Caffe的数据格式采用leveldb或者lmdb格式
本文采用数据为已标定过的彩色图像,共1000张训练图共10个类别,200张测试图像10个类别,下载地址:http://pan.baidu.com/s/1hsvz4g8。
ps:此处主要描述制作leveldb格式文件,创建lmdb格式文件为类似操作,只需要把所有"leveldb"字符换成“lmdb"即可
第一步:数据格式转换
1.编译conver_imageset,在Caffe-MasterBuildx64Release下生成convert_imageset.exe。
2.在根目录data文件下新建属于自己的数据集文件夹(主要是为了便于整理,具体位置可以根据自己需要创建)

在新建的数据集文件夹下新建以下文件夹

train和val存放原始的数据,trainldb和valldb存放格式转换后的leveldb数据,mean存放均值文件。
3.用批处理命令对数据加标签,生成train.txt用来保存训练数据的标签;生成val.txt用来保存测试数据的标签 。


4.写一个bat命令,利用convert_imageset.exe生成对应的leveldb格式数据,注意参数和路径。

若报错如下,说明新建的valdb文件夹未清空,清空即可:

运行成功效果图,新建的db文件中会生成如下文件,其中红色箭头所示文件大小不为0:


这样,满足caffe所需的数据文件就制作好了,train和test均需按照上述步骤同样操作。
第二步:数据预处理
生成均值文件
同上编译compute_image_mean,在Caffe-MasterBuildx64Release下生成compute_image_mean.exe。
写一个bat命令,利用compute_image_mean.exe生成对应的均值文件,train数据和test数据需经过同样操作。

生成如下文件:

第三步:定义网络结构并训练
此处主要验证制作数据是否可用,故网络直接采用Caffe提供的样例中cifar10的网络结构和配置文件,主要为如下两个

改成自己的命名方式:

主要修改其中的路径

其中1表示训练所需网络文件的路径,2表示生成结果文件的路径。Mine_train_test文件中主要修改leveldb文件路径和均值文件路径。
编写bat文件,开始训练:

训练结果显示:
训练初识别率:
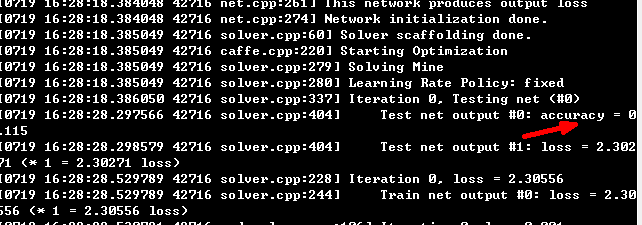
训练后的识别率:

Reference:Windows下caffe训练自己的数据