功能:将数据进行离散化
可参见博客:https://blog.csdn.net/missyougoon/article/details/83986511 , 例子简易好懂
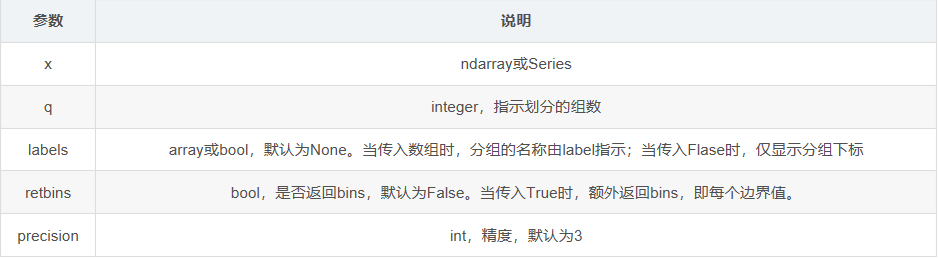
1、pd.cut函数有7个参数,主要用于对数据从最大值到最小值进行等距划分
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
参数:
x : 输入待cut的一维数组
bins : cut的段数,一般为整型,但也可以为序列向量(若不在该序列中,则是NaN)。
right : 布尔值,确定右区间是否开闭,取True时右区间闭合
labels : 数组或布尔值,默认为None,用来标识分后的bins,长度必须与结果bins相等,返回值为整数或者对bins的标识
retbins : 布尔值,可选。是否返回数值所在分组,Ture则返回
precision : 整型,bins小数精度,也就是数据以几位小数显示
include_lowest : 布尔类型,是否包含左区间

cut将根据值本身来选择箱子均匀间隔,即每个箱子的间距都是相同的。
>>> factors = np.random.randn(9)
[ 2.12046097 0.24486218 1.64494175 -0.27307614 -2.11238291 2.15422205 -0.46832859 0.16444572 1.52536248]
传入bins参数
>>> pd.cut(factors, 3) #返回每个数对应的分组 [(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]] Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]] >>> pd.cut(factors, bins=[-3,-2,-1,0,1,2,3]) [(2, 3], (0, 1], (1, 2], (-1, 0], (-3, -2], (2, 3], (-1, 0], (0, 1], (1, 2]] Categories (6, interval[int64]): [(-3, -2] < (-2, -1] < (-1, 0] < (0, 1] (1, 2] < (2, 3]] >>> pd.cut(factors, 3).value_counts() #计算每个分组中含有的数的数量 Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]] (-2.117, -0.69] 1 (-0.69, 0.732] 4 (0.732, 2.154] 4
传入lable参数
>>> pd.cut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示 [c, b, c, b, a, c, b, b, c] Categories (3, object): [a < b < c] >>> pd.cut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标 [2 1 2 1 0 2 1 1 2]
传入retbins参数
>>> pd.cut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值 ([(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]] Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]], array([-2.11664951, -0.69018126, 0.7320204 , 2.15422205]))
2、pd.qcut函数,按照数据出现频率百分比划分,比如要把数据分为四份,则四段分别是数据的0-25%,25%-50%,50%-75%,75%-100%,每个间隔段里的元素个数都是相同的。
pd.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise') #最后一个参数 duplicates='drop'表示若有重复区间则删除
qcut是根据这些值的频率来选择箱子的均匀间隔,即每个箱子中含有的数的数量是相同的。
传入q参数
>>> pd.qcut(factors, 3) #返回每个数对应的分组 [(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]] Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154]] >>> pd.qcut(factors, 3).value_counts() #计算每个分组中含有的数的数量 (-2.113, -0.158] 3 (-0.158, 1.525] 3 (1.525, 2.154] 3
传入lable参数
>>> pd.qcut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示 [c, b, c, a, a, c, a, b, b] Categories (3, object): [a < b < c] >>> pd.qcut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标 [2 1 2 0 0 2 0 1 1]
传入retbins参数
>>> pd.qcut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值 [(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]] Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154],array([-2.113, -0.158 , 1.525, 2.154]))
另一个例子:
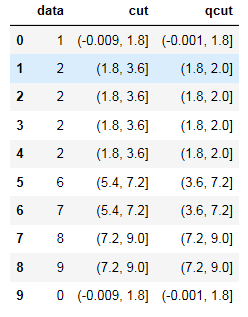
import numpy as np from numpy import * import pandas as pd df = pd.DataFrame() df['data'] = [1,2,2,2,2,6,7,8,9,0]#这里注意箱边界值需要唯一,不然qcut时程序会报错 df['cut']=pd.cut(df['data'],5) df['qcut']=pd.qcut(df['data'],5) df.head(10)
运行结果如图:
可以看到cut列各个分段之间间距相等,qcut由于数据中‘2’较多,所以2附近间距较小,2之后的分段间距较大。