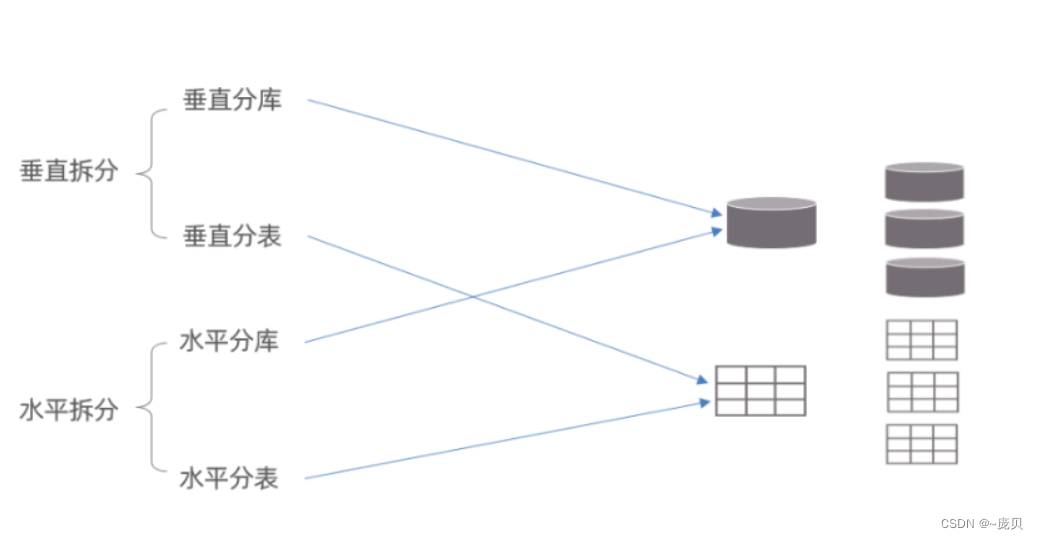
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分
库,还是分表,都需要根据具体的业务需求具体分析。
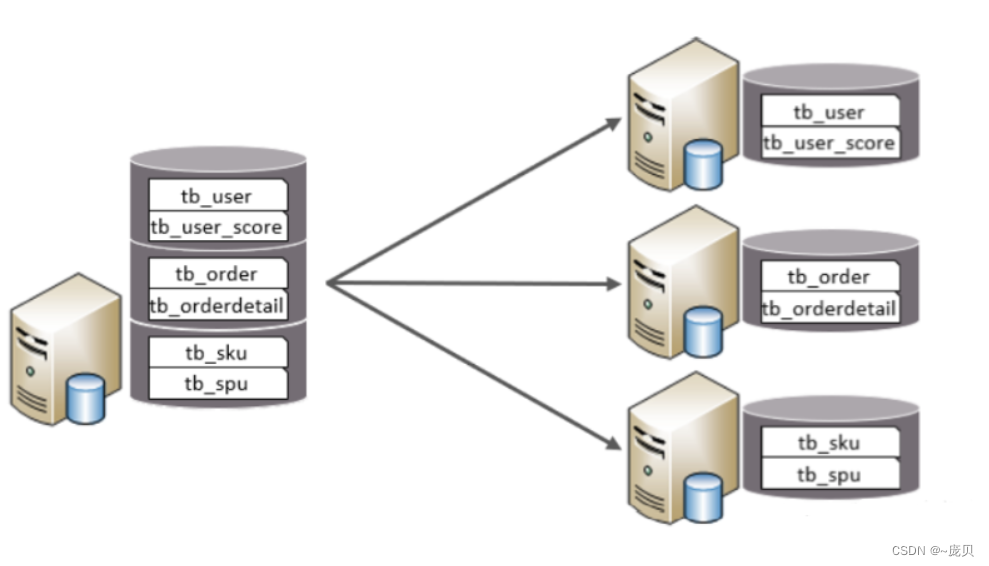
4.1 垂直分库
垂直分库:以表为依据,根据业务将不同表拆分到不同库中(库和数据都不一样,比如user一个库,order一个库)
特点:
1.每个库的表结构都不一样。
2.每个库的数据也不一样。
3.所有库的并集是全量数据
4.2 垂直分表
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中(一个表按字段拆分和数据都不一样,比如order表,拆成两个order表不同的字段)
特点:
1.每个表的结构都不一样。
2.每个表的数据也不一样,一般通过一列(主键/外键)关联。
3.所有表的并集是全量数据。
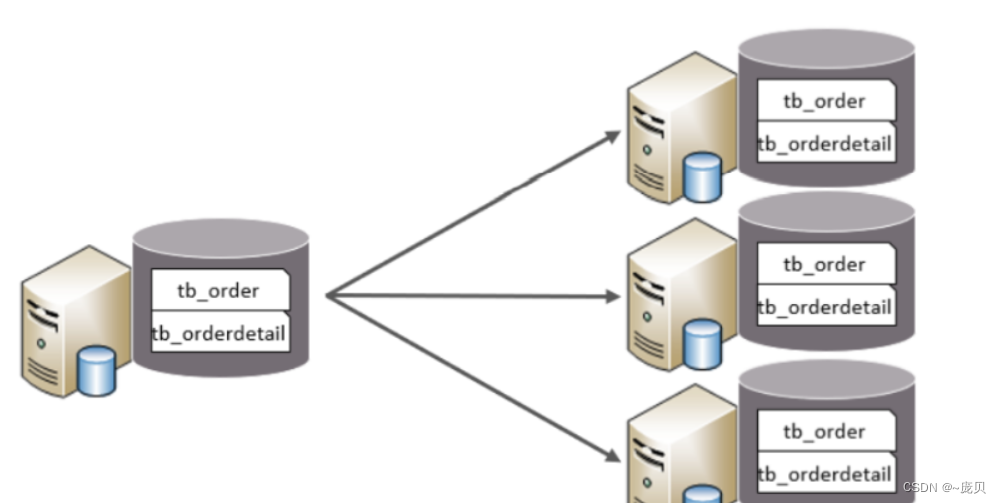
4.3 水平分库
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中(两个库表结构一样,数据不一样)
特点:
1.每个库的表结构都一样。
2.每个库的数据都不一样。
3.所有库的并集是全量数据
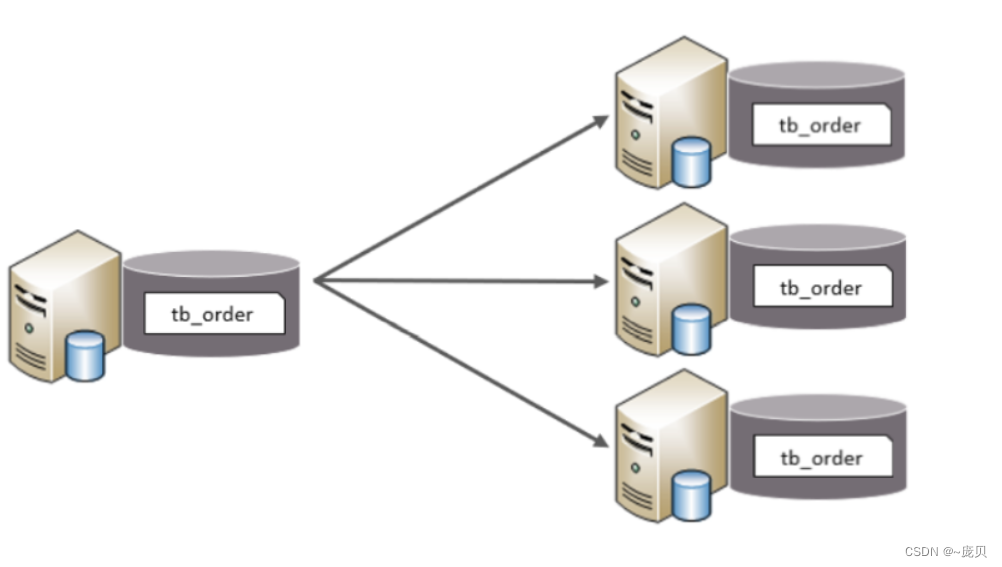
4.4 水平分表
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中(表结构一样,数据不一样)
特点:
1.每个表的表结构都一样。
2.每个表的数据都不一样。
3.所有表的并集是全量数据。
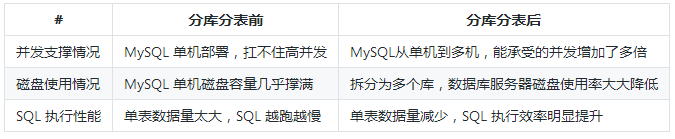
5 分库分表原因
分表:
比如你单表都几千万数据了,单表数据量太大,会极大影响你的 sql执行的性能,到了后面 sql 可能就跑的很慢了。一般来说,单表到几百万的时候,性能就会相对差一些了,就得分表了。
分表就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库:
分库就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
这就是所谓的分库分表。
资源
https://blog.csdn.net/weixin_61523879/article/details/125553340
https://blog.csdn.net/weixin_52629592/article/details/124056741