内存管理是操作系统的核心;它对于程序员和系统管理员都很关键。在接下来的几篇文章里面我将对内存的关键技术做谈论,但是不会远离其本质。然而概念很普通,例子多半来自32位X86系统的LINUX和Window操作系统。这第一篇文章谈论程序在内存中如何存放。
在多任务操作系统中的每一个进程运行在他自己的内存地址空间中。这个地址空间就是虚拟地址空间,虚拟地址空间在32位模式下总是4GB大小的内存地址。这些虚拟地址用页表方式映射物理内存,页表由操作系统内核维护,由处理器访问。每个进程有自己的页表集合,但这里有个难以理解的地方。一旦虚拟地址(作者的意思也就是分页机制)开启,它应用与所有正在运行与机器上的软件,包括内核自身。这样一部分虚拟地址空间必须保留用于内核:
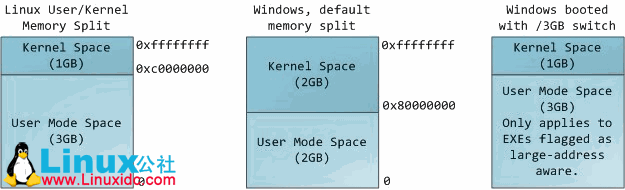
这并不意味着内核使用那么多物理内存,只是他运用那部分可用的地址空间去映射他实际希望的物理内存大小。内核空间在页表中标志为特权级代码(等级小于等于2),这样当用户模式程序访问他时就会触发一个访页错误。在LINUX中,内核空间一直处于当前状态并且在所有进程中映射到相同的物理内存。内核代码和数据在任何时候总是为中断服务和系统调用做好寻址的准备。相反,用于映射用户模式的地址空间部分将会在进程切换的时候发生改变。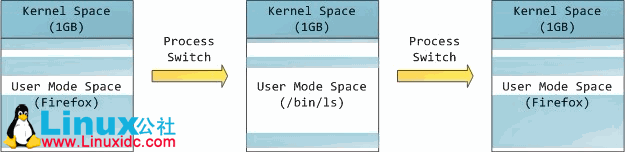
蓝色区域代表已经映射物理内存的虚拟地址,白色区域为没映射部分。在上面的例子中,Firefox由于他的巨大的内存需求,已经使用了他的大部分虚拟地址空间。地址空间中不同的带对应内存段如堆、栈等等。需要注意的是这些段就是简单的内存地址范围,他和Intel汇编中的”段”不相干。下面是在LINUX进程中标准的段视图: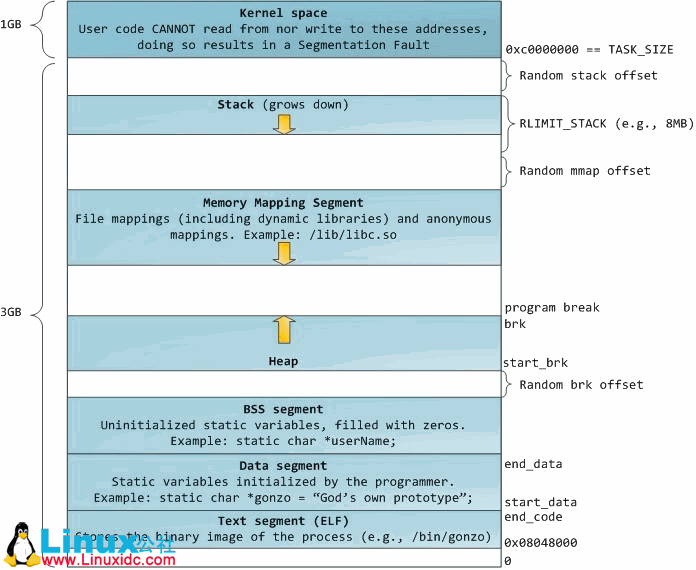
当计算安全时,如上面的段所示,对于机器中的几乎每一个进程的开始虚拟地址都相同。这使得很容易远程利用安全漏洞。一个漏洞,往往需要引用绝对内存位置:栈上的地址,库函数的地址,等等。远程攻击必须盲目地选择这个内存位置,正指望这所有的地址空间都是一样的。如果真是这样,那么太容易被攻击了。故而地址空间的随机化就变得通用了。LINUX以在栈、内存映射段和堆的起始地址加上偏移的方式随机化他们。不幸的是,32位地址空间很紧缺,留下很少的空间用来做随机化从而牵制了他的有效性。
进程地址空间中最上面的段为栈,很多语言中栈用于存储本地变量和函数参数。调用一个方法或函数时压入栈一个新的栈帧。当函数返回时,这个压入的栈帧被释放。这个简单的设个,可能是因为数据遵循严格的FIFO次序,这意味着再复杂的数据结构都无需跟踪栈内容——一个简单的栈顶指针将会做跟踪作用。这样入栈和出栈非常快速和准确。进一步,堆栈地区不断重用,往往在CPU缓存中持有活跃的栈内存,加快存取。进程中的每个线程获得他自己的栈。
当压入操作他负载的数据时,耗尽栈的映射区域是有可能的。这将会触发一个缺页中断,在LINUX中由expand_stack()函数接手,该函数调用acct_stack_growth()来检查是否应当扩展栈。如果栈的大小在RLIMIT_STACK(通常是8MB),那么通常会扩展栈并且程序不会发觉刚才发生的这一切。这是正常的栈大小调节的机制。然而,如果栈的最大值已经达到,栈将会溢出并且程序会接手到一个段错误。当有扩展需求时,栈会扩大,而栈变小时他不会回缩。就像federal的budget,他只是扩展。
只有一种情况会发生动态栈扩展,那就是程序进入一个没有映射的内存区域,比如上面的白色区域,可能是无效的。任何其他进入没有映射内存区间触发与一个缺页中断会导致一个段错误。有些映射区域的只读的,所以,向这些区域写数据同样会导致段错误。
在栈下面是内存映射段。这里内核直接映射内存到文件内容。任何应用程序都可以通过mmap()系统调用(LINUX下)或CreateFileMapping()/MapViewOfFile()(windows下)获得这个映射。内存映射是文件I/O中一个方便高效的方法,所以他用于加载动态库。创建一个和任何文件不想干的匿名内存映射用于替代程序中的数据也是有可能的。在LINUX中,如果你通过malloc()申请一块很大的内存块,C标准库将创建一个匿名映射而不是用内存堆。’很大‘意味着大于MMAP_THRESHOLD个字节,默认是128KB,可以通过mallocpt()做调整。
说到堆,我们接下来跳到地址空间中的下一个。堆提供运行时内存分配,就像栈,而和栈不一样的是数据必须持久于分配函数。大多数程序语言都为程序提供了堆管理器。满足内存需求是一个语言运行库和内核之间的联合事务。在C中,堆分配器的接口是malloc()系列函数,然而在垃圾回收语言如C#的堆分配接口是new关键字。
如果堆里面有足够的空间满足内存需要,那么它可以完全由语言运行库处理而不需要内核环境。否则通过brk()系统调用扩展堆为请求块获得空间。堆管理器很复杂,在面对我们应用程序混乱的分配方式,需要复杂的算法来维持内存使用的速度和效率。为堆请求提供服务的时间可以有很大的差异。实时系统有特殊目地的分配器来处理这个问题。堆也变得有很多碎片,如下图所示:

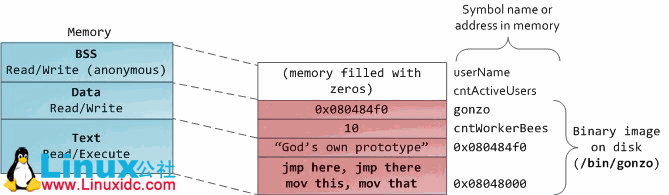
最后,我们到达了内存中最下面的段:BSS段、数据段和代码段。BSS段和数据段在C语言中存储静态和全局变量。不同的是BSS段存放的是没有被初始化的静态变量,也就是所这些静态变量在源代码中没有被程序员设置初值。BSS内存区是匿名的:他不映射任何特定的文件。例如,static int cntActiveUsers,变量cntActiveUsers的内容存放在BSS段。
另一方面,数据段持有在源代码中已经初始化的静态变量。他的内存区域不是匿名的。他映射程序二进制镜像的一部分,这部分包含在源代码中已初始化的静态变量。例如,static int cntWorkerBees = 10, 那么cntWorkerBees存放在数据段中且初始数据为10。虽然数据段映射一个文件,但是他是一个私有内存映射,这意味着内存更新不会反映到底层文件。这一定是这样的,否则分配分配到的全局变量将改变你磁盘上的二进制镜像。后果难以想象!!
图中数据的例子是棘手的因为他使用了一个指针。在这种情况下,gonzo指针的内容——一个4字节的内存地址——存放在数据段中,而他指向的实际数据却不是。指向的实际内容存放在代码段中,代码段是只读的并且存放你的所有代码以及字符串文字花絮。代码段也在内存中映射你的二进制文件,但是写这个区域会发生段错误。这有助于防止指针错误,虽然没有有效的避免C语言放在首要位置。这里有个图,显示这些段和我们例子里面的变量:
在一个LINUX进程中你可以通过读/proc/pid_of_process/maps文件来检查内存区域。例如,每一个内存映射文件通常在映射段(mmap段)有他自己的区域,并且动态库有类似BSS段和数据段的额外区域。接下来的文章中会澄清什么“区域”(“area”)的真正含义。此外,有时人们说“数据段”意味着所有的数据+ bss +堆。
你可以检查二进制镜像,运用nm和objdump命令来显示符号、他们的地址、段等等。最后,上面所述的虚拟地址布局在LINUX中是“灵活”的,这几年一直是默认的。他假定我们有一个RLIMIT_STACK的值。当并非这种情况时,LINUX恢复到如下的“经典”布局:
这就是他的虚拟地址空间布局。接下来的文章中讨论的是内核如何保持跟踪这些内存区域。未来,我们将会看看内存映射、文件读写和这一切是怎么关联的以及内存使用计数意味这什么。