第一章 初识爬虫
一、爬虫简介
二、http与https协议
三、requests模块
一、爬虫简介
什么是爬虫(what):
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
哪些主流语言可以实现爬虫:
(1)Php:对多线程和多进程支持的不好
(2)Java:代码臃肿,重构成本较大
(3)C/c++:是一个非常不明智的选择,是一个很好装13的选择
(4)Python:没有!!!代码优雅,学习成本低,具有非常多的模块。具有框架的支持。
爬虫分类:
(1)通用爬虫:是搜索引擎中“抓取系统”的重要组成部分。(爬取的是整张页面)
- 搜索引擎如何抓取互联网的网页?
①门户主动将自己的url提交给搜索引擎公司
②搜索引擎公司会和DNS服务商进行合作
③挂靠知名网站的友情链接
(2)聚焦爬虫:根据指定的需求去网上爬去指定的内容。
robots.txt协议
指定的是门户中哪些数据可以供爬虫程序进行爬取和非爬取。
反爬虫与反反爬虫:
反爬虫:门户网站可以通过某些技术手段或者策略阻止爬虫程序对其数据的爬取。
反反爬虫:爬虫程序通过某些技术手段或者策略破解门户网站的反扒策略。
二、http协议与https协议(可以参阅《图解HTTP》加深理解)
1.HTTP协议
什么是HTTP协议(what):
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
工作原理:
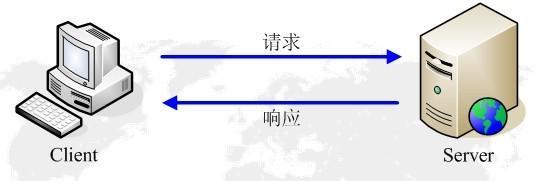
四大特性:
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
URL组成:
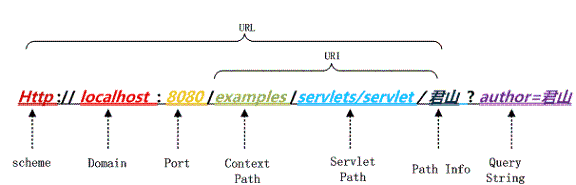
request请求:
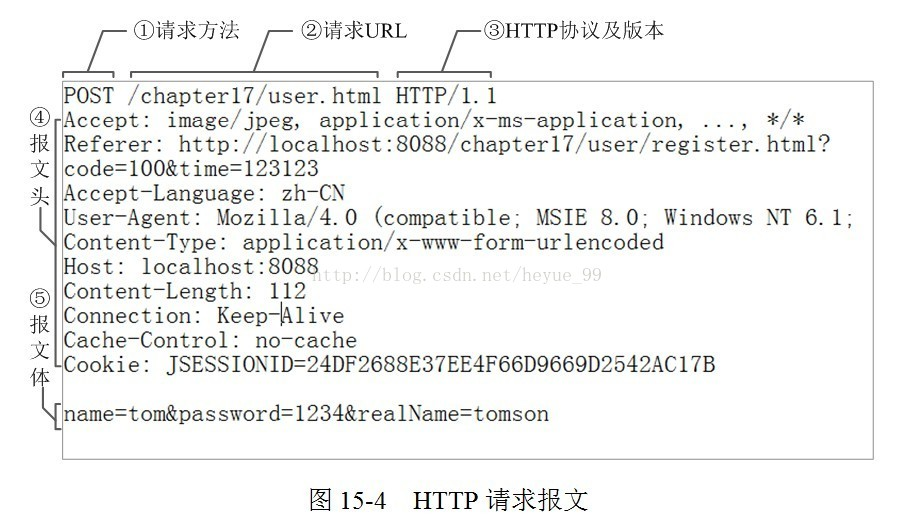
response响应:

2.HTTPS协议
什么是HTTPS协议(what):
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。

HTTPS采用的加密技术:
①SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:
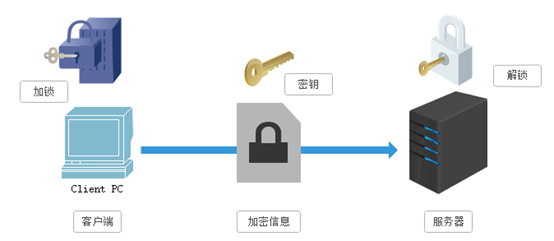

②非对称秘钥加密技术
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:

但是非对称秘钥加密技术也存在如下缺点:
a)如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
b)非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度。
https的证书机制
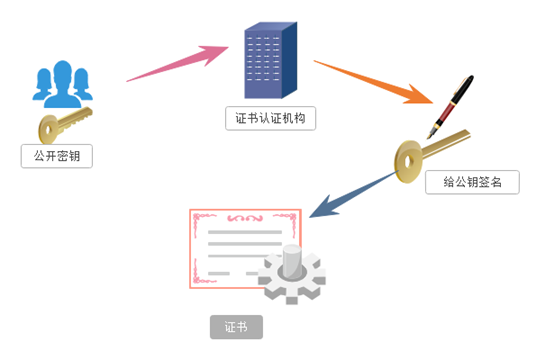
服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起。服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
三、requests模块
简单爬取数据四要素:
(1)指定url
(2)发请求
(3)数据解析
(4)持久化存储
安装模块:
pip3 install requests
演示一个简单的requests使用:
import requests # 指定url url = 'https://www.taobao.com' # 通过requests模块发起请求:get请求返回响应对象 response = requests.get(url=url) # 获取响应对象中json格式的数据 # response.json() # 获取响应数据的编码格式(可被修改) # response.encoding # 响应状态码 # response.status_code # 获取响应头信息 # response.headers # 获取响应内容(爬取淘宝页面数据) # content获取的是二进制数据 # data = response.content # text获取的是字符串类型的数据 # data = response.text print(response.headers)
需求:根据指定的url进行网页数据的爬取,且进行持久化操作(一个最简单的爬虫演示)
# 根据指定的url进行网页数据的爬取,且进行持久化操作 import requests # 指定url url = 'https://www.taobao.com' # 发起请求 response = requests.get(url) data = response.text # 进行文件操作 with open('./taobao.html','w',encoding='utf-8')as f : f.write(data) print('over')
知识储备
抓包工具Fiddler 4的简单配置
①点击tools下的options
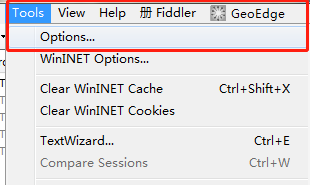
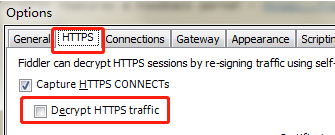
②禁用https抓取限制(勾选红框部分)
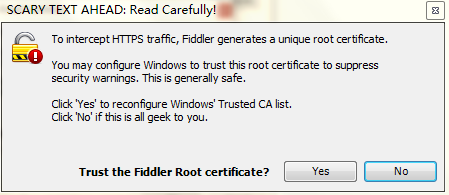
③点击yes安装证书
④勾选下图内容,点击证书
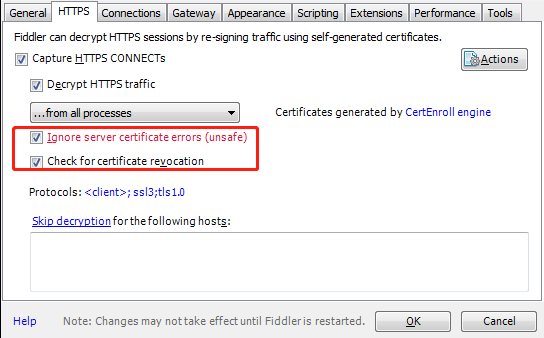
⑤配置完成后需要重启fiddler4
⑥简单熟悉fiddler4
《》代表get请求

查看请求信息

重点关注以下几个选项卡:
Headers:请求信息
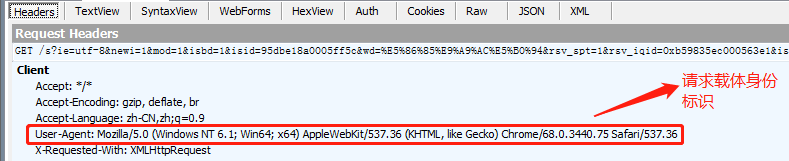
Raw:常用的请求信息都在这里

WebForms:请求携带的参数

requests模块下的get请求
案例:百度搜索
import requests # requests的get请求 wd = input('enter a word:') # 模拟抓取系统,手动指定关键字进行百度搜索,保存搜索结果 # 百度较为特殊,需要把https的s给去掉 get_url = 'http://www.baidu.com/s' # url的特性:url必须是有ASCII编码的数据组成 # 可以将请求携带的参数封装到一个字典中 param = { 'ie': 'utf-8', 'wd': wd } # 参数2表示请求参数的封装 response = requests.get(url=get_url, params=param) file_name = wd + '.html' # response.encoding = 'utf-8' with open(file_name,'w',encoding='utf-8') as f : f.write(response.text) print('over')
requests模块下的post请求
案例:百度翻译
