Centos7安装Elasticsearch和Kibana
搜索引擎基础---分词和倒排索引简述
此前的es和kibana安装
Elasticsearch是什么?
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索,基于RESTful web接口。也就说它就是一个索引库,用来存储上面分词之后创建的索引的,对外提供检索服服务,http协议。对内就是一个nosql数据库。
资料:
基于es2.x版本的,核心的东西还是可以看看,中文的:
https://www.elastic.co/guide/cn/elasticsearch/guide/cn/index.html
Es6.x API:
ES分布式索引介绍
number_of_shards:分片数量,类似于数据库里面分库分表,一经定义不可更改。为什么不能修改呢,它不像redis的集群,添加或者减少主从时,集群会重新分配slots。所以如果修改分片数量,会导致取模之后可能找不数据了,比如原来3个,4%3=1,现在变成4个分片4%4=0了。
number_of_replicas:副本数,用于备份分片的,小于分片数。和主分片里面的数据保持一致,主要响应读操作,副本越多读取就越快。副本会在另外的分片上面去存放。比如分片数量3,副本数2,数据1 hash之后落在分片1,那么会在分片2和分片3上面去放副本。
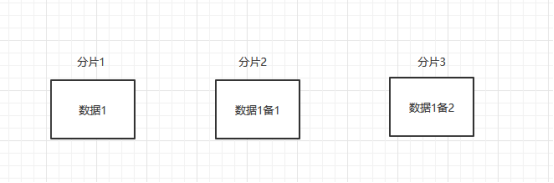
如果副本数设置1,那么分片2和3就只会有一个区备份。
它的写操作是需要副本数过半成功才成功的。
Es基础语法:
首先我们先安装一个中文分词的插件。安装和自己es对应版本的:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
安装好了需要重启才会生效
Es的基础操作(kibana中)
打开kibana—>dev tools,控制台可以执行操作
Management—>Index Management 可以看到我们创建好的索引
索引创建及设值
1.创建索引:
我的是单机,所以分片设置的1,备份0
PUT /test { "settings":{ "number_of_shards": 1, "number_of_replicas": 0 } }
2.创建索引,指定id建立索引
PUT /test/_doc/1 { "name": "张三", "age": 30 }
3.不设置id会默认生成一个,指定ID是PUT
POST /test/_doc { "name": "张三默认", "age": 30 }
4.全量修改值。Id为1的数据全覆盖
PUT /test/_doc/1 { "name": "张三1", }
5.部分修改,只会修改对应的字段
POST /test/_doc/1/_update { "doc":{ "name":"张三00" } }
6.指定_create防止重复创建,如果已经存在则失败,第二次会报错
POST /test/_doc/2/_create { "name":"李四", "age":20 }
删除:
指定ID删除文档
DELETE /test/_doc/1
{
}
删除索引
DELETE /test
{
}
查看分词结果,默认使用的stander分词器是每个词都分开
GET /test/_analyze { "field": "name", "text": "成都市天府广场" }

结构化索引创建:可以指定一些约束,比如分词器,字段类型之类的
stander: 每个词都分开
english: 英文分词器,会按照英文的语法来处理一些词比如eating,eated 都会被处理成eat
ik_max_word: 中文分词器,最大拆分,能分出来的词都分出来
“武汉市长江大桥”->武汉,武汉市,市长,长江,大桥,长江大桥,江大桥
ik_smart: 中文分词器,尽可能分词长的
“武汉市长江大桥”->武汉市,长江大桥
ik_max_word和ik_smart 需要装中文分词器插件
name字段分词使用ik_max_word,查询时使用ik_smart
enname 分词查询都是用english
PUT /test2 { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "_doc":{ "properties": { "name":{"type":"text","analyzer":"ik_max_word","search_analyzer": "ik_smart"}, "sname":{"type": "text","analyzer":"ik_smart"}, "enname":{"type":"text","analyzer":"english"}, "age":{"type": "integer"} } } } }
现在我们看test2的sname字段的分词结果:sname使用的中文分词ik_smart
GET /test2/_analyze { "field": "sname", "text": "成都市天府广场" }
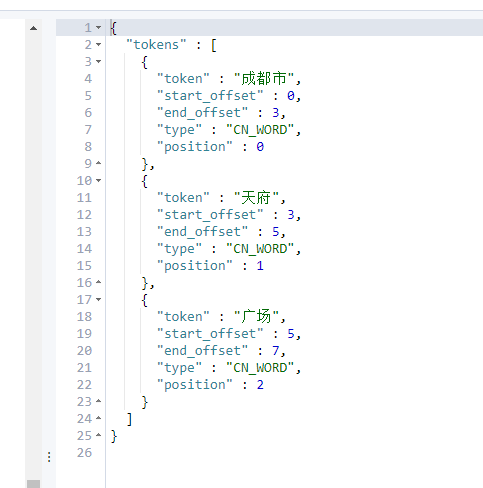
我们再看下对于test2的name字段使用的是ik_max_word
GET /test2/_analyze { "field": "name", "text": "成都市天府广场" }

可以看到对于同样的文本,使用不同的分词方式,出来的结果是不一样。
查询:
1.根据id查询
GET /testtest/_doc/1
{
}
2.查询索引所有,query加不加都可以
GET /test/_search { "query":{ "match_all": {} } }
3.按条件查询,并分页,注意分页不能太多,因为es的分页都是在内存中做的,太多了会撑爆内存
GET /test/_search { "query": { "match": { "name": "张三" } }, "from": 0, "size": 20 }
可以看下淘宝的搜索也是限制了的一页40个,最多100页
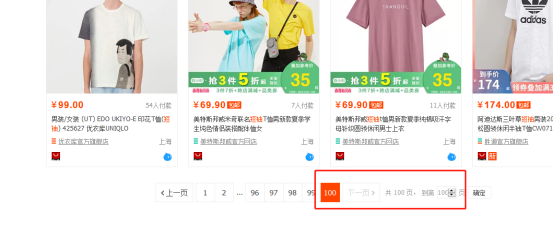
4.排序
GET /test/_search { "query": { "match": { "name": "张三" } }, "sort": [ { "age": { "order": "desc" } } ], "from": 0, "size": 20 }
更多API操作见文档: