学习Django框架之前先了解的知识:
HTTP协议:
所谓协议,就是指双方遵循的规范。http协议,就是浏览器和服务器之间进行“沟通”的一种规范。
学习http协议,主要需要了解http的请求和响应
GET请求只有请求头与请求行,没有请求体,其传递的参数在url后面进行拼接传递
POST请求有请求头、请求行与请求体
下面介绍哪些是请求头、请求行、请求体
首先看看http请求消息
请求行:描述客户端的请求方式、请求资源的名称、http协议的版本号。 例如: GET/BOOK/JAVA.HTML HTTP/1.1
请求头(消息头)包含(客户机请求的服务器主机名,客户机的环境信息等):
Accept:用于告诉服务器,客户机支持的数据类型 (例如:Accept:text/html,image/*)
Accept-Charset:用于告诉服务器,客户机采用的编码格式
Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式
Accept-Language:客户机语言环境
Host:客户机通过这个服务器,想访问的主机名
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间
Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器版本等)
Cookie:客户机通过这个头,将Coockie信息带给服务器
Connection:告诉服务器,请求完成后,是否保持连接
Date:告诉服务器,当前请求的时间
请求体:
就是指浏览器端通过http协议发送给服务器的实体数据。例如:name=dylan&id=110
(get请求时,通过url传给服务器的值。post请求时,通过表单发送给服务器的值)
再看看HTTP响应消息
一个http响应代表服务器端向客户端回送的数据,它包括:
一个状态行,若干个消息头,以及实体内容
响应头(消息头)包含:
Location:这个头配合302状态吗,用于告诉客户端找谁
Server:服务器通过这个头,告诉浏览器服务器的类型
Content-Encoding:告诉浏览器,服务器的数据压缩格式
Content-Length:告诉浏览器,回送数据的长度
Content-Type:告诉浏览器,回送数据的类型
Last-Modified:告诉浏览器当前资源缓存时间
Refresh:告诉浏览器,隔多长时间刷新
Content-Disposition:告诉浏览器以下载的方式打开数据。例如: context.Response.AddHeader("Content-Disposition","attachment:filename=aa.jpg"); context.Response.WriteFile("aa.jpg");
Transfer-Encoding:告诉浏览器,传送数据的编码格式
ETag:缓存相关的头(可以做到实时更新)
Expries:告诉浏览器回送的资源缓存多长时间。如果是-1或者0,表示不缓存
Cache-Control:控制浏览器不要缓存数据 no-cache
Pragma:控制浏览器不要缓存数据 no-cache
Connection:响应完成后,是否断开连接。 close/Keep-Alive
Date:告诉浏览器,服务器响应时间
状态行: 例如: HTTP/1.1 200 OK (协议的版本号是1.1 响应状态码为200 响应结果为 OK)
实体内容(实体头):响应包含浏览器能够解析的静态内容,例如:html,纯文本,图片等等信息
cookie和session
cookie不属于http协议范围,由于http协议无法保持状态,但实际情况,我们却又需要“保持状态”,因此cookie就是在这样一个场景下诞生。
cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上cookie,这样服务器就能通过cookie的内容来判断这个是“谁”了。
cookie虽然在一定程度上解决了“保持状态”的需求,但是由于cookie本身最大支持4096字节,以及cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是session。
问题来了,基于http协议的无状态特征,服务器根本就不知道访问者是“谁”。那么上述的cookie就起到桥接的作用。
我们可以给每个客户端的cookie分配一个唯一的id,这样用户在访问时,通过cookie,服务器就知道来的人是“谁”。然后我们再根据不同的cookie的id,在服务器上保存一段时间的私密资料,如“账号密码”等等。
总结而言:cookie弥补了http无状态的不足,让服务器知道来的人是“谁”;但是cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过cookie识别不同的用户,对应的在session里保存私密的信息以及超过4096字节的文本。
另外,上述所说的cookie和session其实是共通性的东西,不限于语言和框架
1、获取cookie
request.COOKIES.get("islogin",None) #如果有就获取,没有就默认为none
2、设置cookie
obj = redirect("/index/")
obj.set_cookie("islogin",True) #设置cookie值,注意这里的参数,一个是键,一个是值
obj.set_cookie("haiyan","344",20) #20代表过期时间
obj.set_cookie("username", username)
3、删除cookie
obj.delete_cookie("cookie_key",path="/",domain=name)
cookie存储到客户端
优点:数据存储在客户端。减轻服务端的压力,提高网站的性能
缺点:安全性不高,在客户端很容易被查看或破解用户会话信息
session的获取删除和设置和cookie保持一致
补充的差不多了下面我们来介绍Django框架
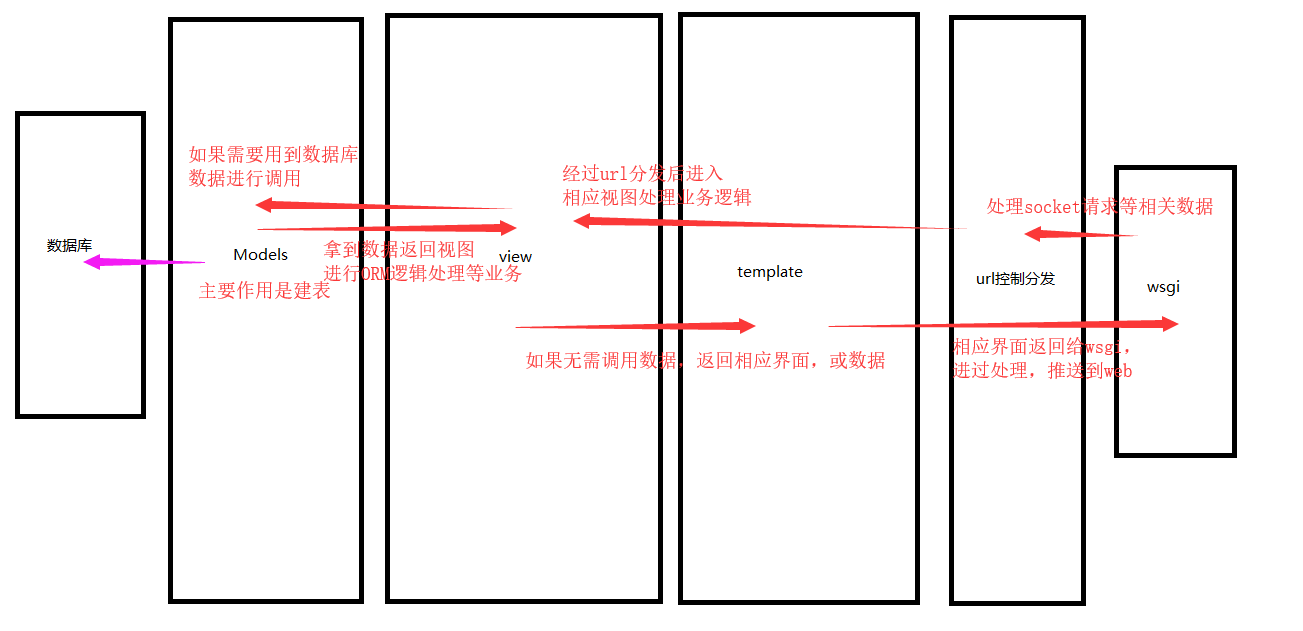
一、MTV模型
Django的MTV分别代表:
Model(模型):和数据库相关,负责业务对象与数据库的对象(ORM)
Template(模板):放所有的html文件
模板语法:目的是将处理完的数据返回前端,嵌入到html页面中
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
另外,Django还有URL分发器。作用是将一个个URL的页面请求分别发给不同的Views处理,Views再调用相应的Model和Template。
二、Django基本命令
1、下载Django:
pip3 install django
2、创建一个Django对象
django-admin.py startproject 项目名称
django-admin.py startproject mysite
3、创建一个应用
python3 manage.py startapp blog(应用名称)
4、启动Django项目
python3 manage.py runserver 8080
5、创建表命令
python3 manage.py makemigrations
python3 manage.py migrate
基本命令差不多就这些,之后也会写到
三、路由配置
urlpatterns = [ url(正则表达式, views视图函数,参数,别名), ] 参数说明: 一个正则表达式字符串 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串 可选的要传递给视图函数的默认参数(字典形式) 一个可选的name参数
正则表达式:可以用正则表达式验证相应的url是否要执行后面的视图函数
需要注意的是:
1、一旦匹配成功则不再继续
2、若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
3、不需要添加一个前导的反斜杠,因为每个URL 都有。
4、每个正则表达式前面的'r' 是可选的但是建议加上。
别名:可以选择给一个url起一个名字,可以用来进行反向解析使用
四、视图函数
视图函数中至少应当会有:
from django.shortcuts import render,HttpResponse,redirect
基本用法:
render:返回request,一个网页,一些处理完成的逻辑返回给前端页面 , 返回一次请求
redirect:进行重定向处理 返回的两次请求,返回一次重定向一次
HttpResponse:可以理解为返回一个新的带有参数的网页,但其本质是返回了一串http网页请求
五、模型层
HTML代码+模板语法
HTML代码:顾名思义,就是网页
模板语法:视图函数返回的一些数据可以由模板语法进行展示
基本语法有:
{{name}} {{for i in 可迭代对象}} {{条件判断语句if else}}
目的是将变量巧妙的嵌入到html页面中
django之反向解析
url:
url(r'^index/$', views.index, name='index'),
在模板中:使用url 模板标签。
<a href="{% url 'index' %}">XXXXXXXX</a>
在Python 代码中:使用django.core.urlresolvers.reverse() 函数。
return HttpResponseRedirect(reverse('index'))
在更高层的与处理Django 模型实例相关的代码中:使用get_absolute_url() 方法。
反向解析的好处:
无论怎么改你要匹配的url,只要你写上了别名。在html使用了模板语法,就会去找别名对应的那个url,以后不管你怎么改url都没事,在python代码中是一样的道理
django之模板语法
什么是模板:只要是在html里面有模板语法就不是html文件了,这样的文件就叫做模板。
模板语法分类:
变量:{{}}
标签:{%......%}
又分为:for标签(循环序号可以用forloop)、for...empty(当循环的组为空或者没有被找到时,进行操作)、if、whit、csrf_token(用于跨站请求伪造保护)
模板语法过滤器:
default、length、filesizeformat(格式化为人类能够读懂的格式化,如:13kb、24mb)、date、slice、truncatechars、safe
自定义标签与过滤器(暂不介绍)
django的ORM操作!重要!重要!非常重要
ORM介绍
映射关系:
表名 ------------>类名
字段------------>属性
表记录--------->类实例化对象
ORM的两大功能:
操作表:
创建表
修改表
删除表
操作数据行:
增删改查
ORM利用pymysql第三方工具链接数据库
Django没办法帮我们创建数据库,只能我们创建完之后告诉它,让django去链接
创建表之前需要知道的一些东西
第一步:自己先创建数据库,如果用的是mysql或者其他非sqlite3的数据库的情况下
第二步:settings配置mysql数据库连接数据
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', #通过这个去链接mysql
'NAME': '数据库名字',
'USER':'数据库用户名',
'PASSWORD':'密码',
'HOST':'localhost',
'PORT':'3306',
}
}
第三步:去相应的应用下的__init__文件加入,比如在school这个app下的__init__文件中加入
import pymysql pymysql.install_as_MySQLdb()
第四步:在model中创建表结构
class Book(models.Model): #必须要继承
name = models.CharField(max_length=32)
最后,一定要进行数据库迁移:
python3 manage.py makemigrations 创建脚本 python3 manage.py migrate 迁移
ORM单表查询
查询相关的操作:
# 查询相关API
# 1、all():查看所有
student_obj = models.Student.objects.all()
print(student_obj) #打印的结果是QuerySet集合
# 2、filter():可以实现且关系,但是或关系需要借助Q查询实现。。。
# 查不到的时候不会报错
print(models.Student.objects.filter(name="Frank")) #查看名字是Frank的
print(models.Student.objects.filter(name="Frank",fenshu=80)) #查看名字是Frank的并且分数是80的
# 3、get():如果找不到就会报错,如果有多个值,也会报错,只能拿有一个值的
print(models.Student.objects.get(name="Frank")) #拿到的是model对象
print(models.Student.objects.get(nid=2)) #拿到的是model对象
# 4、exclude():排除条件
print( models.Student.objects.exclude(name="海东")) #查看除了名字是海东的信息
# 5、values():是QuerySet的一个方法 (吧对象转换成字典的形式了,)
print(models.Student.objects.filter(name="海东").values("nid","course")) #查看名字为海东的编号和课程
#打印结果:<QuerySet [{'nid': 2, 'course': 'python'}, {'nid': 24, 'course': 'python'}]>
# 6、values_list():是queryset的一个方法 (吧对象转成元组的形式了)
print(models.Student.objects.filter(name="海东").values_list("nid", "course"))
#打印结果:< QuerySet[(2, 'python'), (24, 'python')] >
# 7、order_by():排序
print(models.Student.objects.all().order_by("fenshu"))
# 8、reverse():倒序
print(models.Student.objects.all().reverse())
# 9、distinct():去重(只要结果里面有重复的)
print(models.Student.objects.filter(course="python").values("fenshu").distinct())
# 10、count():查看有几条记录
print(models.Student.objects.filter(name="海东").count())
# 11、first()
# 12、last()
return render(request,"test.html",{"student_obj":student_obj})
# 13、esits:查看有没有记录,如果有返回True,没有返回False
# 并不需要判断所有的数据,
# if models.Book.objects.all().exists():
双下划綫之单表查询
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id小于1 且 大于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") #包括ven的 models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and startswith,istartswith, endswith, iendswith
对象可以调用自己的属性,用一个点就可以
还可以通过双下划线。。。
models.Book.objects.filter(price__gt=100) 价格大于100的书
models.Book.objects.filter(author__startwith= "张") 查看作者的名字是以张开头的
主键大于5的且小于2
price__gte=99大于等于
publishDate__year =2017,publishDate__month = 10 查看2017年10月份的数据
修改表记录:
update
删除表记录:
delete(),立即删除,无任何返回值
编辑表中的数据涉及的一些语法:
编辑操作涉及到的语法
分析:
1、点击编辑,让跳转到另一个页面,拿到我点击的那一行
两种取id值的方式
方式一:
利用数据传参数(作为数据参数传过去了)
<a href="/edit/?book_id = {{book_obj.nid}}"></a> #相当于发了一个键值对
url里面就不用写匹配的路径了,
id = request.GET.get("book_id") #取值
方式二:
利用路径传参,得在url里面加上(d+),就得给函数传个参数,无名分组从参数里面取值
<a href="/{{book_obj.nid}}"></a>
2、拿到id,然后在做筛选
id = request.GET.get("book_id")
book_obj = models.Book.objects.filter(nid=id) #拿到的是一个列表对象
注意:
1.取[0]就拿到对象了,,然后对象.属性就可以取到值了
2.用get,你取出来的数据必须只有一条的时候,,如果有多条用get就会报错,,,但是用get就不用加[0]了
book_obj = models.Book.objects.filter(nid=id)[0]
3、当点击编辑的时候怎么让input框里显示文本内容
value = "{{book_obj.title}}"
4、改完数据后重新提交
当提交的时候走action...../edit/}
隐藏一个input,
<input type="hidden" name = "book_id" value="{{book_obj.nid}}">
判断post的时候:
修改数据
方式一:save(这种方式效率是非常低的,不推荐使用,了解就行了)
修改的前提是先取(拿到要编辑的id值)
id = request.POST.get("book_id")
bk_obj = models.Book.objects.filter(nid=id)[0]
bk_obj.title = "hhhhhh" #这是写死了,不能都像这样写死了
bk_obj.save() 只要是用对象的这种都要.save
方式二:update
title = request.POST.get("title")
models.Book.objects.filter(nid=id).update(title=title,......)
跳转到index
如果是post请求的时候怎么找到id呢,
一、如果是数据传参:(也就是get请求的时候)
可以通过一个隐藏的input框,给这个框给一个name属性,value属性。通过request.POST.get("键"),,就可以得到id的值
二、如果是路径传参
可以通过传参的形式,当正则表达式写一个(d+)的时候,就给函数传一个id,可通过这个id知道id.
跨表查询和添加
创建关联表:
创建一对一的关系:OneToOne("要绑定关系的表名")
创建一对多的关系:ForeignKey("要绑定关系的表名")
创建多对多的关系:ManyToMany("要绑定关系的表名") 会自动创建第三张表
关于一些字段选项
1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,
默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices 中的选项。
这是一个关于 choices 列表的例子:
YEAR_IN_SCHOOL_CHOICES = (
('FR', 'Freshman'),
('SO', 'Sophomore'),
('JR', 'Junior'),
('SR', 'Senior'),
('GR', 'Graduate'),
)
每个元组中的第一个元素,是存储在数据库中的值;第二个元素是在管理界面或 ModelChoiceField 中用作显示的内容。
在一个给定的 model 类的实例中,想得到某个 choices 字段的显示值,就调用 get_FOO_display 方法(这里的 FOO 就是 choices 字段的名称 )。例如:
from django.db import models
class Person(models.Model):
SHIRT_SIZES = (
('S', 'Small'),
('M', 'Medium'),
('L', 'Large'),
)
name = models.CharField(max_length=60)
shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES)
>>> p = Person(name="Fred Flintstone", shirt_size="L")
>>> p.save()
>>> p.shirt_size
'L'
>>> p.get_shirt_size_display()
'Large
添加记录:
一对一添加:
# 一对多的添加
# 方式一:如果是这样直接指定publish_id字段去添加值,前提是你的主表里面必须有数据
# 主表:没有被关联的(因为book表是要依赖于publish这个表的)也就是publish表
# 子表:关联的表
models.Book.objects.create(title="追风筝的人",publishDdata="2015-5-8",price="111",publish_id=1)
# 方式二:推荐
pub_obj = models.Publish.objects.filter(name="人民出版社")[0]
print(pub_obj)
models.Book.objects.create(title = "简爱",publishDdata="2000-6-6",price="222",publish=pub_obj)
# 方式三:save
pubObj= models.Publish.objects.get(name="人民出版社") #只有一个的时候用get,拿到的直接就是一个对象
bookObj = models.Book(title = "真正的勇士",publishDdata="2015-9-9",price="50",publish=pubObj)
bookObj.save()
多对多添加:
# 多对多的添加的两种方式
# 方式一:
# 先创建一本书:
pub_obj=models.Publish.objects.filter(name="万能出版社").first()
book_obj = models.Book.objects.create(title="醉玲珑",publishDdata="2015-4-10",price="222",publish=pub_obj)
# #通过作者的名字django默认找到id
haiyan_obj = models.Author.objects.filter(name="haiyan")[0]
egon_obj = models.Author.objects.filter(name="egon")[0]
xiaoxiao_obj = models.Author.objects.filter(name="xiaoxiao")[0]
# 绑定多对多的关系、
book_obj.authorlist.add(haiyan_obj, egon_obj, xiaoxiao_obj)
# 方式二=========,查出所有的作者
pub_obj = models.Publish.objects.filter(name="万能出版社").first()
book_obj = models.Book.objects.create(title="醉玲珑", publishDdata="2015-4-10", price="222", publish=pub_obj)
authers = models.Author.objects.all()
# #绑定多对多关系
book_obj.authorlist.add(*authers)
解除绑定:remove: # 将某个特定的对象从被关联对象集合中去除。
清除绑定:clear” #清空被关联对象集合。
清除绑定与解除绑定的区别:
remove:提前把你要清除的数据筛选出来,然后移除
clear:不用查,直接就把数据都清空
基于对象的查询记录(类似于sql语句中的where语句):
一对一查询记录:author和authordetile是一对一的关系
正向查询(按字段author)
反向查询(按表名authordeital):因为是一对一的关系了,就不用_set了。
一对多查询记录:
正向查询(按字段:publish):
反向查询(按表名:book_set):
多对多查询记录:
正向查询(按字段authorlist)
反向查询(按表名book_set)
基于双下划线的跨表查询(自学成才我相信你)
聚合查询与分组查询
聚合查询:aggregate(*args, **kwargs),只对一个组进行聚合
aggregate()是QuerySet 的一个终止子句(也就是返回的不再是一个QuerySet集合的时候),意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。
分组查询 :annotate():为QuerySet中每一个对象都生成一个独立的汇总值。
是对分组完之后的结果进行的聚合
F查询与Q查询
F查询:
如果我们要对两个字段的值做比较:
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
Q查询:
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),可以使用Q对象。
注意:
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
查询总结
(1)总结之跨表查询
创建表:
class Book(models.Model):
title = models.CharField(max_length=32)
publish=models.ForeignKey("Publish") # 创建一对多的外键字段
authorList=models.ManyToManyField("Author") # 多对多的关系,自动创建关系表
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
ad=models.models.OneToOneField("AuthorDetail") #创建一对一的关系
class AuthorDetail(models.Model):
tel=models.IntegerField()
基于对象关联查询:
if 一对多查询(Book--Publish):
正向查询,按字段:
book_obj.publish : 与这本书关联的出版社对象 book_obj.publish.addr: 与这本书关联的出版社的地址
反向查询,按表名_set
publish_obj.book_set: 与这个出版社关联的书籍对象集合 publish_obj.book_set.all() :[obj1,obj2,....]
if 一对一查询(Author---AuthorDetail):
正向查询,按字段:
author_obj.ad : 与这个作者关联的作者详细信息对象
反向查询:按表名:
author_detail_obj.author : 与这个作者详细对象关联的作者对象
if 多对多(Book----Author):
正向查询,按字段:
book_obj.authorList.all(): 与这本书关联的所有这作者对象的集合 [obj1,obj2,....]
book_obj.authorList.all().values("name"): 如果想查单个值的时候可以这样查
反向查询,按表名_set:
author_obj.book_set.all() : 与这个作者关联的所有书籍对象的集合
book_obj.book_set.all().values("name"): 如果想查单个值的时候可以这样查
基于双下划綫的跨表查询:
if 一对多查询(Book--Publish):
正向查询,按字段:
# 查询linux这本书的出版社的名字:
models.Book.objects.all().filter(title="linux").values("publish__name")
反向查询:按表名:
# 查询人民出版社出版过的所有书籍的名字
models.Publish.objects.filter(name="人民出版社出版").values("book__title")
if 一对一查询(Author---AuthorDetail):
正向查询,按字段:
#查询egon的手机号
models.Author.objects.filter(name="egon").values("ad__tel")
反向查询:按表名:
#查询手机号是151的作者
models.AuthorDetail.objects.filter(tel="151").values("author__name")
if 多对多(Book----Author):
正向查询,按字段:
#查询python这本书的作者的名字
models.Book.objects.filter(title="python").values("authorList__name") [{},{},{},{}]
正向查询,按表名:
#查询alex出版过的出的价格
models.Author.objects.filter(name="alex").values("book__price")
注意:
publish=models.ForeignKey("Publish",related_name="bookList")
authorlist=models.ManyToManyField("Author",related_name="bookList")
ad=models.models.OneToOneField("AuthorDetail",related_name="authorInfo")
反向查询的时候都用:related_name的值
聚合查询:
querySet().aggregate(聚合函数)------返回的是一个字典,不再是一个querySet
Book.objects.all().aggregate(average_price=Avg('price'))
分组查询:
querySet().annotate() --- 返回的是querySet
Auth模块
暂未总结
Form组件
暂未总结