序
工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效。所以想写点东西,记录一下,如果能对别人有所帮助,善莫大焉。
说一下我的工作,在一个项目里我们在Flink-SQL基础上构建了一个SQL Engine, 使懂SQL非技术人员能够使用SQL代替程序员直接实现Application, 然后在此基础上在加上一些拖拽的界面,使不懂SQL非技术人员 利用拖拽实现批量或流式数据处理的Application 。 公司的数据源多样且庞大,发布渠道也很丰富, 我们在SQL Engine 里实现了各种各样的Table Source (数据源) , Table Sink (数据发布)和 UDF (计算器), 公司里有很多十分懂业务专业分析员,如果他们真的可以简简单单,托托拽拽的操作大数据,建立计算模型,然后快速上线和发布,这样的产品应该前景广阔。
可是后台并非说起来这么简单,SQL使用不善,难以达到业务想要的效果,数据量一上来各种问题会出现,后端需要大量的优化工作, 比如 数据倾斜, 是最常发生的事情。SQL基本上是一个Join Language。用户经常会将一个大数据源和一个小数据源做Inner Join, 如果大数据源的数据项很大部分都使用极少数的几个join key, 就很容易出现数据倾斜。现实倾斜的或不均衡的,比如国际资本>80%以用美元计价,世界人口50%属于某两个国家, 财富主要有20%的人拥有, 等等 。 Flink 如果把SQL join 执行成Hash Join, 最后的结果是无论你实现分配了多少个TaskSlots, 如果80%的数据都跑到某一个TaskSlot里,缓慢运行直至将个这Slot的资源耗尽,整个job失败。这种情况最好是将小数据集广播给所有的下游通道, 大数据集按原始的分片并行,这样的join因分配均衡而快速。然而标准SQL里没有办法指定joinhint , Flink sql也不支持这个,只能通过debug flink 来看看哪里能做一些改变解决这个问题。我们在最后一章,从Flink client , flink optimizer, flink run-time (job manager, task manager) 一步一步的 在源码里设置断点, debug, 将数据流过一遍,看看有哪些方案可以将这个小数据集合广播起来。
为了使本文读起来流畅一些, 我先通过几个章节大概介绍一下Flink 。本文关心架构, 所以不会涉及很多关于API的东西(比如Flink streaming 的windowing, watermark, Dataset, DataStream, 及SQL的API等, 网上应该有很多关于这些的文章)。只是想大概梳理一个Flink的架构,使架构对应到源码结构里, 了解一下Flink的 Graph metadata, 高可靠性的设计,不同cluster环境里 depoloyment的实现等, 最后利用IntelliJ IDEA 通過一個小例子带大家debug一下Flink 。如果对flink的架构有较好的理解(比如主要类及metadata),就比较容易在准确的地方设置断点,debug Flink代码将更有效率,从而解决问题就会更有效率, 这就是本文的目的。大概了解一下框架,但并不会面面俱到。当如果你需要深入了解一下Flink某方面的细节, 本文能够告诉你入口在哪里,或者通过对架构了解过程中得到的common sense , 再加上一点想象力, 你或许直接能够得到解决问题的方案, 然后再通过阅读源码及调试来加以验证。
1. Flink的架构简介
1.1 Flink 分布式运行环境(官方图)
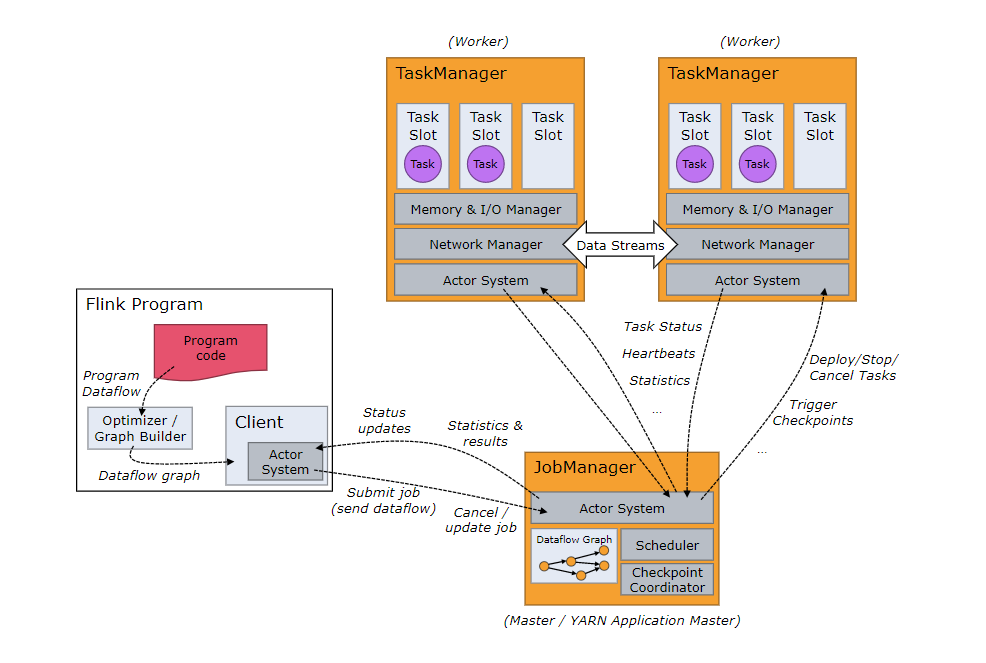
(图-1 Flink Runtime 来自:https://ci.apache.org/projects/flink/flink-docs-release-1.6/concepts/runtime.html)
关于架构,先上一个官方的图,尽管对于Flink架构,上图不是很准确(比如client与JobManager的通讯已经改为REST 方式, 而非AKKA的actor system),我们还是可以知道一些要点:
- FlinkCluster: Flink的分布式运行环境是由一个(起作用的)JobManager 和多个TaskManager组成。每一个JobManager(JM)或TaskManager(TM)都运行在一个独立的JVM里,他们之间通过AKKA的Actor system (建立的RPC service)通讯。所有的TaskManager 都有JobManager管理,Flink distributed runtime实际上是一个没有硬件资源管理 的软件集群 ( FlinkCluster ), JM是这个FlinkCluster 的master, TM是worker。 所以将Flink运行在真正的cluster 环境里(能够动态分配硬件资源的cluster,比如Yarn, Mesos, kubernetes), 只需要将JM 和 TM运行在这些集群资源管理器分配的容器里,配置网络环境和集群服务使AKKA能工作起来, Flink cluster 看起来就可以工作了。具体的关于怎么将Flink 部署到不同的环境, 之后有介绍, 虽然没有上面说的这么简单,还有一些额外的工作, 不过大概就是这样:因为Flink runtime 自身已经通过AKKA的 sharding cluster建立了FlinkCluster, 部署到外围的集群管理只是为了获取硬件资源服务。 Flink不是搭建在零基础上的框架,任何功能都要自己重新孵化,实际上它使用了大量的优秀的开源框架, 比如用AKKA实现软件集群及远程方法调用服务(RPC), 用ZooKeeper提高JM的高可用性, 用HDFS,S3, RocksDB 永久存储数据, 用 Yarn/Mesos/Kubernetes做容器资管理, 用Netty 做高速数据流传输等等。
- JobManager: JobManager 作为FlinkCluster的manager,它是由一些Services 组成的,有的service 接受从flink client端 提交的Dataflow Graph(JobGraph),并将JobGraph schedule 到TaskManager里运行,有的Service 协调做每个operator 的checkpoint以备job graph运行失败后及时恢复到失败前的现场从而继续运行 , 有的Service负责资源管理, 有的service 负责高可用性,后面在详细介绍。值得一提的是,集群里有且只有一个工作的JM, 它会对每一个job实例化一个Job
- TaskManager : TaskManager是slot 的提供者和sub task的执行者。通常Flink Cluster里会有多个TM, 每个TM都拥有能够同时运行多个SubTask的限额,Flink称之为TaskSlot。当TM启动后, TM 将slot限额注册到Cluster里的JM的ResourceManager(RM), RM知道从而Cluster中的slot 总量,并要求TM将一定数量的slot 提供给JM,从而JM 可以将Dataflow Graph的task(sub task)分配给TM 去执行。TM是运行并行子任务(sub Task) 的载体 (一个Job workflow 需要分解成很多task, 每一个task 分解成一个过多个并行子任务:sub Task) , TM需要把这些sub task在自己的进程空间里运行起来, 而且负责传递他们之间的输入输出数据, 这些数据 包括是本地task的和运行在另一个TM里的远程Task 。关于如何具体excute Tasks, 和交换数据 后面介绍。
- Client:Client端(Flink Program)通过invoke 用户jar文件 (flink run 中提供的 jar file)的里main函数 (注册data source, apply operators, 注册data sink, apply data sink),从而在ExecutionEnvironment或StreamingExecutionEnvironment里建立sink operator 为根的一个或多个FlinkPlan(以sink为根, source 为叶子, 其他operator为中间节点的树状结构), 之后client用Flink-Optimizer将Plan优化成OptimimizedPlan(根据Cost estimator计算出来的cost 优化operator在树中的原始顺序, 同时加入了Operator与Operator连接的边 , 并根据规则设置每个边的shipingStrategy, 实际上OptimizedPlan已经从一个树结构转换成一个图结构), 之后使用GraphGenerator(或StreamingGraphGenerator)将OptimizedPlan转化成JobGraph提交给JobManager, 这个提交是通过JM的DispatcherRestEndPoint提交的。
- Communication: JobManager 与Taskanager都是AKKA cluster里的注册的actor, 他们之间很容易通过AKKA(实现的RPCService)通讯。 client与JobManager在以前(Version 1.4及以前)也是通过AKKA(实现的RPCService)通讯的,但Version1.5及以后版本的JobManager里引入DispatcherRestEndPoint (目的是使Client请求可以在穿过Firewall ?),从此client端与JobManager提供的REST EndPoint通讯。Task与Task之间的数据(data stream records)(比如一个reduce task的input来自与graph上前一个map, output 给graph上的另一个map), 如果这两个Task运行在不同的TM上,数据是通过由TM上的channel manager 管理的tcp channels传递的。
1.2 JobManager
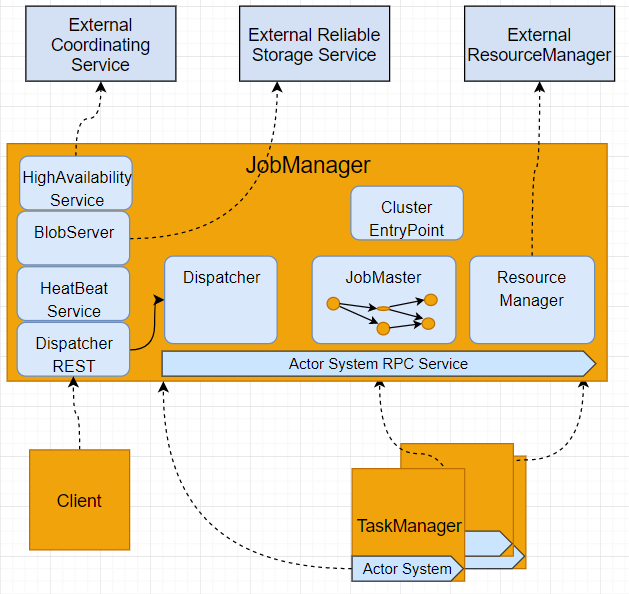
(图-2,JobManager的内部结构)
如上一章所述, JobManager 是一个单独的进程(JVM), 它是一个Flink Cluster的 master 、中心和大脑, 他由一堆services 组成(主要是Dispather, JobMaster 和ResourceManager),连接cluster里其他分布式组件 (TaskManager, client及其他外部组件),指挥、获得协助、或提供服务。
- ClusuterEntryPoint是JobManager的入口,它有一个main method ,用来启动HearBeatService, HA Sercie, BlobServer, Dispather RESTEndPoint, Dispather, ResourceManager 。不同的FlinkCluster有不同的ClusuterEntryPoint 的子类,用于启动这些Service在不同Cluster里的不同实现类或子类。Flink目前(version1.6.1)实现的FlinkCluster 包括:
- MiniCluster : JM和TM都运行在同一个JVM里,主要用于在 IDE (IntelliJ或Eclipse)调试 Flink Program (也叫做 application )。
- Standalone cluster : 不连接External Service (上图中灰色组件,如HA,Distributed storage, hardware Resoruce manager), JM和TM运行在不同的JVM里。 Flink release 中start-cluster.sh启动的就是StandaloneCluster.
- YarnCluster : Yarn管理的FlinkCluster, JM的ResourceManager连接Yarn的ResourceManager创建容器运行TaskManager。BlobServer, HAService 连接外部服务,使JM更可靠。
- MesosCluster : Mesos管理的FlinkCluster, JM的ResourceManager连接Mesos的ResourceManager创建容器运行TaskManager。BlobServer, HAService 连接外部服务,使JM更可靠。
- HighAvailabilityService:重复之前的话:JM是一个Flink Cluster的 master 、中心和大脑, 如果JM崩溃了,整个cluster就无法运行了。HAService能够使多个JobManager同时运行,并选举一个JM作为Leader, 当Leader失败后在重新选举,使另个健康的JM取而代之成为leader, 从HA存储中读取MetaData(Graph,snapshot)从而 继续管理Cluster的运行。HighAvailabilityService 只保护JM里的DispatcherRestEndpoint, Dispatcher, ResourceManager 和JobMaster 4个核心服务, 从理论上来讲, 这些service的各自的leader有可能来自不同的JM, 这就要看外部做Coordination的服务的Leader Election策略会不会把他们都从一个JM 选了。目前,Flink支持的和在使用的HighAvailbilityService有ZooKeeperHaService和StandaloneHaService。
- ZooKeeperHaService:连接外部的ZooKeeper cluster做多个JM的Leader Election,从指定的存储(通常是HDFS)存取JM metadata, 从而当JM takeover 或重新启动时能够获取失败之前的snapshot or savepoint, 从而继续服务。
- StandaloneHaService : 不支持多个JM Election。但支持从指定的存储存取JM metadata, 做失败后重启恢复。
- BlobServer 使用来存储Client端提交的Flink program jar, jobGraph file, JM 的所有services , 和所有的TM都连接同一个BlobServer (可以是LocalDisk, HDFS, S3 , 或其他的 Blob数据库)读取这些数据。
- HeatBeatService , 用来运行JM 与TaskManager之间的心跳服务。 比如 ResourceManager 与JobMaster和所有TaskManager之间的心跳, JobMaster与所有TaskManager之间的心跳。如果心跳消失, 相应的HA 容错措施就要启动。 比如一个TM与JM的心跳没了,那么相应的容错措施就会执行了。比如JobMaster的心跳消失,HA就会重新选举新的JobMaster Leader;TM的心跳消失,ResourceManager就要将task分配到其他空闲的TM的slot里,如果没有空闲的slot ,RM 就会向外部的ResoureManager申请新硬件和启动新的 TM以提供空闲的 slot。Flink的心跳消息是通过AKKA 传递的。
- DispatcherRESTEndPoint是JM的4大核心服务之一(其他三个分别为Dispatcher, JobMaster和ResourceManager),受HAService的保护, 是Flink客户端与JM交互的REST接口, 也是Flink custer 的WebMonitor。非核心服务实际上都是一些UtilityService, 他们非JM独有,需要用时可随时实例化:比如Client端也会使用HAService来获取DispatcherRESTEndPoint的leader的地址和端口, TM也会使用BlobServer 。DispatcherRESTEndPoint是用Netty搭建的RESTService, 它创建了大概有290个handler 对应不容的资源地址及方法。这些handler大都需要通过RPC方式调用Dispatcher 的远程方法来满足客户的请求。
- Diaptcher是DispatcherRESTEndPoint的后端服务层,它实现了RestDispatcher接口, 从客户端(包括FlinkClient和Flink Web Dashboard)提交给又有来自于EndPoint的请求,都由这个接口里的方法服务, 这其中最总要的方法就是submitJob。当Dispather受到submitJob的调用时,他会先在本JVM里创建一个JobMaster服务,并将 JobGraph和Flink applicaiton 的jar file , 转交给这个JobMaster去安排job具体的运行。
- JobMaster的是用于一个Job的Master, 当集群里由多个Job同时运行则会有多个JobMaster同时运行,每一个JobMaster只会负责一个job。当接收到jobGraph时, JobMaster首先会将jobGraph转换成ExecutionGraph:一个可以指导task并行运行的数据流程图,并向ResouceManager(RM)申请运行这个ExecutionGaph需要的资源(TaskSlot):比如一个并行度为8的job,必须有8个TaskSlot才能运行起来, 然后按照ExecutionGraph将task schedle到Taskslot中去, 并定时的对task做checkpoint, 以备重启时恢复到崩溃前的现场。
- ResourceManager负责管理FlinkCluster里所有TaskManager的TaskSlot资源(相当于TM里的一个运行线程)。当一个TM启动时,它会将自己的TaskSlot注册到RM。当JobMaster向RM申请slot时,RM会要求TM将它空闲的slot(已注册到RM,所以TM知道所有slot的状态)提供给JobMaster使用,之后JobMaster才会将相应的Task 安排到slot里运行。如果集群里的TaskSlot不够, RM会向外部的ResourceManager(比如Yarn/Mesos/Hubernetes)申请新的容器(container) 去启动新的TM从而满足JobMaster的slot资源的需求。
1.2.1 展开JobManager后的Flink架构
从以上所述, JobManager是一组Service的总称, 其中真正管理Job调度的组件叫JobMaster ,负责资源管理的组件叫ResoruceManager, 负责接收client端请求的组件叫Dispatcher(包括Dispatcher和DispatchRestEndpoint)。其实Flink源码里有叫JobManager的包和类,功能上也是负责Job调度管理以及snapshot管理,但它应该在Flink某个版本以后就legacy了(估计是从version1.3开始)。这三个服务统称为还叫 JobManager,上真正管理作业的是JobMaster。这一点在读code时让人迷惑,比如JobManagerRunner启动的却是叫JobMaster的类。但是他不叫JobMasterRunner,这也体现了JobMaster实际是取代了JobManager类,保留legacy类是为了向后兼容。以下是Client, 展开的JobManger(受HA 保护的Dispather, JobMaster, ResourceManager)和TaskManager处理submitJob的流程图,这个比较图-1更能体现当前的Flink runtime架构 (Flink 1.6):
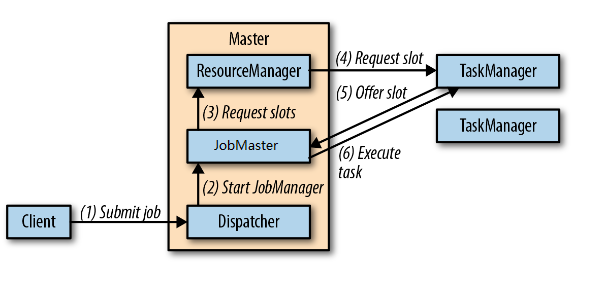
(图-3)展开JobManager后的Flink 架构, 来自于《 Stream Processing with Apache Flink》
以上的架构严格来讲在Flink里被称作 SessionMode ( Cluster的EntryPoint类都是SessionClusterEntryPoint的子类), 如果没有外部命令 terminate cluster, 在这种模式下的FlinkCluster 是Long running 的, 多个job可以同时运行在同一个flinkcluster里。 SessionMode 在Flink的各种部署都是支持的, 包括Standalone, Kubernetes, Yarn, Mesos, 上图其实是StandaloneSessionCluster的流程。 还有一种模式叫做JobMode, 区别就是Job(或application) 的main class 和 jar 和在JobManager 启动时通过的启动参数装载的, 不需要submitJob的过程, job运行完毕, cluster自动终结, 所有资源释放。 在这种模式下, Dispather并不负责处理job的提交, 但其他 Client发给DispathcherRESTEndPoint的请求(比如Query, CancelJob), 还是由Dispatcher处理。
Flink的每一种部署模式(deployment mode)都是既支持Session Mode又支持JobMode的 (或partialy support), 区别如上所述, 但在架构上是一致的。 当有由外部的ResourceManager协助硬件资源分配时,流程略有所有不同, 以 FlinkCluster in Yarn 为例, SessionMode下, 区别只限于多了RM通过Yarn自动启动TM 的过程(4,5)。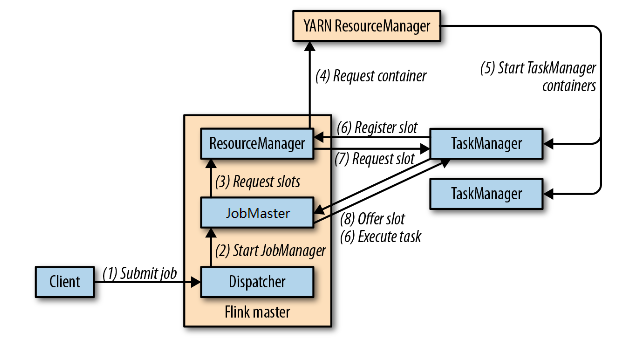
(图-4)FlinkCluster in Yarn Session mode, 来自于《 Stream Processing with Apache Flink》
关于deployment的细节,请参照后面的将Deployment的章节。
1.2.2 JobMaster
如图一所示,JobMaster的主要工作是:
1. JobGraph的scheduler : 将Client提交的JobGraph按照逻辑的向后关系(source -> transform -> sink), 以及并行关系(每个operator的子任务只负责全部数据的中一部分), 将子任务分配到TaskManager的Slot中, 并定期的获取每一个子任务的运行状态 (status)。
2. 触发和管理Job的checkpoint snapshot:对于streaming job,定期的将运行中的每个operator 的状态(State)数据存入规定的存储设备, 这些state数据可以用于在Job恢复运行时,恢复相关子任务的失败前的现场。
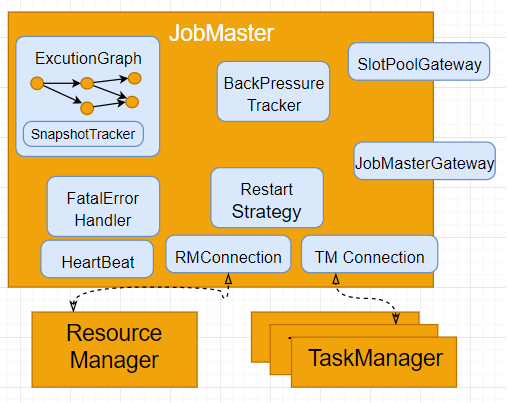
(图-5)JobMaster内部结构
- ExcutionGraph (EG) 是JobMaster 最核心的组件,它承担了JobMaster 上述的的两大责任: job scheduling 和 checkpoint snapshot 。EG的细节下节展开。
- SlotPool 存放由所有TM Offer 过来的slot 。Offer 的过程就是图-3中的3,4,5 或图-4中的3,4,5,6,7,8。当EG需要slot去执行给sub Task时, 它就从SlotPool里根据一定的策略poll 一个slot ,然后将SubTask打包 (这个在TM讲解中展开) 发送相应的TM 去执行 。 SlotPool实现了一个RPCEndPoint : SlotPoolGateway, 如图-5中所示,感觉这个Gatway是为TM OfferSlot准备的。 实际上TM调用的是JobMasterGateway (到JobMaster), 然后JobMaster 通过SlotPoolGateway这个RPC 接口与SlotPool通讯的。 看代码时看到SlotPoolGateway时比较奇怪的, 因为它作为JobMaster的组件,是没有必要实现为PCEndPoint的。集群中运行的每一个Job, 都会由一个JobMaster创建出来为之服务, 每一个JobMaster 都有一个SlotPool存放这个Job分配的Slot 。有一种可能是Slotpool的实现这打算将slotpool共享给所有的的JobMaster ? 如果那样的Slotpool 需要由Zookeepr 管理做Leader Selection 和 FailOver, 其实也没什么必要。
- JobMasterGateway 是外界(ResourceManager, TaskManager)用来 同JobMaster通讯的RPC接口。
- RMConnection 和TMConnection(多个)是JobMaster 同TM 和TM 通讯的PRC 通道。这些通道里包裹了RM和TM的PRCEndPoint的AKKA地址,以及永远RPC call 的 XXXXGateway接口。比如ResourceManagerGateway 和TaskManagerGateay。
- HearbeatManager 会以Interval为(10,000 ms),timeout 为(50,000ms) 向TM和RM发送heartBeat, 如果timeout 发生则相应的ErrorHandling 会出发, 比如重新连接RM,切断timeout的TM 。interval 和 timeout都是可配置的, 前面的两个数值是缺省值。
- FatalErrorHandler : 通常指向ClusterEntryPoint (回顾一下图-2)。JobMaster 在无法连接和注册有效的RM时会触发FatalErrorHandler的onFatalError方法。onFatalError通常会简单记下log, 然后推出JVM 。
- RestartStrategy用于在EG中,但Job失败时,尝试重启Job, RestartStrategy 可以在Flink Java/Scala API种指定 。
- BackPressureTracker, 当一个operator的处理速度小于的上游的下发速度, 数据就会在input buffer 里积压, 当buffer满了的情况, 数据就会无处可放。 Flink将这种情况称作为BackPressure 。Dispatch 会持续的通过JM的BackPressureTracker对每一个TM每个 sub Task做Stack trace(100 stack traces every 50ms , configurable) ,然后用可能有BP的stack trace (比如访问buffer, 访问网络栈等)同total tack trace 的比例决定系统是否有Back Pressure风险 。比如 <10%是OK的, <50%是低危的, >50是高危的。这个比率是可以在Flink WebMonitor的Metrics里看到的。如果是高危的怎么办, 实际上Flink就是把他通过Metrics发了出来,没有做任何handling , 目的是让用户手工在工作流种做相应调整, 比如加速和降速Datasource 的输出速率, 在某个operator 上加cache等。
1.2.3 ExcutionGraph
EG是面向Job 并行运行的图结构,在JobGraph的基础上它加入了对Operator并行执行的子任务,以及子任务的输入输出的描述 。

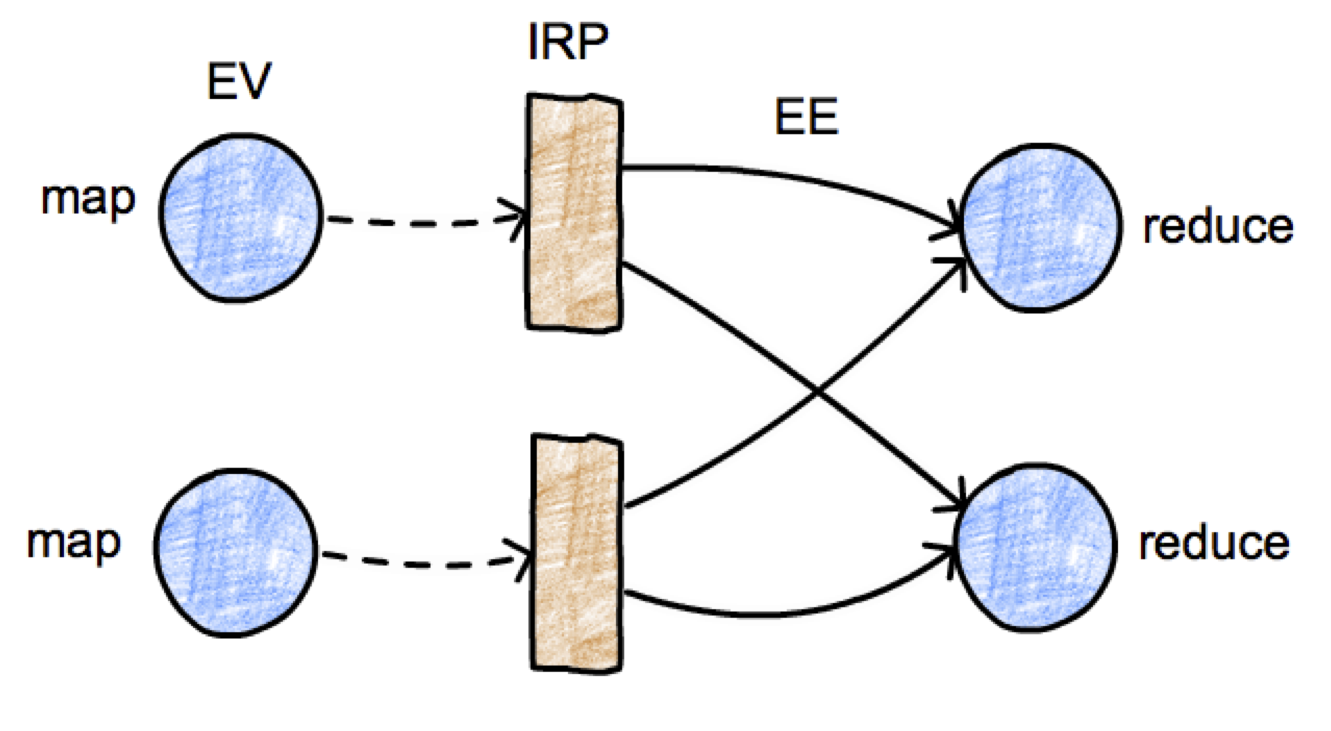
图-6 Execution Graph
- ExecutionJobVertex : 对于每个 Operator 或Task(单独的或chained Opertor) ,EG 都会创建一个ExecutionJobVertex(EJV)对应 。
- ExecutionVertex: 对于它 的每一个并行子任务 (sub task), EVJ都会创建一个ExecutionVertex(EV)对应 。每一个EV都知道输出到哪里 (IntermediateResult), 到哪里获取input (ExecutionEdges : 底层数据也来自IRP ), 和执行的Operator类。
- IntermediateResultPartition(IRP) : 代表IntermediateResult(IR)的一个Partition 。 它描述了它是由哪个EJV提供数据, 并由哪个EE消费数据的。
- ExecutionEdge (EE) : 是每个EV的input的描述, 比如source 来自与哪个partition, edge 是sub task的第几个input 。
-
Execution: 但EV被分配执行时,Exception对象会被创建作为EV的一次尝试, 分配slot, 将EV打包 成 TDD(TaskDeploymentDescriptor)并同TaskManagerGateWay 发送给TM (submitTask) 执行。Exception如果失败, 新的Exception会被创建作为另一次尝试。
- TaskDeploymentDescriptor (TDD): 包括了该Sub Task 所有信息的描述: sub task的执行类 (operator 的类名), 输入和输出的描述, job的描述。 TaskManager收到TDD之后创建一系列物理对象执行的对象,把这些些创建在分散TM上对象拼在一张图上, 实际就形成了EG的物理执行图。 这个TM的章节在展开。
- 总起来说EG通过EJV, EV, IR, IRP, EE构成了一个包含了并行子任务 以及各个子任务间输入输出关系的总工作流图。当scheduling EG的时候, 每个EV都打包成TDD发给TM。TM会将TDD里的子任务,输出Partition和输入Channel创建在TM的物理机上。 把TM的这些物理对象拼接起来,就形成了该工作流物理执行图 。 Dispatcher就是通过收集这些物理对象的metrics和状态信息,从而在WebMonitor上更新EG的。
1.2.3.1 任务分配执行(Scheduler)
EG的Scheduling模式由两种,一个叫Lazy, 一个叫Eager 。
Lazy的方式适用于Batch Job, 它先将所有的处理数据输入的sub task 分配执行, 当TaskManager 返回 (同过JobMasterGateway) 已分配成功的信息, EG在根据EJV的上下游关系, 再给相应的EJV分配slot执行。分配的过程如上一小节所述, EJV所有EV都会通过TDD打包,然后要求SlotPool提供slot, 然后将tdd和slot信息都发送给相应的TM去实例化这个sub task然后运行起来 (再TM细述这个时怎么实现的)。值得一说的是, EJV所有EV都应该一起scheduling , 但当集群里没有足够的slot时, 同一个EJV可能只有部分EV被schedule了,如果那些没有分配的相同EJV的EV再一个timeout(default 5分钟)之后还无法得到slot, task 这时候会失败, job 也会失败。所以在计划Job使用的资源时,计划的总slot数 (比如当使用Yarn管理resource 时, yn * ys 是job向Yarn申请的总slot数 )一定要大于总的source sub task的总数量(source operator 的数量 * paralelism ), 否则部分soure sub task 得不到资源,再timeout之后就会出发failGlobal 使job 失败。
Eager 方式使用与Streaming job, 在Eager模式下, 所有EV都必须都能得到slot, 否则schduling 失败, job 失败。
1.2.3.2 CheckpointCordinator
Flink的Checkpoint这个概念还是有必要简单说明一下, 当然参考Flink文档会得到更全面的理解。Flink主要是一个Stream computation的架构,(当然它也可以做Batch, 但Batch并不是Flink的强项), Flink Streaming processing 的一个特性就是Stated Streaming 。 意思就是在它的流式计算的工作流里, operator的都是可以有状态的。什么是有状态的?相当于一个人睡醒之后还记的自己是谁,然后还能继续下来的生活,做完没有做完的事情的意思 : 因为大脑里存储了过去的信息。Flink 的Operator可以像这样生活的,创建一下StateFull的变量 (比如ValueState<T> ), 然后周期性的将这些状态存储一个地方 ,当job重启, operator 重新实例化的时候, 通过加载这些Sate信息,就能够从新回到上次重启前的状态,然后继续这个operator的人生。周期性的(Periodically)存储operator的State 信息, Flink称作Checkpoint, 每一次存储叫做一次snapshot 。
CheckpointCordinator的主要功能就是协调促使工作流里所有的operator都周期性的触发Checkpoint snapshot 。
换句话说,CheckpointCordinator的主要功能就是向所有的Execution (看前面回顾一下Execution的概念) triggerCheckPoint 。 每一个EG都会创建一个CheckpointCordinator (CC), CC用内建的timer (Executor)定时(根据可配置的interval)的通过RPC向所有的TM触发他们运载的所有Source Exection对应的Task的CheckpointBarrier。 上一句比较长,分解来说, 每一个EG的Execution 都会对应一个Task (准确的说时SubTask)运行在某一个TM 里, triggerCheckPoint 就是CC定时的通过RPC调用所有 TM 上所有的Source Task ( 是工作流里开始位置的处理Source 数据的Task, 不包括Sink Task 也不包括 普通的Transformation Task ) 的triggerCheckpointBarrier方法。当一个SourceTask收到triggerCheckpointBarrier时, 它会命令内嵌的Invokable对象 (Operator, 或Operator Chain的封装对象)执行 performCheckPoint , 这个过程大概有如下几步, 很多多步骤的时异步执行的:
- CC 对所有的Soruce Execution triggerCheckPoint
- TM 对 所有的 SourceTask triggerCheckpointBarrier
- SourceTask对应的Invokable 对象执行performCheckPoint
- 首先 做Barrier 前的工作: 比如对齐和比较多个input channel的barrier 等。
- 其次创建Barrier event (只有source需要创建)并向下游传递 : 下游的Operator 的收到这个Barrier , 也会做这5个步骤 ,只是当有多个input channel的时候(Input), 步骤稍微复杂一些而已。Sink 不需要创建Barrier ,因为没有下游。
- 然后对Invokable对象的所有Sate述,拍Snapshot (克隆一份)
- 然后Invokable 将State数据传递回JobMaster,
- 最后JobMaster再persist 到指定的存储中。
至于CheckPoint怎么配置,State数据, StateBackend 包含那些, 以及CheckpointBarrier再工作流里的联动过程, 我就不赘述了,网上 应该很多介绍, 不过通过代码阅读,想强调如下几点。
- Checkpoint是对Streaming Job有效的, Batch Operator 不需要有状态的。
- Streaming Job 缺省状态不开启Checkpoint, 也不能通过Flink configuration 开启, 只能通过Streaming API 再程序中开启。 缺省状态下, CheckPoint 周期被设置为无穷大,因此永远不会被执行。
- AtLeastOnce只要开启CheckPoint就能达到。
- 对于ExtractlyOnce, 很多网上很多文章都声称这个 Flink的买点。 实际分析一下以上步骤, Checkpoint Snapshot 存储的是上当barrier 到达operator是它的状态, 但并不是Operator 意外退出的状态。所以恢复时,只能恢复到触发barrier 时的现场,这无法保证source的数据无重复下发。
- 下面的文档提供了ExactlyOnce的解决方案,这需要SinkOperator实现
TwoPhaseCommitSinkFunction。https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html。 大概意思时SinkOperator向external 下游发送数据时需要分两步走(TwoPhase), 不过目前没目前 Flink1.6.1 的 Sink都没有实现这个功能 。
- 数据先暂存到临时存储里, 比如存储在临时文件或buffer里 ,这个叫PreCommit .
- 当所有的非Sink operator 都做完了CheckPoint , 当barrier 到达时, Sink再将临时存储中的数据一次性发送给下游。
- 当然如果下游支持Trasaction的话 (比如, precommit, commit ), 临时存储就不需要了。
1.3 TaskManager
在源码里, TaskManager 类同 JobManager被JobMaster取代 一样,TaskExecutor取代了legcy TaskManager 并发挥着它的作用。本文里TM指的是TaskManager的整个进程, JM代表JobManager整个进程。JM的核心类是JobMaster (当然还有ClusterEntryPoint, Dispatcher, WebMonitor和ResourceManager, 但是都起的是辅助作用), TM里的核心类是TaskExecutor 。还有一个比较混乱的Term就是Task。Task对应JobGraph的一个节点,是一个Operator。在ExecutionGraph里Tast被分解为多个并行执行的subtask 。每个subtask作为一个excution分配到TM里执行。但比较然人抓狂的是在TM里这个subtask的概念由一个叫Task的类来实现。所以TM 里谈论的Task对象实际上对应的是EG里的一个subtask ,如果需要表述Task的概念,用Operator。先澄清一下Terminology ,以免语言混乱。

图-7 TaskExecutor
- TaskSlotTable 是TaskExeutor最核心的数据结构, 它存放着TM所有的TaskSlot以及再Slot里运行的Task。 TaskSlot只是一个逻辑单位,它并不绑定或连接任何资源, 但它规定了TM里能够并行执行的SubTask的总数量。当TM 启动时,总slot数由命令行参数传入(-ys,default 为1或flink configuration 里设置的), TM创建这个指定数量的TaskSlot后供分配给SubTask使用。如前所示,TM里的Task实际指的是EG里的SubTask ,后面会详述,Task的数据结构和执行过程。
- NetworkBufferPool(NBP)是用来为InputGate(IG)和ResultPartion(RP) 分配BufferPool的。一个Task要通过InputGate 从远程另一个Task的ResultPartition 要input数据,这个Task 同时也要将输出的数据放到自己的ResultPartition里。IG和RP都需要Buffer,而这些Buffer都从NetworkBufferPool去申请, NBP的poolsize由flink configuraiton 指定。
- MemoryManager : 用于大量分配内存。在Bash模式下,输入数据unbouned 的。一些subtask 需要对全体输入数据进行 Sort或者Hash, 比如outJoin 。此时MemoryManager用大快速和大量的分配内存。关于Flink的内存管理,后面有一节详述 。
- IOManager:用于将内存的数据和硬盘之间交换。同样在Bash模式下,输入数据unbouned 的,如果EG非常复杂,Task的数量巨大。此时NetworkBuffer Pool分配的buffer不是够用的。 IOManager能够用hard disk作为Buffer还缓存数据,当Localbuffer够用时,再将数据从硬盘里换进,供本地或远程消费。
- ChannelManager是TaskExeutor非常关键的服务,他负责RP与IG之间快速的数据交换,后面专门有一节细述ChannelManager 。
- BlobCacheService 用于加载将客户的jar文件 ,Task里年的Invokable需要调用jar文件里代码, 比如 source, sink, tranformation operator, 以及他们的依赖。
- LocalStateStoreanager用于存取TM本地硬盘上的Sate数据, 但Task做CheckPoint是,除了向JM返回snapshot,它也会在本地存储。
- HeartBeatManager和FatalErrorHandler, 和JM里的类似。
- TaskExectorGatway, 同其他的Gateway一样,是用于cluster里的其他组件(JM和RM)远程调用TM的stub interface .
- ResourceManagerConnection 和 JobManagerConnections (注意,可以连接多个JM ) 用于远程RPC call RM 和 JM。
1.3.1 Data Exchange (ChannelManager)
个人觉得Task之间的数据交换,是TM里的核心和重点,也是 Flink runtime的核心、重点和难点,它的质量是区别于其他大数据系统的关键,它的质量直接影响Streaming/Batch 任务的延迟及吞吐量两大指标。人们选择一个大数据流式框架最想先了解的就是这两个指标, 至于是不是Statefull, 可靠性可用性集成度怎么样,编程接口是否简单不是不重要,但不是最关键的,是次要考虑的。所以本节作为本文的重点,我们深入解读一下TM管理的数据交换。
首先强调一下Task之间的在网络里或在本地的数据交换, 不是Task管理的,是由TM (或TaskExecutor)管理的。如下图所示。
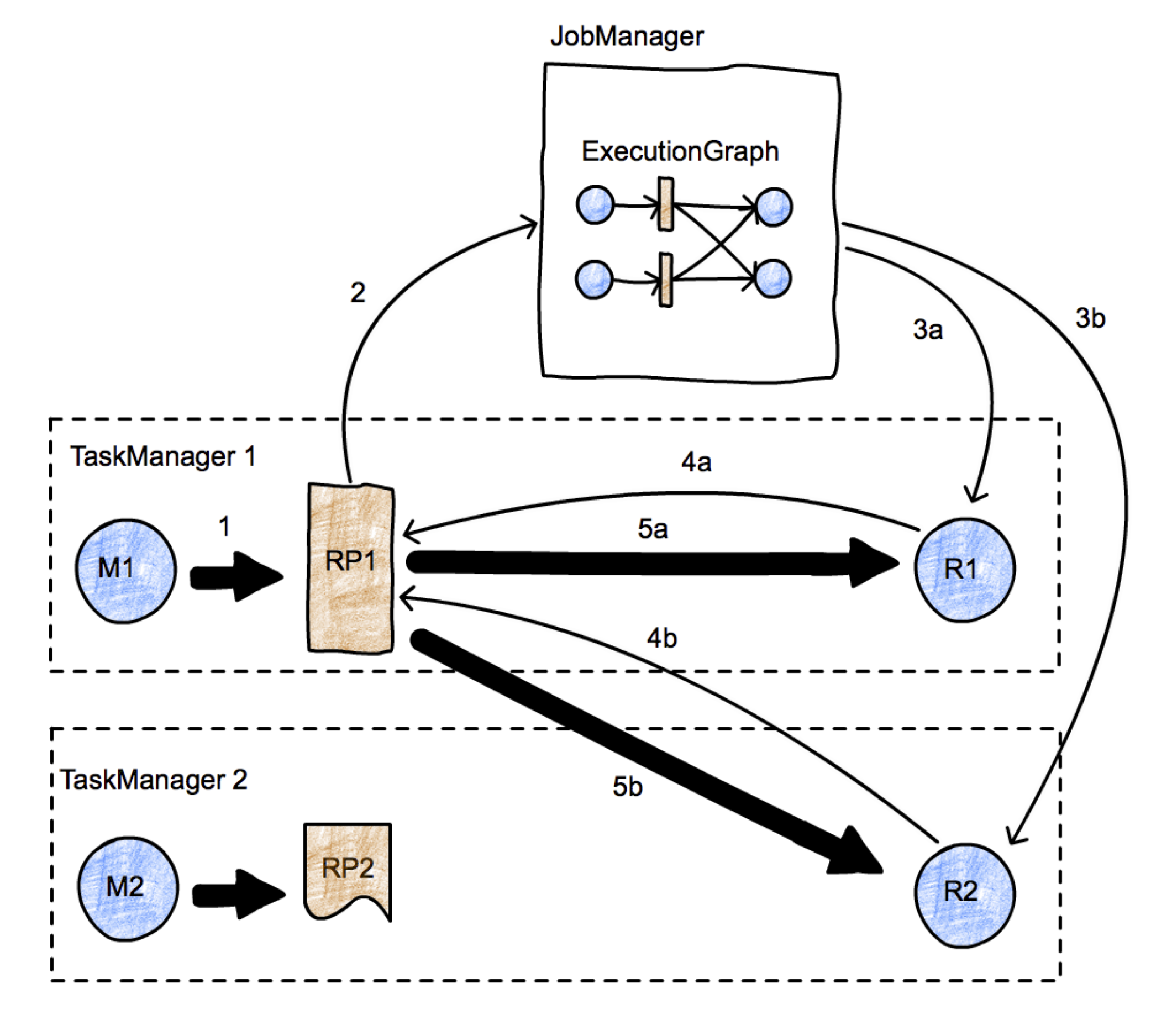
图-8 JM和TM的数据交换
JM将EG的Execution 提交给 TM,TM将Execution转化为Task执行, 并负责Task之间的数据传输.
回想一下EG的数据结构:
- 它包含多个EV对象, 每一个EV代表一个并行子任务(sub task ),
- EV 产生的结果存储在termediateResultPartition(IRP)里。
- 多个属于相同EJV的EV连接的IRP组成了IR(IntermediateResult)代表由一个Task节点产生的结果数据,
- 这个结果数据Re-Partition后,每个IRP需要根据新的Key重新分区(sub partition )然后通过EE (Execution Edge)发送给下游的SubTask 。
- 每一条EE的source 是一个IRP, target 是另一个EV .
- 如下图所示。
 (R
(R
图-9 EG 的数据结构 和 数据流
为了将JM的EG的逻辑工作流在物理机上执行起来, TM创建了相应的物理数据结构。
ResultPartition(RP)概念上对应着EG中的IRP(IntermediateResultPartition), 它负责存放一个Task生成的所有结果数据。
ResultSubpartition (RS) 是对应着RP的数据Repartion之后shuffle数的中的一个parition ,它存放着RP重新分区后发送下游的某一个sub task的分区数据。
InputGate(IG): 在EE中, IRP是source, EV 是target, 它描述了分区数据的流向, 但对不物理实现这样的结构还是不够的。 IG 由此而引入, RP是EE上的数据发送端(IRP的物理实现),IG是接收端上与RP功能类似的组件, 负责收集来自上游(RP)的数据区 (data buffer)。
InputChannel(IC) 是接受端与RS功能类似的组件,IG使用不同的IC连接不同EE上的RP 中特定分区的数据区。 比如在data shuffle的过程中多个RP都产生键值为a1的RS , 这些RSa1中的数据最终都会流向同一个IG中的IC, 这其中每一个IC承担接受上游的RP中每一个RS-a1中的数据。
数据在EE上的通讯, 由RP到IG ,数据是以binary 形式传输的。也就是说数据进入RP前,会由总Serializer 将data record 序列化成binary format, 并存入data buffer 中。 Data data buffer 由IG 接受传递给下游的Oparor 前, 由Deseriealizer将数据从DataBuffer反序列化成data record, 供该Task消费使用。 Data buffer相当于高速公路上运输乘客的大巴车, buffer中的数据相当于乘客 。 每个大巴车的形状, 运载量也是固定的, 不装满不发车 。它能极大的增加了总体数据传递传输量和创数率, 增加系统的吞吐量, 但同时也增加的单个数据的延迟 。缺省情况下2048 个buffer会被创建, 每一个32K字节 。对与比较大的record 需要多个buffer 承载 。每一个RS和IC有一些大buffer组成, RP和IG就是这些大巴车的装载者和卸载者 。
关于DataBuffer如果创建和管理, 参考后面的内存管理章节。
另外值得一提的是, 不同的对于RS的实现决定了实际的数据传输的方式。
PipelinedSubpartition支持streaming模式下的数据传输 (大部分的RS都是这种实现): 数据压满一个buffer (buffer size是configuration 指定)就向下传递 。 SpillableSubpartition 只有当RP的类型为BLOCKING是才会创建出来(Batch job 中的部分RS 是这种实现)。它支持在事先分配的Buffer不够用的情况下, 将Buffer中的数据Spill到硬盘中,从而该RS占有的Buffer得以释放。因为他会涉及IOManager (应该只有它会使用到IOManager), 所以咱们细说一下。
那什么是BLOCKING类型的? 从ResultPartitionType是这样定义:BLOCKING(false, false, false)可以看到, 3个false 分别如下:
- BLOCKING类型的RP的DataExchangeMode不是PIPELINED, 对于Batch Job, 只要下游需要shuffle, DataExchangeMode 就会被设置为 BATCH mode,而不是PIPELINED 。
- Task没有BackPressure的, 对于Batch Job, 所有的 operator 都没有Backpressure , Backpressure 在streaming job Backpressure才会被enabled 。
- 数据不是Bounded 。对于Batch Job, 因为BatchJob的数据流是unbounded (没有window的界限), streaming job才会有Window operaor, 才会有界限。
简单来说只有Batch job 里的一些RP类型是Blocking的 ,因为BatchJob总一些需要shffule 输出的operator才会有才会启动Blocking模式, SpillableSubpartition才会被创建。
注意 上面说到了的三个模式:概念比较混乱。
1. JobMode (Batch or Streaming):任务模式, 由于决定ExecutionConext
2. ExecutionMode (PIPELINED (default), BATCH, PIPELINED_FORCE, BATCH_FORCE):可配置的数据流整体模式, 目的是通过一个可配置的ExecutionMode(可在ExecutionConfig中配置)来决定所有Operator的DataExchangeMode。它是Optimizer在优化Edge的shipStrategy和DataExchangeMode做策略选择的依据。 详细看DataExchgeMode代码中,DataExchgeMode与ExecutionMode的Mapping关系。
3. DataExchangeMode(PIPELINED, BATCH, PIPELINE_WITH_BATCH_FALLBACK ) : 根据下游Operator,和 ExecutionMode, 由Optimizer 决定 数据下发模式 ,
下面是当JobMode 为Batch, ExecutionMode 为PIPELINE时, DataExchangeMode应该优化的结果。可以看出来只要下游需要Shuffle, DataExchangeMode就会被优化成BATCH模式, 此时Flink会创建SpillableSubpartition 。
DataExchangeMode.PIPELINED, // to map
DataExchangeMode.PIPELINED, // to combiner connections are pipelined
DataExchangeMode.BATCH, // to reduce
DataExchangeMode.BATCH, // to filter
DataExchangeMode.PIPELINED, // to sink after reduce
DataExchangeMode.PIPELINED, // to join (first input)
DataExchangeMode.BATCH, // to join (second input)
DataExchangeMode.PIPELINED, // combiner connections are pipelined
DataExchangeMode.BATCH, // to other reducer
DataExchangeMode.PIPELINED, // to flatMap
DataExchangeMode.PIPELINED, // to sink after flatMap
DataExchangeMode.PIPELINED, // to coGroup (first input)
DataExchangeMode.PIPELINED, // to coGroup (second input)
DataExchangeMode.PIPELINED // to sink after coGroup
因为batch 工作模式下的 shuffle通常会伴随的对整个group的排序, aggregation等, 下游需要得到(该group的)全集才可做这些操作。全局数据量比较大, 物理内存Buffer很可能不够用, 这时候SpillableSubpartition(在IOManager的帮助下)可将一部分硬盘当Buffer来用, 者极大的帮助了RP端的数据缓存。但SpillToDisk必须实现在RP端吗?不可以在接受端(InputGate)实现吗? 接受端的计算需要做密集的内存访问(sort, hash, etc ), 这些算法都是在整个数据集上的操作, 所以数据需要缓存在MemoryManager管理的MemorySegment中 从而提高存取效率, 也能为使Flink对内存做有效的管理。可现实是Flink的BatchJob需要消耗巨大的内存, 这跟接收端不使用硬盘做Buffer由很大关系。至少Flink 1.6.1的Memory是不使用硬盘做缓存的,虽然有HybridOffHeapMemoryPool, 而且它也使用了DirectMemory 来分配MemorySegment, 但并没有实现用磁盘文件来映射内存 , 所有当上游数据量很大, 但内存不足时, Flink task会很快的out of memory。之后看看Flink的最新版本是否有改善。
 R
R
图-10 使用EG控制物流数据流(数据交换)
图-10描述了Task之间数据交换的大概流程。
- 这是一个最简单的MapReduce工作图: 由一个Map和一个Reduce组成。这个Job并行度为2, 并运行在两个TM上。
- M1, M2是同一个Map Operator的两个并行的子任务。R1, R2是同一个Map Operator的两个并行的子任务 。
- M1产生的数据存入RP1 中 (arrow 1)。RP1 通知JobManager(准确的说是JobMaster)(arrow 2) RP1中有数据产生。
- RP1中其实产生一些SubParitition(RS) . JM 会通知R1和R2他们分别感兴趣的RS已经准备好。(arrow 3a,3b)
- R1, R2向 RP1发起数据请求 (4a,4b), 这些请求会触发数据在两个Task之间的传输 (5a,5b) 。之中5a是本地传输, 5b是跨TM通过网络传输。
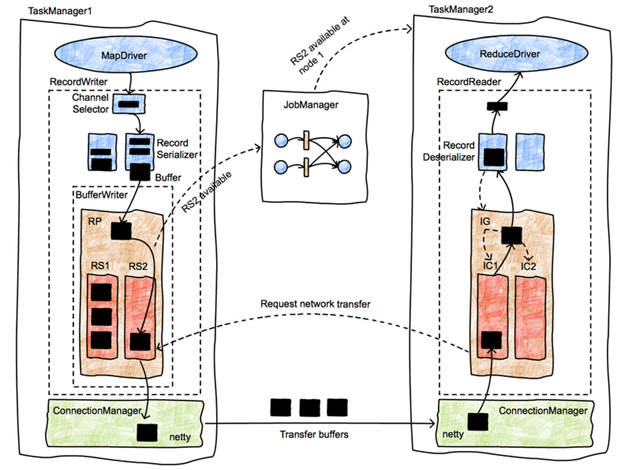
图-11, 跨TM的两个Task之间的数据交换
图-11给出了跨TM的两个Task之间的数据交换的更多细节。
- M1中的MapDriver持续的产生record对象,然后传递给RecordWriter 对象。RecordWriter 由ChannelSelector, 一系列RecordSerializer (每一个下游的RS都有一个对应的Serializer)和一个BufferWritter(更准确的说ResultPartitionWriter )组成。
- 不同ChannelSelector的实现 (BroadcastPartitioner, ShfflePartitioner, ForwardPartitioner, etc)会由不同的选择RecordSerializer 的策略。比如BroadcastPartitioner会将record发给所有的RecordSerializer, ShfflePartitioner会根据record的key决定发送给相应的RecordSerializer 。
- RecordSerializer 将record序列化成二进制数据, 并把他们存入一个固定大小的buffer中, 当buffer 写满后, 由BufferWriter将该Buffer 写入相应的RS中 (本例中是RS2)。
- RP通知JM 本RP中的RS2已经有填满数据,可供消费。 JM通过EG查找所有的消费这个RS的Task,并通过TaskExecutor通知到这些Task对应的IC, 本例中为IC1。
- IC1向RP申请传送RS2中的数据 。RP将Databuffer 交给基于netty实现的的ChannelManager,(发送后, RS2中的buffer 得以释放,还给NetworkBufferPool) 并由它发送给对端TM的ChannelManager , 从而数据将存储到IC1中。
- ReduceDriver 或者其他的Driver/Invokable的run的方法是每个一个Task的Engine 。ReduceDriver 的 Run()方法是一个while循环, 不停的从RecordReader(或更准确的名字是MutableObjectIterator)
读取next record, 根据他们的key 来决定他们是否来自同一个group, 然后调用相应的ReduceFunction进行reduce 。 - MutableObjectIterator的next record的binary实际上来自于IC(本里中为IC2)中buffer, 并通过Deserializer将binary转化为相应的Record。 当buffer 中的数据全部读完, 该Buffer 得以释放,还给NetworkBufferPool 。
- 从此完成一个buffer从M1到R1的数据传递。
1.3.2 Task 提交与执行 (TDD, Task, AbstractInvokable , Driver , ...)
根据前面的介绍,Task是由JM(通过EG) 经过Scheduler (申请和Offer slot resource和根据schedule 策略,等等) 提交给TM执行的。申请resource 和提交Task都是通过JM, RM 和TM之间的RPC通道完成的。那么具体提交了什么呢?Task如果执行的呢?Task如何知道谁是上游从而建立InputChannel的?
实际上这是一个 从EV->TDD->Task->AbstractInvokable->Driver ->具体的Oparator 实现类变形的过程。
1. 从EV 到TDD :
TaskDeploymentDescriptor(TDD) : 是TM在submitTask是提交给TM的数据结构。 他包含了关于Task的所有描述信息:
- TaskInfo : 包含该Task 执行的java 类 , 该类是某个 AbstractInvokable的实现类 , 当然也是某个operator的实现类 (比如DataSourceTask, DataSinkTask, BatchTask,StreamTask 等),
- IG描述 :通常包含一个或两个InputGateDeploymentDescriptor(IGD),
- 通常一个Operator 有一个或多个逻辑的输入, 比如Map/redue 只会有一个输入, join会有两个输入。所以IGD描述是一个数组。
- 每一个IGD都会包含一组InputChannelDeploymentDescriptor(ICD), 每一个ICD是该子任务对应的一个inputChannel 。
- 每一个ICD 包含上游RP的ID和IP 地址。那么IC怎么知道应该消费RP的哪个RS呢?
- 当IG 和 source RP 的并行度相同时, 每一个IC都会去消费各个SourceRP 中同子任务序号相同的RS .
- 当IG 和 source RP 的并行度相同时, 通过对双方平行度进行一番取余, 来决定该IC 要消费的RS: 0个或多个。
- 目标RP的描述: ParitionId, PartitionType, RS个数等等
- 其他的一些描述 : JobId, ExecutionId, SlotNumber, subTaskIndex (子任务序号) , 等等。
不难看出,EV包含上述的所有信息,EV的一个方法createDeploymentDescriptor,完成了上述变形。JM 在向TM submitTask时,传递的是TDD不是EV。为什么要做此变形的而不是将EV直接传过去既然他们很类似? 我想这个一个设计模式问题, EV是作为ExcutionGraph的中的顶点 ,它最好只存在于JobMaster 的物理图中, 而不是作为参数传递给其他组件,从而维护它的独立性和单一性。参见Descripor设计模式。
当TaskExecutor(TM)接受submitTask 的RPC调用从而得到TDD时, 他会将TDD实例化为一个在TM上可以执行的对象 : Task 。
2. Task :
Task 是一个Runnable 对象, TM接受到TDD 后会用它实例化成一个Task对象, 并启动一个线程执行Task的Run方法。
Task实例化时, 他会将TDD中的IGD实例化成InputGate (IG) 和 InputChannel(IC), 将RPD实例化成RP . 在 Task 的Run 方法被调用时, 它根据TDD的 TaskInfo, 使用URLClassLoader将用户的operator类从HDFS加载, 并实例化TaskInfo所描述的AbstractInvokable对象, 并将IG, IC, RP , 还有其他所有的AbstractInvokable需要的服务类(MemoryManager, IOManager, CheckoutResponder, TaskConfig etc )都传递进去, 然后调用AbstractInvokable 的 invoke 方法。
3. AbstractInvokable
如之前给出的一些例子 : DataSourceTask, DataSinkTask, BatchTask, StreamTask 。 它们是Task.Run()时, 通过TaskInfo加载并实例化的。 这些Task Operator的源代码都在
org.apache.flink.runtime.operators 或org.apache.flink.streaming.runtime.tasks下面 。每个BaskTask的需要的工具都是类似的, 只是计算的流程不同 , 所以BaskTask的invoke方法调用时, 它根据TaskConfig(信息继承与TDD的TaskInfo) 加载和实例化不同的Driver 类, 并调用Driver的run方法由Driver指挥流程(input, calcuate, out , etc )。
4. Driver
Driver类和AbstractInvokable位于同一个包内。 每一个Driver的run() 大都是一个循环。 不停向IG 要next record , 写metrics, 调用function 计算, 然后见结果发给RP。只不过有些drver一次计算需要两个record, 有些driver 需要两个record 来自不同的IG , 有些需要将所有的input全部收完才计算, 有些在window expired后才计算, 等等。下面是FlatmapDriver 的run() 。
while (this.running && ((record = input.next()) != null)) {
numRecordsIn.inc();
function.flatMap(record, output);
}
1.3.3 内存管理(NetworkBufferPool, MemoryManager, IOManager
在stream模式下数据处理是有界限(bondary)的, 每个window的处理所使用的内存是相对比较小 的, 所以Flink stream job 通常使用的内存较小。
但在batch 模式下, 数据处理是无界的 (所谓无界就是没有Window),如前面所示, 很多job 需要将上游所有的input都取干净,才开始计算, 如sort, hash join, cache 等, 此时所需要的内存是巨大的, 比如上游operator 读取300G文件然后map成record, 下游operator 需要将这些record 同另一组输入做outer join 。所以Flink内存管理主要针对的是这些batch job 。
总起来将, Flink的内存管理还是比较失败的, 至少在我用的版本里(1.6.1) , 主要原因还是 MemoryManager并没有联合IOManager Disk去扩展内存。但我觉的MemoryManager的引入, 就是为了管理Flink的内存, 以防止OutOfMemoryException的发生 (如Spark一样 )。 防止溢出最直接的方法就是当系统内存不足或超过throttle时, 使用DiskFile以补充内存 , 从而完成 那些内存消耗巨大的操作。 只是version 1.6.1 还没做好 ,或许以后版本会做好 。
先看下Flink的内存管理机制吧 。
从概念上将, Flink 将JVM的heap分成三个区域。
- Network buffers pool: 是一些 32 KiByte MemorySegment用于TM之前数据的批量传递。回忆一下前面围绕图-11的介绍。Network buffers Pool 在 TaskManager启动时分配的。 缺省2048 buffers 被分配,可通过
"taskmanager.network.numberOfBuffers"调整。 - Memory Manager : 是另外大量的 32 KiBytes MemorySegment, runtime algorithms (sort/hash/cache)使用这些buffer 用于将 records存入缓冲区 之后应用算法 ,record 是以serialized 的形式存储在 MemorySegment里的 。 这些MemorySegment Pool 是在TaskManager启动时分配的 。MemorySegment Pool 的大小,可以用两种方式设置。
- Relative value (缺省): MemoryManager在所有的service 启动后(包括network buffer pool ) 会计算heap 剩余总量, 然后按一定比例 (by default 0.7) 作为 pool size 。 这个比例可通过
"taskmanager.memory.fraction" 配置。 - Absolute value: 科通过
"taskmanager.memory.size"配置一个绝对值, 比如10GB。
- Relative value (缺省): MemoryManager在所有的service 启动后(包括network buffer pool ) 会计算heap 剩余总量, 然后按一定比例 (by default 0.7) 作为 pool size 。 这个比例可通过
- Remaining (Free) Heap: 剩下的Heap用于存储 TaskManager's 数据结构, 比如 network buffer Deserialized 后的 record 。

图-12 Flink Memory
Network buffers pool 和 memory segment pool 都是TM启动时就分配的, 它们生存于JVM的老年代, 所以不会被GC回收的。只有Free Heap区域在新生代里生存。
IG/IC, 和RP/RS 的record存储在network buffer 里,有些RS (SpillableSubpartion)需要Spill to Disk ,因此他们需要IOManager 的帮助。
需要sort/hash/cache的Task瞬时内存消耗非常大,因此从IG接收record后就将他们存储memory segment pool, 之后在对serialized record 应用 算法 。
其他的Task大都是pipeline 方式, 来一个消费一个, 瞬时内存消耗不会大。此时这些Task会使用FeekHeap 区域的内存。
如果没有人为错误, 系统不会有瞬时的大量内存申请, 所以不会有OutOfMemoryException , 所以FreeHeap的区域应该是比较轻松的。
可是问题是, memory segment pool 目前没有使用DiskFile 作为OffHeapMemory, 它能够装载上游下来的巨量 blocking 输入吗? 这就是Flink 1.6.1 的问题。不过这个MemoryManager实现的好不好的问题, 设计上是有防止OutOfMemoryException 的组件的。这个就期待Flink 新版本 补强这部分功能吧。
前面说“serialized record 应用 算法“,这是怎么做到的呢? Flink 实现了大量的 TypeSerializer 和 TypeComparator, 他们懂得record 是如何序列化到字节数组里的,所以也知道如何将record部分地deserialize 。通常算法只是使用record的某个或某些field。 部分deserialize极大的降低内存使用, 提升了数据存取的速度, 从而极大的提成了内存的使用效率。 serialized 形式的record 数据是Flink 能够将他们在TM之间, 跨进程和跨网络的传输, 它是分布式系统需要的数据形式, 同时, 它也为MemoryManager 将它们在内存和硬盘之间交换提供了条件。
IOManager 使用FileChannel将MemorySegment同DiskFile建立映射, 从而实现将数据在MemorySegment和DiskFile之间写入和读回。
所以,虽然MemoryManager目前还有些问题, 在这种设计下, Flink的内存使用效率肯定会进化的极好 。
1.4 ResourceManager
RM在Flink内部是Flink cluster 里slot资源的管理者 , TM 提供slot,JM (JobMaster)消费slot 。 RM同JM和TM 都要保持心跳,以保持slot市场的活跃 ,以及在TM或JM失败的时候通知给对方。
总起来说RM的作用主要包括:
- 启动和获得TM, 从而获取Slots 。
- 提供JM和TM发送对方的失败通知。 如一个TM的心跳停止了, JM会通知消费该TM slot的JM。
- 当注册过来的TM的slot有剩余時, RM会缓存起来。
第二、三项功能比较好实现。第一项功能需要同外部的集群管理器合作才能实现。所用RM是一个随环境不同而不同的组件。在不同的集群环境里, RM有不同的实现类。
市场上比较流行的集群资源管理器主要有Yarn, Mesos, Kubernetes, 和 AWS ECS 。其中Yarn, Mesos中, 可以利用ApplicationMaster/Scheduler是资源调度器,只要将RM在ApplicationMaster中运行起来,理论上 RM就可以Yarn, Mesos的master通信,为TM分配容器和启动TM。实际上JM的所有组件(Dispatcher, RestEndPoint, JM, ClusterEntryPoint, etc)都在ApplicationMaster启动的。
Kubernetes和ECS 没有ApplicationMaster的概念, 但TM可以作为一个有多个副本的deployment (K8s) 或 service (ECS) 运行。此时 TM 的多少(规模)是由deployment/service 根据一定策略自动扩容的而不是根据Flink需要的slot数量。Flink并没有实现特殊的ResourceManager和K8s/ECS集成,此时的FlinkCluster使StandaloneCluster。如果能一个K8s/ECS 特殊的RM和集群的master通讯,使TM能够能按需扩容而不是自动扩容,那就和在Yarn里一样完美融合, 而且能够用上Docker的服务, 毕竟Yarn目前只是使用JVM作为容器,并没有真正达到真正资源的隔离 。
RM在不同cluster以不同的方式启动新的TM以补充slot资源,当然当一个job 结束时,它也会同集群的master通讯,释放container,关闭完全空闲的TM。
在不同的集群环境里,RM能够管理TM的生命周期,那么谁来启动和结束JM 呢? 请参考后面的 Flink Deployment 。
1.5 HighAvailability
Flink的 HighAvialbility 主要有两个服务组成 : LeaderEleketronService和LeaderRetrievalService 。
1.5.1. LeaderEleketronService
该Service是用来选举Leader的 。假设系统里启动了两个Dispatcher 。先回顾一下什么是Dispatcher , 看图-2, JobMananager 的进程是ClusterEntryPoint的main 函数启动的,ClusterEntryPoint启动了 WebUI, Dispatcher 和ResourceManager。当用户提交了 Job时, Dispather 实例化一个新的JobMaster 来管理这个job, Dispatcher也是CheckPointBarier 的发起者, 同时也是来自WebUI REST 后台的请求的处理者。Dispatcher 的作用承上启下, 作用非常核心,不可缺失,所以Flink启用HA服务来保护它。 Flink 系统里, 使用HA 保护的核心服务还包括ResourceManager ,JobMaster 还有WebUI 的REST Endpoint。当系统里启动两个Dispatcher 谁来当Leader呢? 这就要LeaderEleketronService (LES) 的决定了。
目前Flink的起作用的LES使用ZooKeeper 实现的。实现方式就是两个Dispather都试图抢占的特定ZooKeeper Path (dispather latch path) 的LeaderLatch(参见 curator framework),谁先抢到了, 就被选举成Leader , leader的 AKKA URI 和UUID被被写道一个特定的ZooKeeper path 中(leader path) 。只有Leader 是工作的,因为其他组件在使用Dispather时会向获取Leader Dispath的URI, 然后才RPC的 。 其他竞争者不会接受到RPC, 他们只有继续监听,如果当前的Leader 退出了, LeaderLatch被释放了, 从而新的leader会被选举出来。
1.5.2. LeaderRetrievalService
那么对于Dispatcher的使用者, 怎么知道谁是Leader呢? 这就需要LeaderRetrievalService了 (LES ) 。 对于用ZooKeeper 实现的LES, 它只需要监听一下leader path, 它就知道谁是leader 了 。
比如, 当你用fink run 命令提交job 时, 假如系统里有多个Fink REST Enpoint, Flink的ClusterClient 对先使用LES获取Leader REST Endpoint, 然后才会将job 发送过去。
除了ZooKeeper的实现, HAService 还可以以来外部的名字服务(如DNS, LoadBalencer , etc ) 实现。在LES和LRS 永远返回 HA保护的服务的URI(无论是AKKA PRC URI, 或REST URI )。 该URI永远保持不变, 如果提供服务的server失败, 名字服务会将给URI映射到另外一个工作的server 。 具体请参考 StandaloneHaServices的代码。
1.6 Flink Deployment
目前为止, Flink 支持大概4种部署方式或4种cluster 类型,MiniCluster(或LocalCluster), StandaloneCluster,YarnCluster,MesosCluster 。 虽然前面提到过Kubernetes , ECS , Docker , 但他们的本质是将JM和TM docker 化 , 从而是他们运行在真正的 dockers里面 , cluster 还是 StandaloneCluster 。
图-3 是StandaloneCluster , 图-4是YarnCluster , MesosCluster 与YarnCluster 类似, MiniCluster是运行在IDE(e.g. IntelliJ )的虚拟cluster , 它主要用于 FlinkApplicaiton的调试 。在Session 模式下,表面上可以看来StandaloneCluster 与YarnCluster基本流程是一致的, 只不过是启动JM 和TM的启动机制不同而已。YarnCluster/MesosCluster 里TM是由他们各自的ResourceManager实现根据需要启动的。 在 StandaloneCluster下, TM是手工启动的。其实在YarnCluster下, JM 也是Yarn启动的。其实, 如前所述, StandaloneCluster与YarnCluster / MesosCluster的本质区别是, 前者的用于TM硬件资源是管理员手工分配的, 后置是有RM同集群管理器协调自动分配的。
从Flink内部看, 是为了支持这些异构环境, Flink 对于不同的Cluster, 实现了不同的ClusterEntryPoint用于启动不同ResoureManager ,以及Dispatcher 。不同集群类型的ClusterEntryPoint对JobMode和SessionMode有 不同的实现, 比如YearnSessionClusterEntryPoint和YarnJobClusterEntryPoint。Session模式下, Dispatcher使用的时StandaloneDispatcher, Job模式下,使用的是MiniDispather 。 关于什么是JobMode和SessionMode, 请参考图-3下面的解释。
如前所述,JM接受jobGraph的对象或对象文件(序列化后),jobGraph由FlinkClient生成, FlinkClient和JM位于不同的JVM (MiniCluster除外)。如果JobCluster无法由FlinkClient启动 (通过某种方式),则JobGraph生成以后需要存到指定位置,在手工启动JobCluster读入,这样的过程比较复杂。基于目前的架构,尽管Flink在各种集群环境里对job mode , session mode 在代码上都由支持, 但job mode 通常由于集成度不够好,用户无法方便使用。
我用一个表来描述他们跟具体的不同以及Flink是如何支持这些异构环境。为了使这个表不至于太庞大,先把不同的cluster 类型表述下先。
1. MiniCluser
用于在IDE(IntelliJ, Eclipse) 运行FlinkApplication 的小型FlinkCluster环境,JM和TM运行在同一个进程里,主要用于在IDE里调试Flink Application。
2. StandaloneCluster
可以运行在单机或多机上的FlinkCluster环境, JM和TM运行在不同的JVM里。只要有JRE , 无论在Windows ,Linux都可以搭建StandaloneCluster。
用户可以使用FlinkClient 的command line,或API 直接向JM REST URI 提交job ,具体看Flink CLI 的 “-m" 选项。StandaloneCluster非常有利于搭建单元测试,集成测试以及演示环境。
3. YarnCluster
在Hadoop集群里搭建的FlinkCluster, JM和TM都运行在Yarn管理的容器里。JM做为Yarn里ApplicationMaster ,Flink cluster作为Yarn的一个Application运行。
Yarn是Flink与之集成度最好的集群管理器。 用户可以直接使用FlinkClient 的command line,或API 直接向Yarn提交job , YARN 会自动的启动(或连接现有的)Flink JM, 自动启动需要的TM,而后在该Flinkcluster运行任务。
具体看Flink CLI 的“-m yarn-cluster" 和 ”applicationId" 命令行用法。
4. MesosCluster
在Mesos集群里搭建的FlinkCluster, JM做为Mesos里Scheduler , 一个 Flink cluster作为Mesos的一个Framework运行, JM和TM都可以运行在Mesos管理的容器里。
TM由JM的resource Manager同Mesosmaster 协调按需自动启动和销毁。JM 需要先使用Marathon 创建服务, 由Marathon 启动。Marathon服务的后端都是运行在Mesos的容器里,
而且Marathon服务一个高可用性服务。
用户可以直接使用FlinkClient的command line,或API 直接向Marathon 创建服务提交job ,具体看Flink CLI 的 “-m" 选项。
个人觉得Flink 与Mesos的集成度可以在提高一些。目前用户需要手动的为JM创建Marathon Service, 可参考下面写一个简单的配置文件, 调用flink的shell脚本mesos-appmaster.sh启动Flink
MesosSessionCluster的JM (该JM会启动MemsosResourceManager用来启动需要的TM)。
yhttps://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/deployment/mesos.html
Flink 完全可以改进一下Client端, 添加集成Mesos Marathon需要的 ClusterDescrptor类,CLI类(比如MesosJobClusterDescripor, MesosSessionClusterDescripor,FlinkMesosSessionCLI ),丰富“-m" 选项,
由ClusterDescrptor类自动创建和销毁JM (Marathon 服务)
5. Kubernetes/ECS/Docker
Flink 对于Kubernetes/ECS/Docker在源码级别并没有任何支持。只是说,可以将StandaloneCluster的JM和TM运行在这三个以Docker 作为容器服务的
集群环境里。所以是,Flink 与他们的集成度, 比较低 。Kubernetes的具体做法分别对StandaloneCluster的JM和TM做两个deployment(就是可以平行扩展的docker group ), 它们分别启动StandaloneCluster的JM和TM (通过start-console.sh脚本), 然后对JM的
deployment做一个Service使其具有高可用性,当然需要将该Service的URI传递给TM,前面说过StandaloneHAService是靠统一的URI来提供HA服务的。更详细的请参考下面。
https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/deployment/kubernetes.html
ECS和Docer的实现同Kubernetes 类似, 只是在各自使用的技术名称不同而已。ECS的AutoScalingGroup等价于Kubernetes的Deployment。 common sense是一样的, 只是各家用各家喜欢的名字。
总之,将Flink的部署在上述集群里, 目前手工的工作还是比较多的,而且TM的数量是预先设定的,或按策略自动扩容的, 并不是最优的由Flink RM 指导的按需扩容。得到的好处最大应该是Docker的容器服务。毕竟Yarn或Mesos对Docker的支持并不是很好。
个人觉得Flink 与他们的集成度可以在提高一些。同提高Mesos的集成度的想法一样, 在目前Fink的框架下,只需要改进FlinkClient,添加集成Kubernetes API-Server需要的 ClusterDescrptor类,CLI类(比如K8sJobClusterDescripor, K8sSessionClusterDescripor,
FlinkK8sSessionCLI ),丰富“-m" 选项,由ClusterDescrptor类自动创建和销毁JM (JM 的Deployment和 Serice ), 添加K8sResourceManager, 用它来创建及扩容TM的deployment 。
| Cluster Type | JM 启动方式 | TM启动方式 | ClusterEntryPoint | ResourceManager | SuportedMode |
| Mini |
调试环境启动的Flink Client是 LocalEnvironen或 LocalStreamEvronment, 它们的execute方法会 先启动MiniClusterEntryPoint |
由MiniClusterEntryPoint启动 | MiniClusterEntryPoint
.java
|
StandaloneResource Manager.java |
只支持JobMode |
| Standalone | 手工,如sart-cluster.sh脚本 |
手工, |
StandaloneSession ClusterEntryPoint.java
StandaloneJobCluster EntryPoint.java |
StandaloneResource Manager.java |
支持SessionMode job mode 有支持,但用户无法方便使用。 |
| Yarn |
jobmode下 由FlinkClient里的 YarnClusterDescriptor, 调用Yarn的API通过YARN启动。 JM做为ApplicationMaster自动启动。 SessionMode JM需要手工运行 yarn-session.sh, JM和TM的内存不是per-job, 只有管理员才能设定。 |
JM 里的YarnResourceManager 利用YARN的API启动TM。 |
YarnSessionCluster EntryPoint.java
YarnJobCluster EntryPoint.java
|
YarnResource Manager.java |
支持JobMode和SessionMode
|
|
Mesos |
通过Marathon Service启动, JM运行在Mesos的容器里。 但Marathon Service需要手 工创建。 |
JM 里的MesosResource Manager 利用Mesos的API启动TM。 |
MesosSessionCluster EntryPoint.java
MesosJobCluster EntryPoint.java |
MesosResource Manager.java |
支持SessionMode job mode有支持,但不方便使用。需要 提升集成度。 |
|
Kubernetes /ECS/Docker |
由JM service 启动 | 由TM deployment启动 |
StandaloneSession ClusterEntryPoint.java
StandaloneJobCluster EntryPoint.java |
StandaloneResource Manager.java |
支持SessionMode job mode有支持,但不方便使用。 需要提升集成度。 |
表-1 Flink Deployment
1.7 Failure Detection and Reaction
如前所述FinkCluster里 (参考图-3), 最核心的组件而且交互最频繁的组件是Dispatcher, ResourceManager, JobMaster, 和TaskManager 。
其中对于Dispatcher, ResourceManager, JobMaster,通常是ClusterEntryPoint启动Dispatcher和ResourceManager,然后当有job提交时,Dispatcher启动JobMaster。(MiniCluster, JobCluster略有不同,但类似)。尽管他们之间使用RPC通讯,他们生存在同一个JVM里,如果其中一个失败,同时使整个JVM(由于异常崩溃了)失败了,所有组件都失败了。那么他们中如果有承担Leader责任的,也都会通过HA Service 切换到另一个工作的JM后端的RPCEndPoint。
如果TM失败了, JM能够感知到heatbeat 機制感知到, JM 和RM都与主动向TM发送和hearbeat , 所以TM heartbeat 一旦timeout , JM会释放该TM 提供 过来的slot,与此同时将slot上运行的Execution 的状态设置为失败, 参考 SingleLogicalSlot::signalPayloadRelease .
在stream mode 下,JM 会尝试将该TM上失败的Task重现分配到别的TM上(如果slot资源时有的,或可以分配的)。
在Batch mode 下, JM 会将整个job 失败,然後嘗試重新啓動整個job 。
重新啓動的streaming Task會根據上一次的checkpoint 回復狀態, 繼續運行。
1.8 Flink Security
to be filled .
2. Flink的源码结构
上一章介紹Flink了的架構, 它包括了那些主要組件? 組件是怎麽工作的? 組件之間是怎麽工作的?組件使用的資源(包括服務器,容器,内存和CPU和Disk)是如果分配的? 以及組件是如何部署的?一個job是怎樣分割成小的Task并行執行在cluster裏面的?
怎麽保證組件HignAvailablity 以及組件是如何做 失敗處理的?以及Flink關於系統安全的設計等等。 這些關於架構的介紹,重點在於瞭解flink cluster中各個組件的互操作行以及容錯處理, 瞭解框架, 以便於再出現問題的時候我們能夠對它有比較針對性的debug 。關於Flink引以爲傲的statefull operator, window watermak, checkpoint barrier , stream/batch API 以及web monitor本文都沒有介紹,請參考相关的Flink的官方文檔。
Flink的源碼還是比較清晰易懂的, 尤其是瞭解了她的架構后, 大部分的實現都非常符合common sense 。 不想在這裏貼一堆代碼段然後加注釋解讀了, 本文的篇幅已經太長了。過一下所有的包,解釋一下他們的主要作用,以及需要框架裏使用的主要類吧。用一個大表來列舉比較合適。
| Artifect | 功能介紹 |
| Flink-client |
FlinkCommandLine 入口類 (CliFrontEnd) 解析Flink 命令行 (DefaultCLI, YarnSessionCLI ) 負責將從用戶jar 文件中main函數生成Plan (PackagedProgramUtils),用通過LcoalExecutor或RemoteExecutor調用flink-Optimizer生成 jobGraph . 使用ClusterDescriptor啓動jobManager (比如在yarn), 使用并將jobGraph 用ClusterClient提交給本地或遠程的JM。 |
| Flink-runtime |
Flink 源碼的核心。 框架的核心組件都在裏面, 包括 Diskpatcher, JobMaster, TaskExecutor, ResourceManager, ClusterEntryPoint, WebUI以及他們依賴的子組件以及核心數據模型, JobGroup, ExecutionGraph, Execution, Task, Invokable, Operator, Driver, Function, NetworkBufferPool, ChannelManager, IOMemory, MemoryManager, PRCService, HAService, HeartbeatService , CheckPointCoordinator , BackPressure, etc . 這些類的名字和作用在上一章都或多或少提到過, 最好結合架構的介紹, 理解他們的代碼。 |
| Flink-runtime-web |
Flink Web monitor 的界面和handler . handler會調用Dispacher 的方法處理客戶請求, 比如sumitJob. |
|
Flink-java Fink-scala |
用Java 和 scala實現的Flink Batch API , Dataset, ExecutionEnrionment, etc . |
|
Flink-stream-java Flink-stream-scala |
用Java 和 scala實現的Flink stream API , DataStream, ExecutionEnrionment, , StreamExecutionEnvironment, windowing, etc . 和對streaming提供支持的runtime, Checkpoint, StreamTask, StreamPartitioner , BarrierTracker, WindowOperator, etc . |
|
Flink-optimizer |
主要功能是優化Plan 和生成JobGraph。Flink-optimizer是一個很client端使用重要的庫,它決定了從客戶代碼(application) 到jobGraph形成過過程。 我個人覺得通常也是調查和解決 application問題的根源, 比如application 的寫法是不是合適的,有問題的, 或最優的等等。 在前面架構極少裏面,并沒有談及Flink-optimizer, 所以在這簡單介紹下。 fink application 開發者使用Flink API 編寫application, flink-client 为了将application 最终能在Flink cluster里運行起來是, 它首先通過讀取用戶jar 文件中的main函數生成Plan:以DataSink為根的一個或多個树结构, 樹的節點都是application使用的 API operator, 每一個節點的輸入來自與樹的下一層節點。 不難想象树的叶子节点都是DataSoruce: 他们没有输入节点,但有用于读取数据源的inputFormat, 根节点是DataSink :他们既有输入节点,也有用于写入目标系统的outputFormat, 中间节点都会有一个多个的输入节点。Plan数据结构描述了同用户的application完全相同的数据流的节点, 但它只是一个逻辑树状结构, 并没有对连接节点的边做描述, 也没有对application编写的数据流做任何修改。o 然后使用Flink-optimizer将Plan根据时根据优化策略设置节点的边上的数据传输方式,并同时用OptimizerNode生成多种优化方案, 最后选择cost 最小的方案产生的方案 作为OptimizedPlan 。 比如将数据装载方式(ShipStrategyType) 设置 FORWARD, 而不是 PARTITION_HASH而 应为 FORWARD 的网络cost 最低(0) 。OptimizedPlan是一个图结构, 图中的顶点(PlanNode) 记录了自身的cost以及从source 开始到它的累计的cost 。OptimizedPlan主要针对与join和interation操作。 然后Flink-optimizer将OptimizedPlan 编译成JobGraph。编译的过程应该基本上是一对一的翻译(从PlanNode 到 JobVertex), 但如果一串PlanNode 满足Chaining 条件 (比如数据在每个oparator 都不需重新分区, 流过operator 之后, 直接forward到下一个operator), Flink-optimizer就像这些 operator 连接到一块然后在JobGraph里面只创建一个 ChainedOperator jobVertex, ChainedOperator同Spark里面的stage 概念类似, 是优化的一部分。 最后flink-client将jobGraph提交给FlinkCluster ,jobGraph 变形为 ExceutionGraph在JM和TM上执行。 可以从Optimizer 的compile 和JogGraphGenerator的 compileJobGraph展开看, 他们分别complie的是Plan和OptimizedPlan 。 Flink-optimizer优化的是parition 的选择以及算法的选择, 而不是DAG 的workflow 。 |
|
Flink-Table |
用户可以用flink-java/flink-stream-java里的api编写flink application, 也可以用 Flink-Table 的table api和 flink-sql写 application 。 Flink-Table将数据源(Dataset, DataStream)都 generalize 成Table (row based ),用户可以用类似关系型数据库的操作方式操作Flink的数据源, 这种方式虽然屏蔽了一些flink-api的特性 (比如 broadcast), 但极大的降低了application 的开发难度,减少了客户程序的代码量,从而极大的提高系统的重用度。 Flink-table 的底层还是依赖dataset/datastream api, 所以基于table api 或SQL 的程序 (Program) 最终会翻译成 Flink-optimizer 的Plan , 经过前面所述同样的编译优化过程, 最终一个EG的形式运行在JM和TM上。 当然,在被翻译成Plan之前, Flink-table 的Program 也会有自身的优化过程, 比如SQL Plan optimization . 代码需要看, 如何实现一个Table : StreamTableSource, BatchTableSource, BatchTableSink,AppendStreamTableSink 如何扩充FlinkSQL : UserDefinedFunction, ScalarFunction,TableFunction,AggregateFunction |
|
Flink-yarn Flink-mesos Flink-container |
Flink 怎么支持异构环境的, 包括不同环境里的, 主要是异构环境里的不同ResourceManager (启动TM ),以及 ClusterDescriptor (启动JM)如何实现的。 |
|
Flink-library |
flink-cep, flink-gelly, flink-ml |
|
Flink-connector Flink-format |
连接外围数据系统(数据源和输出)系统的InputFormat, OutputFormat . |
|
Flink-filesystem |
Flink支持的分布式文件系统, hadoop, s3, mapr |
|
Flink-metrics |
flink 的metrics 系统 |
|
Flink-statebackends Flink-queryable-satate |
flink 的 state的存储 |
|
flink-jepsen |
Flink的UT和集成测试。 |
表-2 Flink packages
3. Debug Flink
3.1. Intellij 准备工作
需要安装JDK1.8和Scala的plugin, 否则Flink无法在IntelliJ里编译。
下载flink1.6.1的代码,到下面的地址 download ,然后用maven 编译 。
https://github.com/apache/flink/tree/release-1.6.1
下载例子程序: https://github.com/kaixin1976/flink-arch-debug 。 由于github的限制, 上传的instrument文件相对较小,读者可以通过自我复制扩大文件尺寸。
运行例子程序, 有两个参数 :
第一个是 joinType,可取值为"normal" 或"broadcast"。normal 方式完全依赖FlinkOptimizer产生 优化的方案, broadcast是运用一下方法, 使join的第一路输入广播, 第二路输入自由平均分配。
第二个使api类型, 可取值为 "api" 或 "sql" 。api方式指的是Flink Java API, sql 使 Flink SQL API 。对于Join Flink Java API 可以指定JoinHint或Parateters从而影响优化, sql 没有这些接口, 只能在DataSoource 上做文章。
具体看JoinTest::main()。
3.1.2 Intellij debug configration
如前所述, Flink分布式环境的主要包含三部分:
1. FlinkCient : 生成、优化和提交JobGraph.
FlinkClient的main 函数在CliFrontend中, VM 的classpath 和工作路径设置为本地安装的一个flink路径 , 用于找到所有需要的jar文件和 flink confugration .
程序参数跟flink run 一样,

图-13 Flink Client debug configuration
2. JM : 生成ExecutionGraph,并为其中的所有的的子任务分配slot资源, 并将子任务发送到slot所在TM上运行。
JM 使用StandaloneSessionClusterEntrypoint , 他会启动Standalone Session Cluster 的entry point .
图-14 Flink JobManager debug configuration
3. TM: 运行ExecutionGraph的子任务。

图-14 Flink TaskManager debug configuration
3.2 例子程序 和问题描述
例子程序是一个利用Flink SQL 把一大一小两个数据源join再一起的Flink application 。大数据源叫instruments 包含了一些假造金融工具(比如股票期权等)的基础数据(其中包括该工具交易货币的ID),小数据源是货币currencies 包含货币ID,和货币名称。join目的是给与金融工具的货币ID获得对应的货币名称(比如,人民币,欧元,美元等)。
join的过程是比较简单的,首先 从文件创建两个数据源(instrument 和 currency 的 TableSource), 然后用调用 SQL 做join, 最后创建TableSink将join的结果输出到文件里。程序的主体如下。
public void joinSmallWithBig(String joinType) throws Exception { "StrikePriceMultiplier,LotSize,CurrencyCode,AssetState " +
"FROM currencyTable join instruments on currencyTable.CurrencyId=instruments.CurrencyID ");
|
表-3 例子程序
问题是join的过程发生了严重的数据倾斜 (data skew )。全世界的金融工具分布式极不平均的, 绝大部分使用美元,欧元计价 (比如例子程序里假造的instrument的数据源,大概有13/14 的instrument是以欧元计价的)。如果使用常用的 hash join 或 sort-merage join, 数据倾斜是必然发生的。 调用joinSmallWithBig,并传入任意字符串 做为joinType 时, 程序调用的registerCurrencyTableSource方法, 该方法就是创建了一个普通的CsvTableSourcei并注册, 之后利用sql join 将两个数据join起来,此时会发生数据倾斜。如下图所示:

图-15 flink-webmonitor 上的currency 数据源

图-16 flink-webmonitor 上的instrument数据源
可以看出currency 的CsvTableSource一共有492条记录分4个split读入,数据量确实小,instrument数据源记录数大概14million 条记录有,比较大,同样分4个split读入, 分配不可谓不均衡 。但当join后, 均衡彻底打破了,如下图所示:

图-17 flink-webmonitor 上的hash-join
两个数据源的输出策略(或JoinOperator的输入策略)也就是连接数据源与JoinOperator的那条边的ShipStrategyType被设置为一个currencyId 为key的HashPartition。 由于本例中约13/14的instrument以欧元计价,大概有13 million个instrument 记录依照hash code 被发送到一个task的IG里, 剩下约1 million的其他三个task 。
借这张图咱们需要重温一下的前面提到的task, RP,RS,IG,IC的关系, instrument数据源 有4 个task所以4个RP, 每个RP会产生4个RS以装载不同的hash code,共16个RS 。 下游join operator 有两个IG (分别连接instrument数据源 和currency), 每一个IG 的ShipStrategy都是HashParition。每一个IG 有4个 IC, 每个IC 都连接上游标号相同的RS (比如JoinOperator task1的 IG1 的IC1,IC2,IC3,IC4)只连接上游 instrumentSource task1, 2,3,4 的 RS1) 。 JoinOperator是一个DualInputOperator, 通常的operator只有一个IG 。
上图中13 million的record received (13,836,997)是joinOperator的第三个 task 的IG1 和 IG2中相同标号IC的记录数量(比如IC2),由于currency数据量很小,构成13 million 这个数量级的来源是instrument中以某几个货币计价的instrument, 如前述主要是欧元 , 此例中欧元计价占比大概为13/14 。
数据倾斜的结果造成joinOperator的第三个task需要多于别的 task的100倍的内存,通常会超过容器预先分配的内存配额。罪魁祸首是 join operator 输入边 的 ShipStrategy : hash partition 。 SQL 里无法指定 join 使用哪种策略, 为什么flink 会在翻译(将sql 翻译成jobGraph)的过程中将 join 输入册率 优化成hash partition 呢?一个小数据集和大数据集join,最好的方式是将小数据集广播给下游的所有task, 大数据平均分配,然后再join operator内部做hash join, 这样的cost是最低的 。Flink为什么不能做到这样的优化呢?如果使用Flink API (而不是 SQL) 情况会好吗?
3.3 分析问题设置断点
初步的感觉是Flink-optimizer 并没有做到这样的优化: 当join的两个数据源大小悬殊时, 小数据集广播,大数据集均分的输入给join operator 。Flink这么常用的优化都没做到吗?
让我们通过debug Flink-optimizer 代码, 看看他时怎么将本例的join input的ShipStrategy优化成HashPartition 吧。
3.3.1. 首先,准备调式环境
下载例子代码,然后编译,package 成flink-arch-debug-0.0.1.jar, 然后下载flink-1.6.1 的代码,编译, 按照图-13设置flink-client的运行选项。
program arguments 设置为 run flink-arch-debug-0.0.1.jar normal sql, 使用 "normal ","sql" 方式, 如下:
C:projectsflink-arch-debug argetflink-arch-debug-0.0.1.jar normal sql
3.3.2. 然后,了解ShipStrategy
Flink Optimizer 的优化过程(参考Optimizer::compile方法)大概是:
首先将利用GraphCreatingVisitor 将Flink API (API, Table, 或 SQL) 产生的Plan翻译成dag 包里的OptimizerNode和DagConnection组成图,
然后从图的SinkNode(一个或多个)先前递归的调用getAlternativePlans方法从产生最优的Plan , 最优的Plan 是由plan包里的PlanNode和Channel组成的Graph 。ShipStratigy是channel的一个属性, 它描述数据从一个operator以那种方式发布到RP中的RS中的。
最后由JobGraphGenerator将最优图翻译成JobGraph
那么有多少种ShipStrategy呢? 连续按两下SHIFT, 再键入类名(ShipStategyType.java)。参考一下本文最后面的IntelliJ的常用键吧.
public enum ShipStrategyType { FORWARD(false, false), //数据按原分区号传递到本地运行的Task相同分区,不跨网络,不需要比较器(用于排序或Hash) PARTITION_RANDOM(true, false),//数据随机传递到本地运行的Task任意分区,不跨网络,不需要比较器
PARTITION_HASH(true, true),//数据按照指定键值的Hash决定分区,到目标Task需要跨网络传递,需要比较器
PARTITION_RANGE(true, true),//数据按照指定键值的排序顺序决定分区,到目标Task需要跨网络传递,需要比较器
BROADCAST(true, false) // 将数据复制到任意一个分区中,不需要比较器
PARTITION_FORCED_REBALANCE(true, false), // 将数据平均到各个分区中,不需要比较器
PARTITION_CUSTOM(true, true); // 将数据按用户指定的分区器分配分区,不需要比较器
... |
表-4 ShipStrategyType
搜索一下PARTITION_HASH, 看谁将它设置给最优图的Channel 对象, 过滤一下,应该由两个地方:
一个是TwoInputNode::setInput 方法中, 它根据join operator 的JoinHint 或 Parameters 来设置 input Channel的ShipStrategy 。 比如, 如果想让join的第一个input(Currencies)用广播方式传递, 就可使用”BROADCAST_HASH_FIRST“ hint, 或者将这样的参数"INPUT_LEFT_SHIP_STRATEGY"="SHIP_BROADCAST"传递给join operator 。不过这些都只能在Flink Java API中 使用, (具体参考flink-arch-debug中的ApiJointTest类),无法在SQL API 中使用。
第二个在TwoInputNode::getAlternativePlans中。如前文所述, getAlternativePlans首先会 OptimizerNode (本例中主要是JoinNode) 节点用于产生多个plan , 每个 plan的输入输出的节点都是相同, 不同的是边上ShipStrategy 。对于每个Plan , getAlternativePlans都会调用RequestedGlobalProperties::parameterizeChannel从而设置这个Plan的InputChannel的ShipStrategy 。
在SQL application 中, 用户无法像在使用Java API 时那样通过设置JoinHint或Parameter 来选择想要的ShipStategy , 实际上如果指定了这两项中的任意一个,也等同于跳过了getAlternativePlans (优化过程)。 因为既然用户已选择了想要的ShipStategy,就没有必要用Optimizer 根据计算每个方案的cost 来选择最优方案了。 可是即使是由Optimizer 来选择, 对于本例(小数据集join大数据集), 根据表-4 ShipStrategyType的 定义,PARTITION_HASH的cost 肯定不是最低的 。对于大数据集 (instruments), 如果采用PARTITION_HASH将数据传递给下游, 网络cost 必然是很高的, 因为PARTITION_HASH是一个shuffule 的过程, 下游 必然有位于不同TM远程Task , 因此网络传递的cost 必然很高。 看看Flink 怎么定义Cost 和怎么估计cost 的?
public class Costs implements Comparable<Costs>, Cloneable {
private double cpuCost; // 本节点算法在计算中使用CPU 的costs, 比如Hash, sort , merage, etc
|
表-5 Cost定义
根据表-5 Flink cost的定义, 一个节点(比如JoinNode)的cost ,包括上游数据由上游传递过来的network cost, 数据本地缓存的 disk cost, 还有算法的cpu cost 。 图-17第二条边(Instrments)使用的HASH_PARTITION策略肯定比FORWARD cost高很多, 因为如果使用FORWARD 的network cost 为0 (参考表-4的定义),diskCost和cpuCost 跟算法有关(比如使用HashTable或sort merage 去做join)。 第一条边(Currencies)使用的HASH_PARTITION相比BROADCAST, cost 肯定低一些, 但是Currencies数据源 数量特别小, 它的cost 和 这两个cost 之间的差别 在Instrments引起的cost面前都可以忽略不记。所以感觉上 HH(两边都是HASH_PARTITION)和BF(currency 边Broadcuast, instrument边Forward)相比, BF方案的cost一定低很多。 但为什么getAlternativePlans没有选择 BF呢?JoinNode没有给出BF的选择权吗?看看JoinNode::getDataProperties()的代码:
private List<OperatorDescriptorDual> getDataProperties(InnerJoinOperatorBase<?, ?, ?, ?> joinOperatorBase, JoinHint joinHint, switch (joinHint) {
} |
表-6 JoinNode的输入节点要求的属性
从表-6 JoinNode的输入节点要求的属性可知, 但由Optimizer 来决定(OPTIMIZER_CHOOSES)输入节点的ShipStrategy(输出分区策略)时, JoinNode对上游的要求时非常宽泛的,几乎就是什么都行 。
SortMergeInnerJoinDescriptor(this.keys1, this.keys2),HashJoinBuildFirstProperties(this.keys1, this.keys2),HashJoinBuildSecondProperties(this.keys1, this.key),
实际上就是他们为JoinNode和它的input定义了三类需求 :
第一, Join算法可是时Sort-merge, 或者用一路输入做HashTable的HashJoin ,或者用二路输入做HashTable的HashJoin
第二, 第一路第二路输入的partition 策略: 也就是所谓的RequestGlobalPropertities, 可以是RANDOM_PARTITIONED (对应FORWARD shipStategyType),或者HASH_PARTITIONED(PARTITION_HASH),或者FULL_REPLICATION(对应BROADCAST),
或者ANY_PARTITIONING(它是一个通配策略,意思是RANDOM or HASH都可以)
第三,输入的排序策略 :就是所谓的RequestGlobalPropertities, 排序或者不排序。
想一想这三类需求的可选项组合起来,一共会有多少组合? 弄个表, 描述一下可能更清楚些。
| 序号 | Input1 的
partition 备选 策略 |
Input2 的
partition 备选 策略 |
算法 | Input1/Input2 的 排序备选策略 | 兼容性 | network Cost |
1 |
FORWARD |
HASH |
SortMergeInnerJoin |
sort/sort | yes | |
2 |
FORWARD |
HASH |
HashJoinBuildFirst |
sort/sort | yes | |
3 |
FORWARD |
HASH |
HashJoinBuildFirst |
not sort/ not sort | yes | |
4 |
FORWARD |
HASH |
HashJoinBuildFirst |
sort/not sort | yes | |
5 |
FORWARD |
HASH |
HashJoinBuildFirst |
not sort /sort | yes | |
6 |
FORWARD |
HASH |
HashJoinBuildSecond |
sort/sort | yes | |
7 |
FORWARD |
HASH |
HashJoinBuildSecond |
not sort/ not sort | yes | |
8 |
FORWARD |
HASH |
HashJoinBuildSecond |
sort/not sort | yes | |
| 9 |
FORWARD |
HASH |
HashJoinBuildSecond |
not sort /sort | yes |
表-6 GloabalProperties, LocalProperties 和算法的组合
从表-6 可知, 对于input1和input2的partition策略(表-6实际上用的是shipStategy, 他们是1-1对应的)一个组合FH(Forward, Hash ), 一共有9个可以接受的分区-算法-排序的方案,每一种方案都有自己的cost, getAlternativePlans会最后选择cost最低的方案。 除了FH组合, 合法组合还有
HB:Hash-Broadcast
HH:Hash-Hash
BB:Broadcast-Broadcast
BF:Broadcast-Forward
FB:Forward-Broadcast
当然还有HF,FH ,FF,这些都是不合法的,对于join操作会有数据丢失的组合。 6个合法的input1和input2的partition策略组合,根据表-6可以计算, 一共能有6*9=54可互相兼容的分区-算法-排序的组合方案 。实际上如果在TwoInputNode.java:516行上设计断点 (getAlternativePlans方法内)并运行例子程序,
你会发现变量 outputPlans里有90个备选方案,那么其中36个一定是重复和多徐的。
那么, BF方案是既然在备选方案里,而且它的cost理论上是最低的, 而且getAlternativePlans的算法是选择cost最低方案, 为什么cost并不低的HH方案最终被选择了 ? 答案只能有一个 : cost estimation有问题。
3.3 发现问题和给出解决方案
不贴Cost, CostEstimiator, DefualtCostEstimator (costs包的三个类)的代码了。总起来所, CostEstimator 是根据OptimizerNode 的 estimatedOutputSize 成员变量(包括本节点和数据节点的)来计算 network和disk cost 的 , estimatedOutputSize是由节点成员函数computeOperatorSpecificDefaultEstimates()设定, 可以参考DataSourceNode中该函数的实现:estimatedOutputSize 被设置成来自于InputFormat的数据源实际物理尺寸。 可是FlatMapNode, MapNode 只是简简单单的设置了estimatedNumRecords (使之同 source的 一样),而并没有计算estimatedOutputSize 。
重看一下图-4的ExcutionGraph可知, Join的第一个input是FlatMap , 如果Flatmap没有estimatedOutputSize 会导致它的下一个节点JoionNode无法计算cost. 请参考DefualtCostEstimator::addHybridHashCosts()的实现, 当上游的estimatedOutputSize为负数(Unknown)时,本节点的cost为被设置为Unknown 。Unknown cost在选择cheapest cost的plan时是不能做比较的, 只能依靠假设的Cost (如heuristicNetworkCost ), 这个东西很不靠谱, 同时也是HH方案被选上的原因。
解决方案应该修改Flink代码在FlatmapNode::computeOperatorSpecificDefaultEstimates 加上对estimatedOutputSize的估计(比如保持和上游相同, 或加一个discount), 或者修改DefualtCostEstimator 使之 在计算Cost时能通过estimatedNumRecords估计estimatedOutputSize (下策, 没有 前者好)。 总之,Flink Optimizter 在 Cost Estimation 做的不够好, 改善是应该的, 我刚刚看了Flink 1.9 (最新版)的 Optimizer , 这一块还是没有修改。突然还有加入Flink community 的冲动。
如果不想修改 Flink 源码, 或改了也无法发布, 那就看看有没有替换方案了。
... |
表-7 FullyReplicated DataSource 。
这段代码表示如果上游节点是一个FullyReplicated DataSource , 那么就不需要备选方案的选择过程, 直接将这个输入边的shipStagy 设置为Forward 。 FullyReplicated DataSource意思是, 这个Data Source 的每个Parition输出的都是数据源的全集 而不是不部分。那么只需要将Currencies做成这种数据源,问题不就解决了吗?!
虽然ShipStategy是Forward, 但实际下游(Join Node)的每一个Task都得到了Currencies的这个数据集的全集, 这个同Broadcast的效果是一样的。而且第一路为F的组合有FF, FB , FH , 选择的范围小了。 这不对阿,前面不是说FF, FH, HF是不合法的吗? 要注意此时的F是由于FullyReplicated DataSource而既决定的F,不是普通的Forward , 是合法的。FF, FB , FH产生了27种可选方案(参考表-6), 根据heuristicNetworkCost , FF是cost最低的。 那肯定是最低的阿, Forward的数据都是本地传输的, network cost 是 0 。
下面就是如何将Currencies做成FullyReplicated DataSource了, 根据DataSourceNode.java:92, DataSource 的InputFormat只要是ReplicatingInputFormat, 则就是FullyReplicated 。在看看ReplicatingInputFormat的代码, 只需要将原有的InputFormat (比如CsvInputFormat)外面包一层ReplicatingInputFormat就可以了, 具体的看例子的代码吧 : SqlJoinTest.java:95。运行结果如下。

图-18 flink-webmonitor 上FullyReplicated Currencies, 每一个partition都输出数据集的全部, 492条记录。

图-19 flink-webmonitor 上instrument , 跟之前没什么区别。

图-20 flink-webmonitor 上的join , 数据在各个并行Task上非常均衡。
虽然这个例子只用到了Flink-client上的知识, 并没有与JM和TM联合调试, 但是问题的发现,分析和解决的方法是一样的。 都是需要根据对架构的认识,缩小怀疑的范围,然会反复阅读和调式相关代码,找到问题,以及找到解决方案, 试想一下,如果没有架构的知识,你怎么能够怀疑这一定是Flink-optimizer的问题呢? 而且有时解决问题的方法并不一定是直接修改的出问题的代码(当然这样是最好的方案),根据相关代码找到一个合适的替代方案也是解决问题的方法。
没有想到描述一个这样的小问题,这一章运用这么长的篇幅, 对于复杂的问题,简直能写本书了。希望抛砖引玉,能够运用这样的方法学来解决使用Flink遇到的问题: 架构->缩小范围->阅读和调式代码->发现和分析问题->找到解决方案。
3.4. IntelliJ的常用键
CTRL+ALT+Enter to complete line
SHIFT+SHIT search class in source code
CTRL+SHIFT+F serarch string in soruce code
Alt + F1 show current java in project view
CTRL+ALT+B navigate to implementation classes
CTRL+U navigate to super method
ALT + F7 Show reference
ALT + 4 Show run window
ALT + F12 Show terminal window
ALT+Enter Create A testClass
ALT+Insert TestMethod
CTRL+home move to file start
CTRL+end move to file end
参考
Flink conference Page: https://cwiki.apache.org/confluence/display/FLINK/Flink+Internals
很不错的Blog: https://www.cnblogs.com/bethunebtj/p/9168274.html
Flink1.6 documentation: https://ci.apache.org/projects/flink/flink-docs-release-1.6/
Flink Github: https://github.com/apache/flink