基于redis 5.0.6
先列个表格
| 类型 | 实现 | |
|---|---|---|
| string | sds | |
| list | quicklist | |
| set | intset | hashtable |
| zset | ziplist | skiplist+hashtable |
| hash | ziplist | hashtable |
string
redis的string(字符串)实现称为SDS(Simple Dynamic String,简单动态字符串)
相比于C字符串的优点:sds获取字符串长度的时间复杂度为 O(1) ;字符串不会溢出;减少修改字符串长度时的内存分配次数;二进制安全(可以保存各种格式的编码);兼容sting.h …
// SDS实现 --sds.h
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* buf[]已使用的长度,也就是字符串长度 */
uint8_t alloc; /* buf[]的大小 */
unsigned char flags; /* 标志位,定义sdshdr类型 */
char buf[]; /* 存储字符串的数组 */
};
画个sds的结构图:

list
redis的list实现称为quicklist(快速列表),quicklist属于双端链表
使用quicklist的优点:保证性能的同时不会有太大的内存浪费
quicklist的节点包含了ziplist(压缩列表)。ziplist没有被定义为struct,而是char[],结构紧凑。
由于ziplist的结构紧凑,所以每新增元素都需要realloc扩展内存空间。当ziplist过大时realloc会重新分配内存空间,并进行拷贝,损耗性能。所以ziplist不适用于存储太大太多的元素。
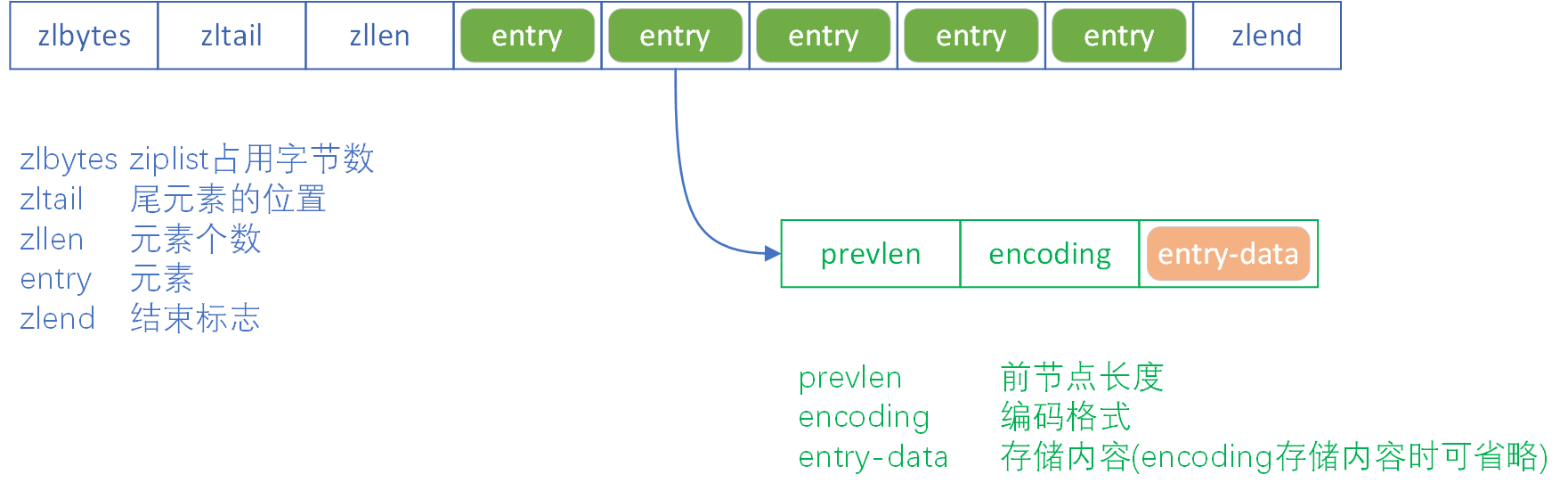
// ziplist定义 --ziplist.c
/*
* <zlbytes --ziplist占用字节数> <zltail --尾元素的位置> <zllen --元素个数> <entry --元素> <entry --元素> ... <entry --元素> <zlend --结束标志>
*/
ziplist节点中的prevlen指前节点的长度,能很方便地从当前节点定位到前一个节点
// ziplist节点定义 --ziplist.c
/*
* <prevlen --前节点长度> <encoding --编码格式> <entry-data --存储数据>
*/
画个ziplist的结构图:
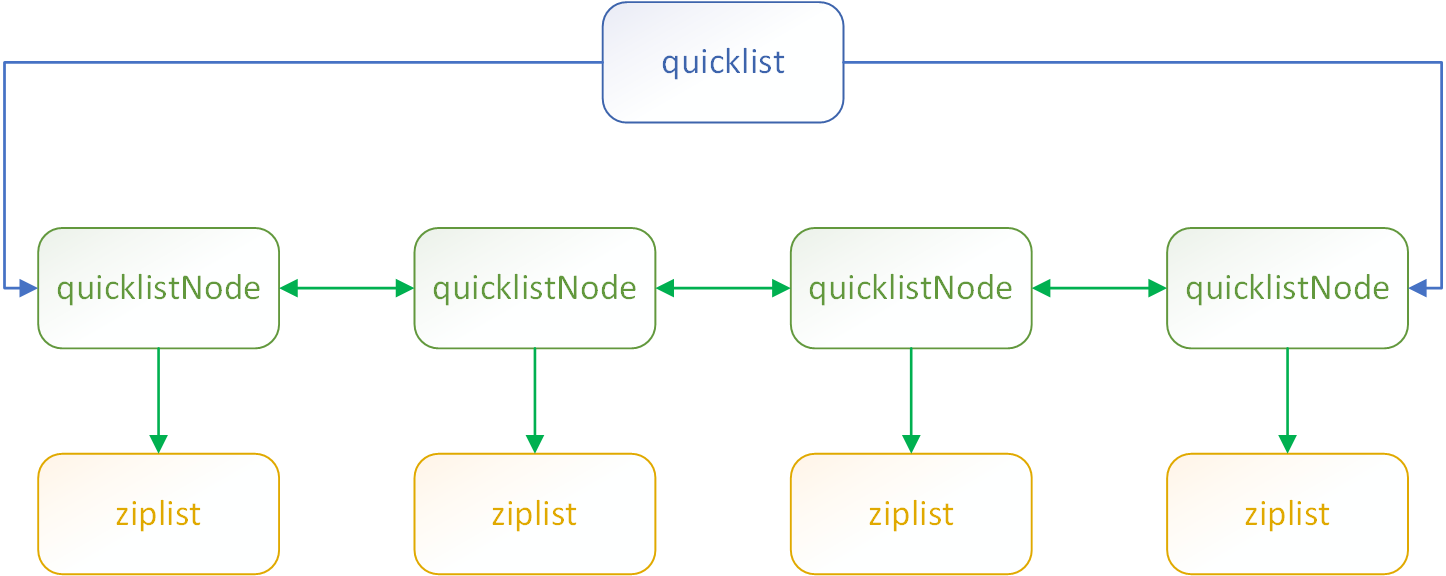
quickList也可以看作是ziplist的链表
// quicklist定义 --quicklist.h
typedef struct quicklist {
quicklistNode *head; /* 头节点指针 */
quicklistNode *tail; /* 尾节点指针 */
unsigned long count; /* 元素总数(所有ziplist中的所有元素) */
unsigned long len; /* quicklist节点数 */
int fill : 16; /* 节点的填充因子 */
unsigned int compress : 16; /* LZF算法的压缩深度; 0=off */
} quicklist;
// quicklist节点定义 --quicklist.h
typedef struct quicklistNode {
struct quicklistNode *prev; /* 前驱指针 */
struct quicklistNode *next; /* 后驱指针 */
unsigned char *zl; /* ziplist */
unsigned int sz; /* ziplist的bytes大小*/
unsigned int count : 16; /* ziplist中的元素数量 */
unsigned int encoding : 2; /* 是否进行LZF压缩 RAW==1 or LZF==2 */
unsigned int container : 2; /* 是否包含ziplist NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* 是否曾被压缩 */
unsigned int attempted_compress : 1; /* 测试使用字段 */
unsigned int extra : 10; /* 预留内存空间 */
} quicklistNode;
// 经过LZF压缩的quicklist节点定义 --quicklist.h
typedef struct quicklistLZF {
unsigned int sz; /* 压缩后的char[]大小 */
char compressed[]; /* 存储压缩后内容的数组 */
} quicklistLZF;
// 描述quicklist中的元素定义 --quicklist.h
typedef struct quicklistEntry {
const quicklist *quicklist; /* 元素所在的quicklist */
quicklistNode *node; /* 元素所在的quicklist节点 */
unsigned char *zi; /* 元素所在的ziplist */
unsigned char *value; /* 元素值 */
long long longval; /* 元素值 */
unsigned int sz; /* 元素值的bytes大小*/
int offset; /* 当前元素在节点中的偏移量 */
} quicklistEntry;
画个quicklist的结构图:
hash
redis的hash实现分为ziplist(压缩列表)和dict(字典)。ziplist在上文已经提到。
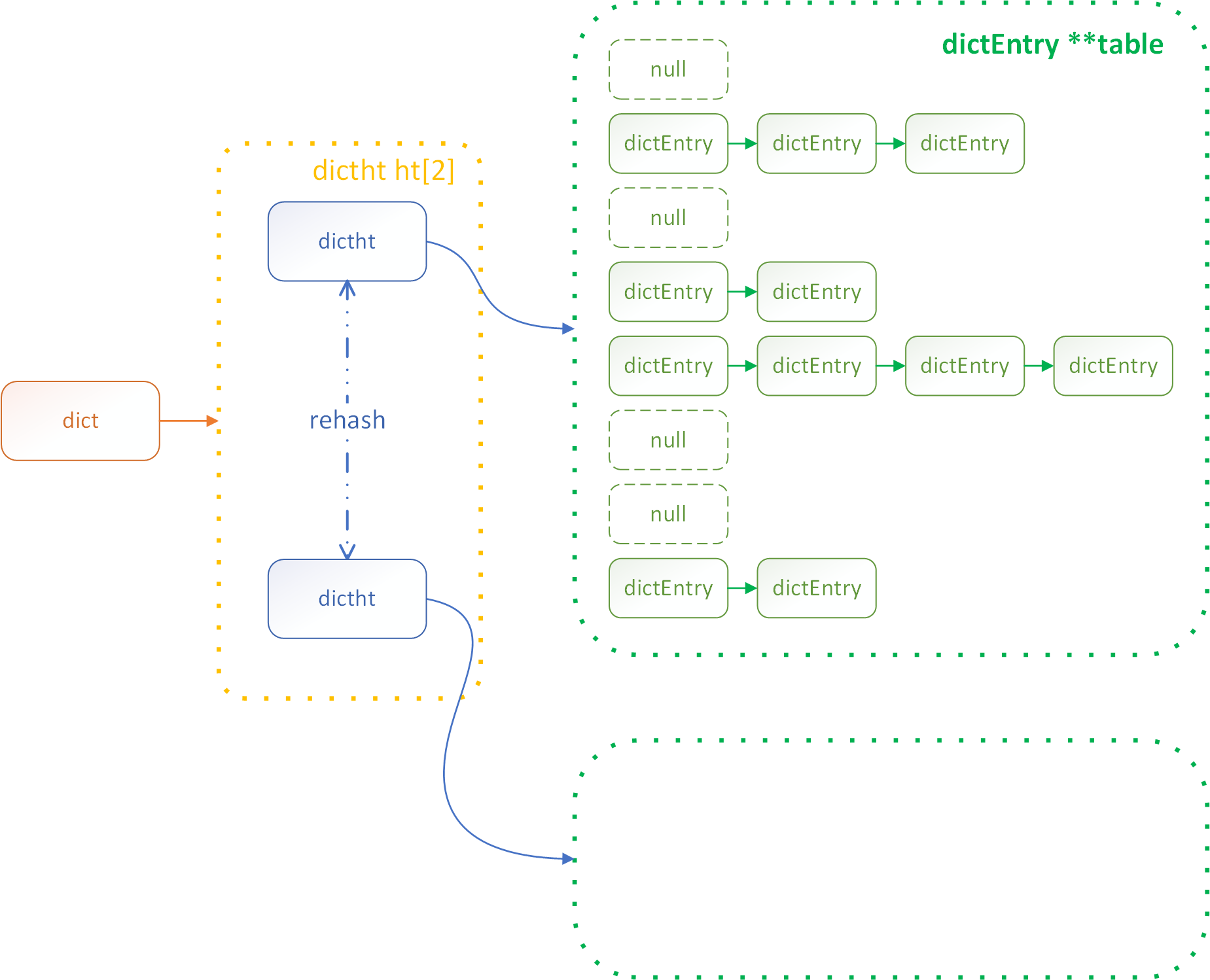
dict使用了hashtable哈希表的二维结构。redis数据库中的key/value组成了全局dict,包括带过期时间的key集合、zset中的value和score映射也使用了dict。
dict使用链地址法解决hash冲突,需要扩容/缩容时执行渐进式rehash。
// dict中的节点定义 --dict.h
typedef struct dictEntry {
void *key; /* 节点的键 */
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; /* 节点的值 */
struct dictEntry *next; /* 指针链接到下一个节点 */
} dictEntry;
// dict具体结构定义 --dict.h
typedef struct dictht {
dictEntry **table; /* 二维结构 数组+链表 */
unsigned long size; /* table[]大小 */
unsigned long sizemask; /* table[]大小的掩码 size-1(用以计算索引值) */
unsigned long used; /* 节点个数 */
} dictht;
redis在执行rehash时:
- 为ht[1]开辟空间,rehashidx赋值0,开始从*table[0]开始将ht[0]的数据rehash至ht[1]
- 随着rehashidx自增,对table[rehashidx]进行rehash。在rehash期间,对disc的写操作会同时作用于ht[0]和ht[1]
- ht[0]的数据全部rehash至ht[1]时,rehash完成。rehashidx赋值-1
- 将ht[1]赋值给ht[0],清空ht[1]
// dict定义 --dict.h
typedef struct dict {
dictType *type; /* 保存私有方法的对象指针 */
void *privdata; /* 私有数据 */
dictht ht[2]; /* 每个dict包含两个dictht,用来rehash */
long rehashidx; /* 执行rehash的索引,没有rehash时为-1 */
unsigned long iterators; /* 运行时的迭代器数 */
} dict;
画个dict的结构图:
set
redis的set实现分为intset(整数集合)和dict(字典)。dict在上文已经提到。当使用dict实现set时,字典的field为元素,value为NULL。
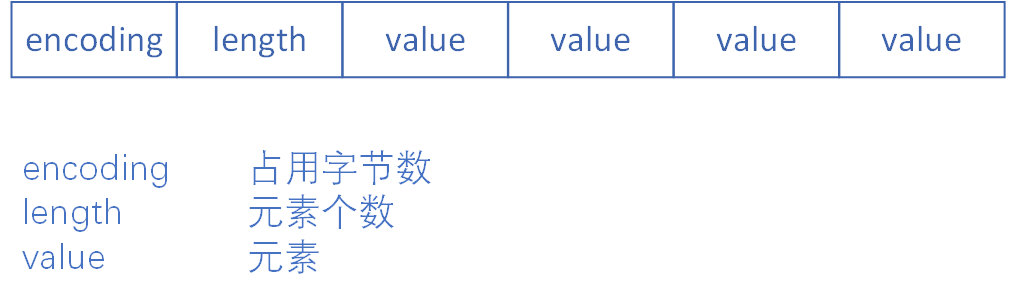
intset数据结构比较简单。contents[]存储了所有int元素,它的真正类型取决于encoding,而不是申明的int8_t。
当添加的新元素int类型位宽大于原intset中的元素时,redis会对intset升级操作,如将encoding的INTSET_ENC_INT32变为INTSET_ENC_INT64,并且需要重新分布contents[]中元素的位置。
// intset定义 --intset.h
typedef struct intset {
uint32_t encoding; /* contents[]的编码,决定int的位宽:16位、32位、64位 */
uint32_t length; /* intset元素个数 */
int8_t contents[]; /* 存储元素的int8_t数组,可以存储16/32/64位的int */
} intset;
画个intset的结构图:
zset
redis的zset实现分为ziplist(压缩列表)和skiplist(跳跃列表)+dict(字典)。ziplist在上文已经提到。当有zset的元素少于zset-max-ziplist-entries(默认128),同时每个元素的值都小于zset-max-ziplist-value(默认64字节)时,redis会使用ziplist。当使用ziplist实现zset时,每个元素使用两个ziplist节点保存,第一个保存member,第二个保存score。
画个zset使用ziplist的图:

skiplist是一种简单、高效、动态、随机化算法的搜索结构。它的平均搜索时间复杂度O(lgN),最坏O(N)。关于skiplist的数据结构建议参考MIT算法导论公开课第12节。
// skiplist节点定义 --server.h
typedef struct zskiplistNode {
sds ele; /* 元素的值 */
double score; /* 元素的分数 */
struct zskiplistNode *backward; /* 后退指针 */
struct zskiplistLevel {
struct zskiplistNode *forward; /* 链接层与层的前驱指针 */
unsigned long span; /* 路径跨度,搜索元素时累加span可得到rank排名 */
} level[]; /* skiplist的层 */
} zskiplistNode;
// skiplist定义 --server.h
typedef struct zskiplist {
struct zskiplistNode *header, *tail; /* skiplist的头、尾节点 */
unsigned long length; /* 跳跃表长度/节点数(不包括头节点)、也就是元素数量 */
int level; /* skiplist的层数 */
} zskiplist;
skiplist保证范围型查找的性能 O(lgN),dict保证成员分值查找的性能 O(1)
// skiplist实现的zset定义 --server.h
typedef struct zset {
dict *dict; /* dict指针 */
zskiplist *zsl; /* skiplist头节点指针 */
} zset;
##### 参考 * redis-5.0.6 源码 * 《Redis设计与实现》 * 《Redis深度历险 核心原理与应用实践》