ElasticSearch安装及使用
ELK由Elasticsearch、Logstash和Kibana三部分组件组成。
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用。
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
本文将用本地安装模式安装集群, 如果有条件,请使用云平台如AWS上的服务。
我的环境是Ubuntu16.04, 并且安装了Java环境, ElasticSearch是由Java开发的哦。
一.安装ElasticSearch
1.1 单机运行
从官网下载tar包:
# 解压
tar -zxvf elasticsearch-6.1.0.tar.gz
# 新建文件夹
mkdir -p $HOME/escluster
# 移动到我们的新文件夹中
mv elasticsearch-6.1.0 $HOME/escluster/es1
# 尝试单机运行
cd $HOME/escluster/es1
./bin/elasticsearch -V
./bin/elasticsearch
打开http://127.0.0.1:9200 可以观察是否成功.
测试:
curl -XPUT 'http://localhost:9200/twitter/doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy",
"post_date": "2009-11-15T13:12:00",
"message": "Trying out Elasticsearch, so far so good?"
}'
curl -XGET 'http://localhost:9200/twitter/doc/1?pretty=true'
1.2 Docker安装老版本
Dockerfile
FROM elasticsearch:2.3
RUN plugin install mobz/elasticsearch-head
EXPOSE 9200
EXPOSE 9300
docker build -t es-me .
docker run -d --name es --restart always -v $PWD/data:/usr/share/elasticsearch/data:rw -p 9200:9200 -p 9300:9300 es-me
打开http://127.0.0.1:9200/_plugin/head/
1.2 Docker安装新版本
Dockerfile:
FROM elasticsearch:5.6
EXPOSE 9200
EXPOSE 9300
docker-compose.yaml
version: '2'
services:
elas:
restart: always
image: elasticsearch:5.5
ports:
- "9200:9200"
- "9300:9300"
volumes:
- "/home/superpika/data:/usr/share/elasticsearch/data:rw"
docker-compose up
现在可以请求127.0.0.1:9200
1.3 集群安装
简单使用请参见上面。
ElasticSearch ELK日志分析。
我们要搭建集群, 因为ElasticSearch是分布式全文搜索引擎。
安装包下有很多目录:
| 目录 | 作用 |
|---|---|
| bin | 主要是各种启动命令 |
| config | 主要存放配置文件 |
| data | 该节点的索引存放目录, 可改 |
| lib | es依赖的一些依赖包 |
| logs | 日志存放目录, 可改 |
| plugins | es强大的插件系统 |
我们在本机装个两个节点的集群.
我们修改elasticsearch.yml来做集群, 相关解释已经在注释中, 部分参考ElasticSearch单机双实例的配置方法.
cd $HOME/escluster/es1
vim config/elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster: 标明了整个集群的名字,只有节点在相同的集群在能互相发现。
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node: 当前节点名称的标识,各个节点的名称不能重复, 切记!
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# 新建文件夹, 将数据和日志定位到$HOME/testes中
# sudo mkdir /app/testes
# 将该文件夹赋予执行ES的用户
# sudo chown superpika testes
# sudo chgrp superpika testes
# 不同节点node的保存路径应该不一样
# mkdir /app/testes/node1
# mkdir /app/testes/node2
# 下面必须写全路径
path.data: /app/testes/node1/data
#
# Path to log files:
#
path.logs: /app/testes/node1/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6): 指定为本机IP, 否则可能导致外部无法访问
#
network.host: 127.0.0.1
#
# Set a custom port for HTTP: 节点间通信端口, 节点在不同机器可以一样, 但单机模拟集群, 不能一样
#
http.port: 9200
transport.tcp.port: 9300
# 本地集群必须设置, 切记!!!
# 这个配置限制了单节点上可以开启的ES存储实例的个数,我们需要开多个实例,因此需要把这个配置写到配置文件中,并为这个配置赋值为2或者更高。
node.max_local_storage_nodes: 2
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# 由于到了2.x版本之后,ES取消了默认的广播模式来发现master节点,需要使用该配置来指定发现master节点。这个配置在单机双实例的配置中需要特别注意下,因为习惯上我们配置时并未指定master节点的tcp端口,如果实例的transport.tcp.port配置为9301,那么实例启动后会认为discovery.zen.ping.unicast.hosts中指定的主机tcp端口也是9301,可能导致这些节点无法找到master节点。因此在该配置中需要指定master节点提供服务的tcp端口。
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301"]
# es配置当前集群中最少的主节点数,对于多于两个节点的集群环境,建议配置大于1。我们的节点目前没有多于两个, 所以不设置
# discovery.zen.minimum_master_nodes: 2
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes:
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
我们再拷贝一份:
cp -r $HOME/escluster/es1 $HOME/escluster/es2
将另一份的配置改为:
path.data: /app/testes/node1/data改为path.data: /app/testes/node2/data,
path.logs: /app/testes/node1/logs改为path.logs: /app/testes/node2/logs,
node.name: node-1改为node.name: node-2,
http.port: 9200改为http.port: 9201,
transport.tcp.port: 9300改为transport.tcp.port: 9301
跑起来(跑起来后关掉一个再连, 集群还会保持):
$HOME/escluster/es1/bin/elasticsearch -d
$HOME/escluster/es2/bin/elasticsearch -d
访问: http://127.0.0.1:9200和http://127.0.0.1:9201
GET 127.0.0.1:9200/_cluster/health
PS: 也可以不复制整个安装包成两份, 只需复制两份配置, 然后更改配置, 运行:
$HOME/escluster/es1/bin/elasticsearch -Des.path.conf=config/instance1 -d -p /tmp/elasticsearch_1.pid
$HOME/escluster/es1/bin/elasticsearch -Des.path.conf=config/instance2 -d -p /tmp/elasticsearch_2.pid
更多参考: ElasticSearch源码地址
1.4 脑裂问题
参考: http://blog.csdn.net/cnweike/article/details/39083089
正常情况下,集群中的所有的节点,应该对集群中master的选择是一致的,这样获得的状态信息也应该是一致的,不一致的状态信息,说明不同的节点对master节点的选择出现了异常——也就是所谓的脑裂问题。这样的脑裂状态直接让节点失去了集群的正确状态,导致集群不能正常工作。
可能导致的原因:
- 网络:由于是内网通信,网络通信问题造成某些节点认为master死掉,而另选master的可能性较小;进而检查Ganglia集群监控,也没有发现异常的内网流量,故此原因可以排除。
- 节点负载:由于master节点与data节点都是混合在一起的,所以当工作节点的负载较大(确实也较大)时,导致对应的ES实例停止响应,而这台服务器如果正充当着master节点的身份,那么一部分节点就会认为这个master节点失效了,故重新选举新的节点,这时就出现了脑裂;同时由于data节点上ES进程占用的内存较大,较大规模的内存回收操作也能造成ES进程失去响应。所以,这个原因的可能性应该是最大的。
应对问题的办法:
1.对应于上面的分析,推测出原因应该是由于节点负载导致了master进程停止响应,继而导致了部分节点对于master的选择出现了分歧。为此,一个直观的解决方案便是将master节点与data节点分离。为此,我们添加了三台服务器进入ES集群,不过它们的角色只是master节点,不担任存储和搜索的角色,故它们是相对轻量级的进程。可以通过以下配置来限制其角色:
node.master: true
node.data: false
当然,其它的节点就不能再担任master了,把上面的配置反过来即可。这样就做到了将master节点与data节点分离。当然,为了使新加入的节点快速确定master位置,可以将data节点的默认的master发现方式由multicast修改为unicast, 这两种是ES的默认自动发现(Disovery):
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["master1", "master2", "master3"]
2.还有两个直观的参数可以减缓脑裂问题的出现:
discovery.zen.ping_timeout(默认值是3秒):默认情况下,一个节点会认为,如果master节点在3秒之内没有应答,那么这个节点就是死掉了,而增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。
discovery.zen.minimum_master_nodes(默认是1):这个参数控制的是,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量(我们的情况是3,因此这个参数设置为2,但对于只有2个节点的情况,设置为2就有些问题了,一个节点DOWN掉后,你肯定连不上2台服务器了,这点需要注意)
二.安装Kibana
从官网下载tar包.
解压并修改配置
tar -zxvf kibana-6.1.0-linux-x86_64.tar.gz
cd kibana-6.1.0-linux-x86_64
vim config/kibana.yml
elasticsearch.url: "http://127.0.0.1:9200"
运行:
bin/kibana
# 后台运行
nohup bin/kibana &
打开: http://127.0.0.1:5601 即可.
三.使用Logstash
Logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
这里是全文重点.
3.1 安装
从官网下载tar包.
tar -zxvf logstash-6.1.0.tar.gz
cd logstash-6.1.0
3.2 运行
定义一个简单的示例日志收集处理配置logstash.conf:
input { stdin { } }
output {
elasticsearch { hosts => ["127.0.0.1:9200"] }
stdout { codec => rubydebug }
}
这里input从标准输入stdin接收日志, output将日志输出到elasticsearch, stdout.codecs是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括 json,msgpack,plain(text)。
开始跑:
bin/logstash -f logstash.conf
> 随便打
打开kibana来分析: http://127.0.0.1:5601/app/kibana#/management/kibana/index?_g=()
接着可以打开Discover进行日志查看:
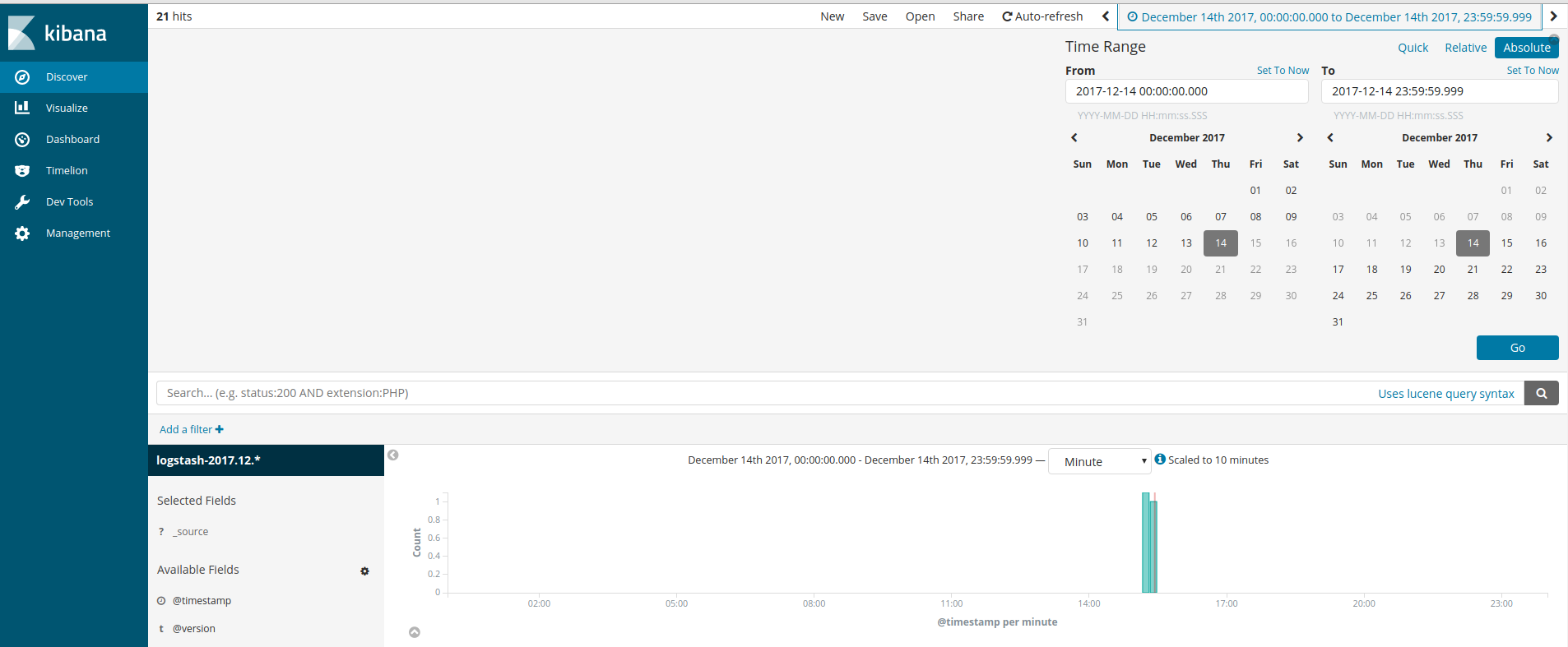
也可以进Visualize进行Create a visualization操作:

四. 笔记
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
为了创建员工目录,我们将进行如下操作:
为每个员工的文档(document)建立索引,每个文档包含了相应员工的所有信息。
每个文档的类型为employee。
employee类型归属于索引megacorp。
megacorp索引存储在Elasticsearch集群中。
实际上这些都是很容易的(尽管看起来有许多步骤)。我们能通过一个命令执行完成的操作(参见ES权威指南):
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
GET /megacorp/employee/1
HEAD /megacorp/employee/1
GET /megacorp/employee/_search
GET /_cluster/health
在Elasticsearch中,每一个字段的数据都是默认被索引的。也就是说,每个字段专门有一个反向索引用于快速检索。而且,与其它数据库不同,它可以在同一个查询中利用所有的这些反向索引,以惊人的速度返回结果。
文档在Elasticsearch中是不可变的——我们不能修改他们。
在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档。旧版本文档不会立即消失,但你也不能去访问它。Elasticsearch会在你继续索引更多数据时清理被删除的文档。
update API。这个API似乎允许你修改文档的局部,但事实上Elasticsearch遵循与之前所说完全相同的过程,这个过程如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
当使用 index API更新文档的时候,我们读取原始文档,做修改,然后将整个文档(wholedocument)一次性重新索引。最近的索引请求会生效——Elasticsearch中只存储最后被索引的任何文档。如果其他人同时也修改了这个文档,他们的修改将会丢失。
比如:
一天,老板决定做一个促销。瞬间,我们每秒就销售了几个商品。想象两个同时运行的web进程,两者同时处理一件商品的订单.
web_1让stock_count 失效是因为web_2没有察觉到stock_count 的拷贝已经过期(译者注: web_1取数据,减一后更新了stock_count。可惜在web_1更新stock_count前它就拿到了数据,这个数据已经是过期的了,当web_2再回来更新stock_count时这个数字就是错的。这样就会造成看似卖了一件东西,其实是卖了两件,这个应该属于幻读。)。结果是我们认为自己确实还有更多的商品,最终顾客会因为销售给他们没有的东西而失望。
变化越是频繁,或读取和更新间的时间越长,越容易丢失我们的更改。在数据库中,有两种通用的方法确保在并发更新时修改不丢失:
悲观并发控制(Pessimistic concurrency control)
这在关系型数据库中被广泛的使用,假设冲突的更改经常发生,为了解决冲突我们把访问区块化。典型的例子是在读一行数据前锁定这行,然后确保只有加锁的那个线程可以修改这行数据。
乐观并发控制(Optimistic concurrency control):
被Elasticsearch使用,假设冲突不经常发生,也不区块化访问,然而,如果在读写过程中数据发生了变化,更新操作将失败。这时候由程序决定在失败后如何解决冲突。实际情况中,可以重新尝试更新,刷新数据(重新读取)或者直接反馈给用户。
Elasticsearch是分布式的。当文档被创建、更新或删除,文档的新版本会被复制到集群的其它节点。Elasticsearch即是同步的又是异步的,意思是这些复制请求都是平行发送的,并无序(out of sequence)的到达目的地。这就需要一种方法确保老版本的文档永远不会覆盖新的版本。上文我们提到index/get/delete 请求时,我们指出每个文档都有一个version号码,这个号码在文档被改变时加一。Elasticsearch使用这个 _version保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
409冲突:
PUT /website/blog/1?version=1
更多查看https://www.gitbook.com/book/looly/elasticsearch-the-definitive-guide-cn