一、ElasticSearch概述
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是<mark>通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单</mark>。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便lava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索…..
谁在使用:
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐/2
2、The Guardian (国外新闻网站) ,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论) +社交网络数据(对某某新闻的相关看法) ,数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow (国外的程序异常讨论论坛) , IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub (开源代码管理),搜索 上千亿行代码
5、电商网站,检索商品
6、日志数据分析, logstash采集日志, ES进行复杂的数据分析, ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
8、BI系统,商业智能, Business Intelligence。比如说有个大型商场集团,BI ,分析一下某某区域最近3年的用户消费 金额的趋势以及用户群体的组成构成,产出相关的数张报表, **区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开-个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
9、国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门
的一一个使用场景)
ES和Solr
ElasticSearch简介
- Elasticsearch是一个实时分布式搜索和分析引擎。 它让你以前所未有的速度处理大数据成为可能。
- 它用于<mark>全文搜索、结构化搜索、分析</mark>以及将这三者混合使用:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。Github使用Elasticsearch检索1300亿行的代码。- 但是Elasticsearch不仅用于大型企业,它还让像
DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。 - Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
- Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域, Lucene可被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是, Lucene只是一个库。 想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是, Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是<mark>通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。</mark>
二、ElasticSearch安装
JDK8,最低要求
使用Java开发,必须保证ElasticSearch的版本与Java的核心jar包版本对应!(Java环境保证没错)
这里在windows上进行安装
Windows下安装
1、安装
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
1、目录
安装包解压后的目录
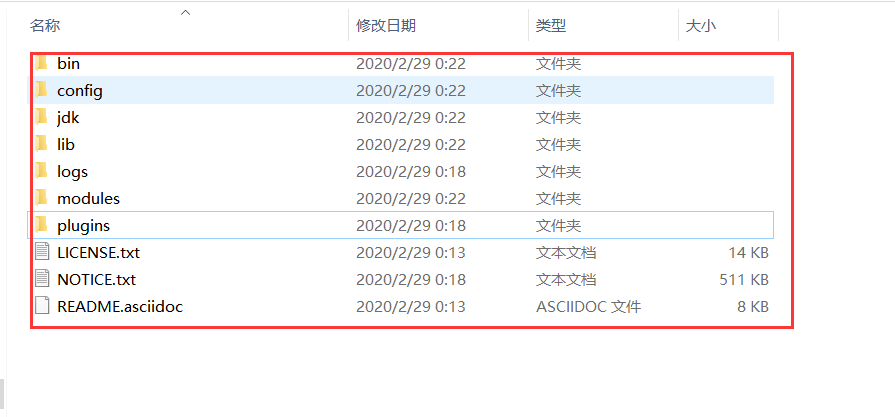
bin 启动文件目录config 配置文件目录1og4j2 日志配置文件jvm.options java 虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整)elasticsearch.ym1 elasticsearch 的配置文件! 默认9200端口!跨域!1ib相关jar包modules 功能模块目录plugins 插件目录ik分词器
3.启动
bin 目录下双击.bat 文件 就可以启动 http:licalhost:9200
安装可视化界面
elasticsearch-head
使用前提:需要安装nodejs
1、下载地址
https://github.com/mobz/elasticsearch-head
2、安装
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
3、启动
cd elasticsearch-head# 安装依赖npm install# 启动npm run start# 访问http://localhost:9100/
安装kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
1、下载地址:
下载的版本需要与ElasticSearch版本对应
https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
2、安装
解压即可
3.启动
访问
localhost:5601
5、kibana汉化
编辑器打开kibana解压目录/config/kibana.yml,添加
i18n.locale: "zh-CN"
重启kibana
三、ElasticSearch核心概念
概述
1、索引(ElasticSearch)
- 包多个分片
2、字段类型(映射)
- 字段类型映射(字段是整型,还是字符型…)
3、文档
4、分片(Lucene索引,倒排索引)
ElasticSearch是面向文档,关系行数据库和ElasticSearch客观对比!一切都是JSON!
Relational DB ElasticSearch 数据库(database) 索引(indices) 表(tables) types \<慢慢会被弃用!> 行(rows) documents 字段(columns) fields elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个人就是一个集群! ,即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的顺序找到它:索引 => 类型 => 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
文档(”行“)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象 ! fastjson进行自动转换 !}
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
- elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引(“库”)
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
四、IK分词器(elasticsearch插件)
IK分词器:中文分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一一个匹配操作,默认的中文分词是将每个字看成一个词(<mark>不使用用IK分词器的情况下</mark>),比如“我爱狂神”会被分为”我”,”爱”,”狂”,”神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:
ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分!1、下载
版本要与ElasticSearch版本对应
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2、安装
ik文件夹是自己创建的
加压即可(但是我们需要解压到ElasticSearch的plugins目录ik文件夹下)
6、添加自定义的词添加到扩展字典中
elasticsearch目录/plugins/ik/config/IKAnalyzer.cfg.xml
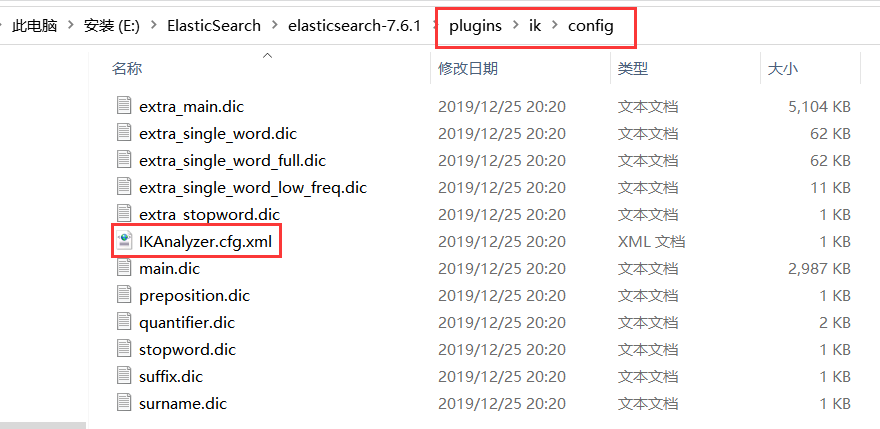
打开 IKAnalyzer.cfg.xml 文件,扩展字典
创建字典文件,添加字典内容
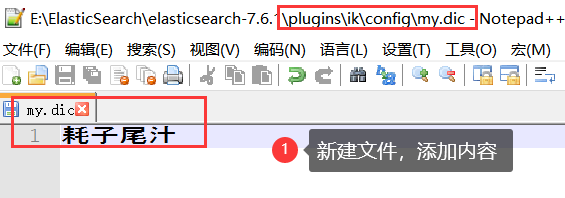
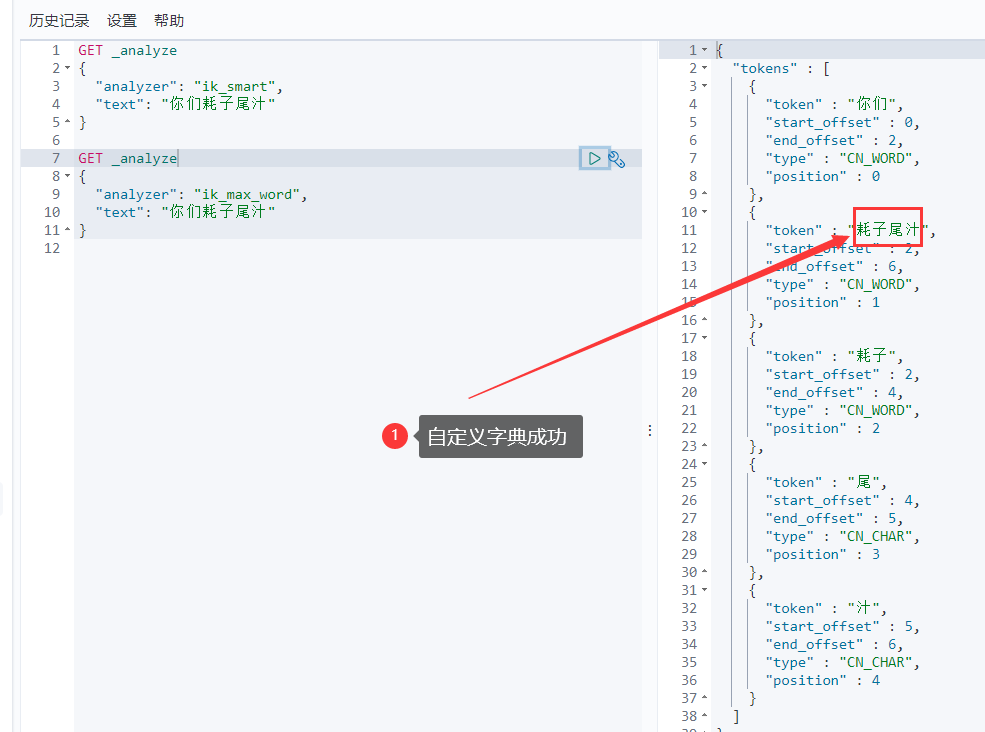
重启ElasticSearch,再次使用kibana测试
查询所有
GET _search
{
"query": {
"match_all": {}
}
}
不使用分词器
GET _analyze
{
"analyzer": "ik_smart",
"text": "年轻人不讲武德"
}
使用ik分词器
GET _analyze
{
"analyzer": "ik_max_word",
"text": "年轻人不讲武德"
}
建立第一个索引
创建 /索引名称/类型的名称/文档的id
{当前id的内容} 不指定字段的类型 elasticsearch会自动的判断字段的类型
PUT /test1/type1/1
{
"name":"敖克尚",
"age":"23",
"addr":"2312312"
}
添加索引 指定索引中字段的类型
PUT /test2
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"birthday":{
"type":"date"
}
}
}
}
获取当前索引名称索引类型 文档id为1 的信息
GET test1/type1/1
获取文档名称为test2 的索引信息
GET test2
PUT /test3/_doc/5
{
"name":"赵刘",
"age":"26",
"barthday":"2022-10-1"
}
GET test3/
当前的索引文档id如果存在就是修改当前文档的信息 可能会有数据被丢失的情况
PUT /test3/_doc/1
{
"name":"lisi"
}
当前的修改文档数据的方式不会造成数据丢失
POST /test3/_doc/5/_update
{
"doc":{
"name":"哈哈哈",
"age":"26"
}
}
删除索引
DELETE /test1
查询当前索引下的数据信息
GET test3/_doc/_search
查询test3 索引下 name含有深圳市的数据
GET /test3/_doc/_search?q=name:深圳市
扩展:通过get _cat/ 可以获取ElasticSearch的当前的很多信息!
GET _cat/indicesGET _cat/aliasesGET _cat/allocationGET _cat/countGET _cat/fielddataGET _cat/healthGET _cat/indicesGET _cat/masterGET _cat/nodeattrsGET _cat/nodesGET _cat/pending_tasksGET _cat/pluginsGET _cat/recoveryGET _cat/repositoriesGET _cat/segmentsGET _cat/shardsGET _cat/snapshotsGET _cat/tasksGET _cat/templatesGET _cat/thread_pool
高级查询
参考 ElasticSearch7.6入门学习笔记-KuangStudy-文章 笔记
和官方的文档: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/java-rest-high.html 7.6.1 版本
GET /test3/_doc/_search
{
"query":{
"match":{
"name":"赵"
}
},
"_source":["name","age"],
"sort":[
{
"age":{
"order":"asc"
}
}
]
}
GET /test2/_doc/_search
{
"query":{
"match":{
"name":"赵"
}
},
"_source":["name","age"],
"sort":[
{
"age":{
"order":"asc"
}
}
]
}
GET /test3/_doc/_search
{
"query":{
"match":{
"name":"深圳市 赵 王"
}
}
}
GET /test3/_doc/_search
{
"query":{
"match":{
"name":"赵"
}
},
"highlight":{
"pre_tags":"<p class = 'key' style = 'color:red'>",
"post_tags":"</p>",
"fields":{
"name":{}
}
}
}
六、SpringBoot整合
创建springboot项目
注意依赖版本和安装的版本一致
<properties><java.version>1.8</java.version><!-- 统一版本 --><elasticsearch.version>7.6.1</elasticsearch.version></properties>
POM
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.nicong</groupId>
<artifactId>el</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>el</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
configruation
package com.nicong.el.configuration;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElatsicSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")
)
);
return client;
}
}
就可以写简单的操作了:
package com.nicong.el;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class ElApplicationTests {
@Autowired
public RestHighLevelClient restHighLevelClient;
@Test
public void contextLoads() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("test4");
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());// 查看是否创建成功
System.out.println(response);// 查看返回对象
restHighLevelClient.close();
}
}
后面高级的东西再慢慢的记录。。。。
end