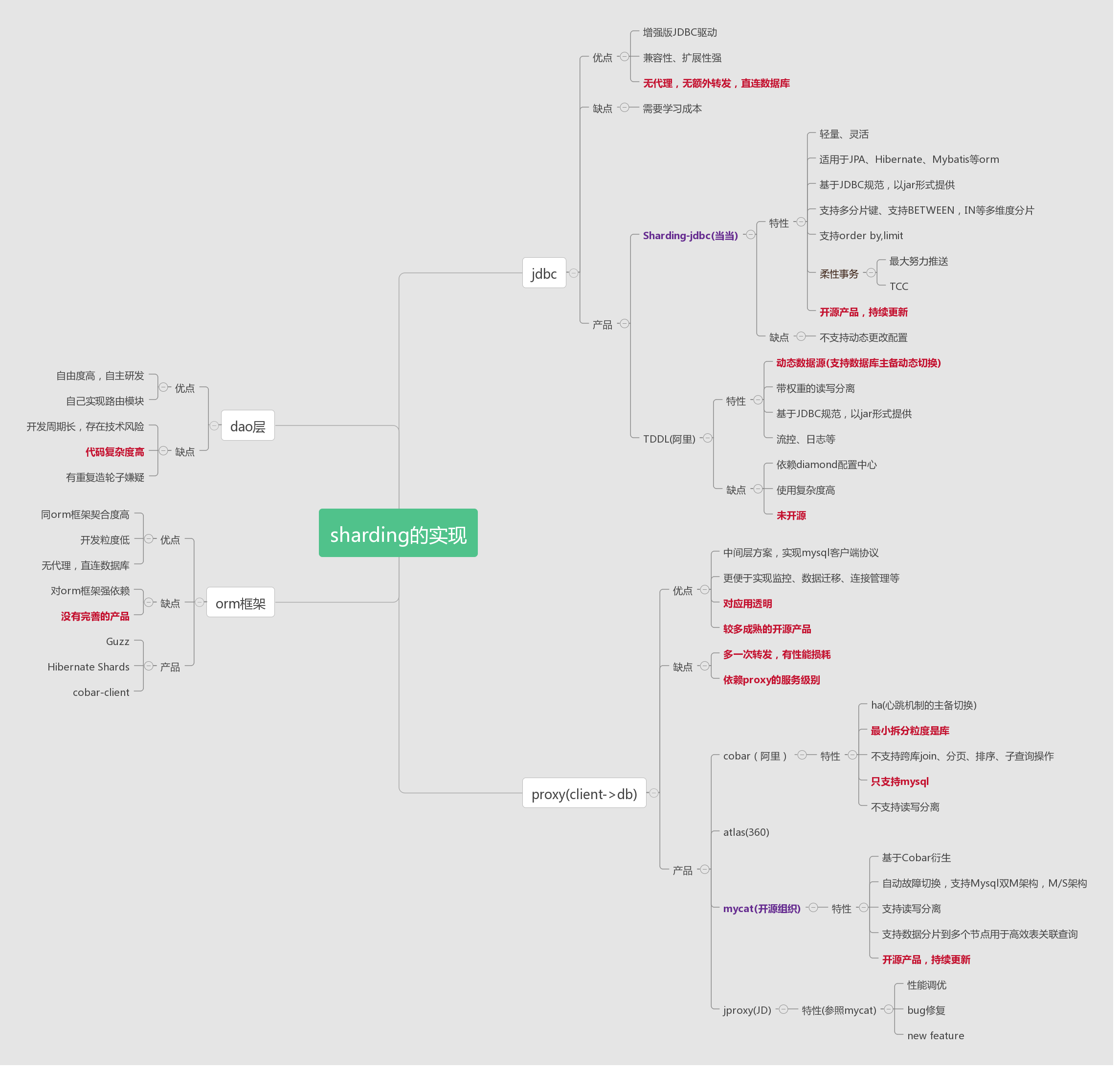
一、遇到的难题
随着业务扩展,大数据量迸发,mysql单表数据量爆炸时,你怎么办? 当你的数据库无法承受高强度io时你怎么办?
二、概念
数据库分片概念:
1)单库,就是一个库
2)分片(sharding),分片解决扩展性问题,属于水平拆分,引入分片,就引入了数据路由和分区键的概念。分表解决的是数据量过大的问题,分库解决的是数据库性能瓶颈的问题

3)分组(group),分组解决可用性问题,分组通常通过主从复制(replication)的方式实现
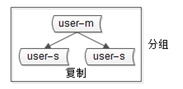
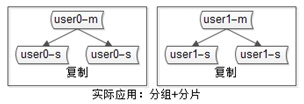
4)互联网公司数据库实际软件架构是(大数据量下):又分片,又分组(如下图)
3、 分片
3.1 水平拆分,垂直拆分都是什么?
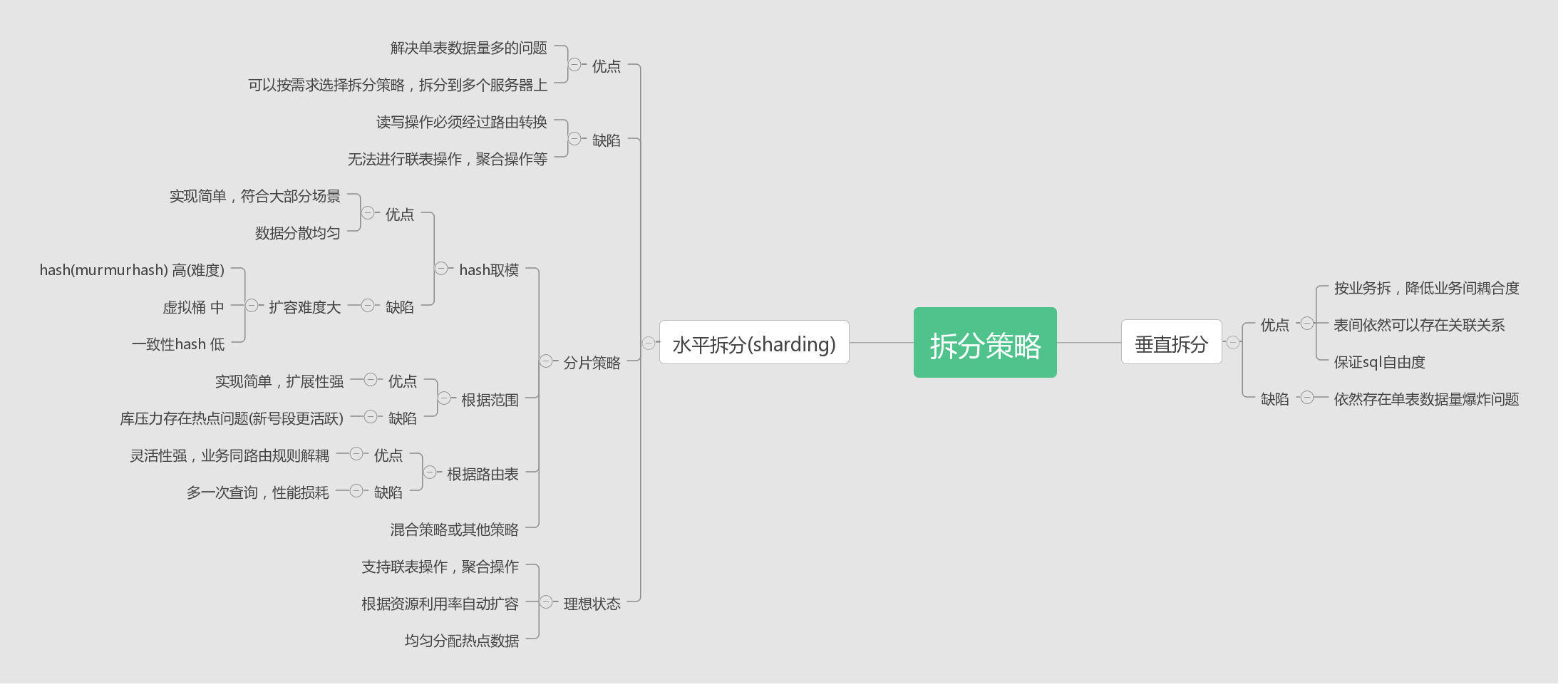
3.2 为什么分表?
关系型数据库在大于一定数据量的情况下检索性能会急剧下降。在面对互联网海量数据情况时,所有数据都存于一张表,显然会轻易超过数据库表可承受的数据量阀值。这个单表可承受的数据量阀值,需根据数据库和并发量的差异,通过实际测试获得。
3.3 为什么分库?
单纯的分表虽然可以解决数据量过大导致检索变慢的问题,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以通常水平拆分都至少要采用分库的方式,用于一并解决大数据量和高并发的问题。这也是部分开源的分片数据库中间件只支持分库的原因。
3.4 分布式事务?
但分表也有不可替代的适用场景。最常见的分表需求是事务问题。同在一个库则不需考虑分布式事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。目前强一致性的分布式事务由于性能问题,导致使用起来并不一定比不分库分表快。目前采用最终一致性的柔性事务居多。分表的另一个存在的理由是,过多的数据库实例不利于运维管理
3.5 分库和分表结合起来用
3.6 如何自己实现分库分表?
1) dao层,首先通过分区键算出库名表名(如shardKey%shardNum 算出来表index如y,然后y/(shardNum/sourceNum)=x,y是表下标,x是库下标)。
2) 把source从spring容器中拿出来,把表名当参数传进去,拼成分片后的sql。
3) 思路大概是(select … from order where … -> 先拿到db_x的source 然后 select … from order_y where …)