接下来就是最最最重要的一个有监督学习算法了。
支持向量机
问题背景
样本集表示:
[(x,y)in D, xin R^n, yin {-1,+1}
]
回到之前的逻辑回归模型中:
逻辑回归中如果(h ( x ) =g( heta^Tx)geq 0.5)我们就认为是正例(y=1)。也就是( heta^Txgeq 0),且( heta^Tx)趋向于无穷大的时候h(x)输出的概率也会越接近于1。所以说:
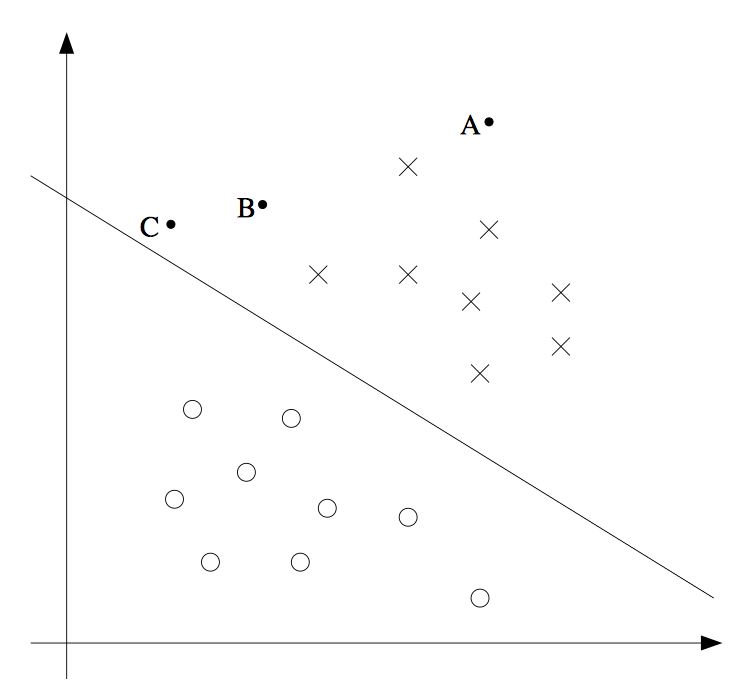
在图像上来理解的话,中间那条线是我们的决策边界。也就是说点离我们的决策边界越远我们越是确信这个点是属于一类。所以我们如何基于这样的间距想法来构造一个模型呢。或者说我们如何构造一个模型,找点一条线使得不同种类的点离这条线都足够远呢。
即SVM是一个最大间距分类器。
构造假设
这里我们要把之前用的符号换一下,把( heta^Tx)表示成(w^Tx+b),实际上就是把偏置项给显示地拿了出来。还有一个要注意的是样本集中的分类标签改为了+1和-1而不是之前的0和1。
基于刚才问题背景中的想法,我们构造的假设函数就是:
[h(x) = left{ �egin{array} { c l } { +1,} & { w^Tx+b geq 0} \ { - 1,} & { w^Tx+b < 0} end{array}
ight.
]
衡量误差
于是我们现在要的就是如何使得点离我们分类直线的距离足够大。
那么先定义点到直线的距离,即某点(p)到超平面(w^Tx+b=0)的距离为:
[frac { 1} { | w | } | w ^ { T } p + b |
]
其实这条公式我们初高中就学过,只不过是写成这样的:对于直线(Ax+By+C=0)点(p=(x',y'))到直线的距离为:
[frac{|Ax'+By'+C|}{sqrt {A^2+B^2}}
]
那么我们定义间隔为:
[gamma = 2min _ { i } frac { 1} { | w | } | w ^ { T } x _ { i } + b |
]
那么最终的优化目标就是:
[�egin{array} { r l }
{max _ { w ,b } min _ { i }} & {frac { 2} { | w | } | w ^ { T } x _ { i } + b |} \
{ ext{s.t.}} & {y _ { i } ( w ^ { T } x _ { i } + b ) > 0,quad i = 1,2,dots ,m}
end{array}
]
问题求解
在求解问题之前我们先做一个重要的假设:样本集线性可分。
为了化简问题我们可以对((w,b))进行放缩,即令:
[min _ { i } | w^Tx _ { i } + b | = 1
]
那么求解优化问题可以化简成:
[left.�egin{array} { l } { min _ { w ,b } frac { 1} { 2} w ^ { T } w } \ { ext{ s.t } quad y _ { i } left( w ^ { T } x _ { i } + b
ight) geq 1,quad i = 1,2,dots ,m } end{array}
ight.
]
这是一个带约束的优化问题,之前梯度回归解决的是无约束的优化。所以简单理解的话我们可以使用二次规划对其进行求解,但是二次规划这里就先不讲了。有兴趣自行翻阅资料。
那么所谓SVM其实到这里就结束了。但是更重要的思想要体现在其对偶问题上。
对偶问题
虽然可以用二次规划求解这个问题。但是我们可以通过拉格朗日算子和对偶问题来对其进行再化简。
优化目标再定义
这里重新令(θ=[w,b]^T)
高等数学中我们学过用拉格朗日算子求条件极值。
对于有条件约束的优化问题:
[left.�egin{array} { r l } { min _ { heta } } & { f ( heta ) } \ { ext{ s.t. } } & { g _ { i } ( heta ) leq 0,quad i = 1,dots ,k } \ &{ h _ { i } ( heta ) = 0,} quad { i = 1,dots ,l } end{array}
ight.
]
定义其拉格朗日函数为:
[mathcal { L } ( heta ,alpha ,�eta ) = f ( heta ) + sum _ { i = 1} ^ { k } alpha _ { i } g _ { i } ( heta ) + sum _ { i = 1} ^ { l } �eta _ { i } h _ { i } ( heta )
]
带入拉格朗日算子得到:
[min _ { alpha } max _ { heta} frac { 1} { 2} heta ^ { T } heta + sum _ { i = 1} ^ { m } alpha _ { i } left( 1- y _ { i } left( heta ^ { T } x _ { i } + b
ight)
ight)
]
[ ext{ s.t. } quad alpha _ { i } geq 0,quad i = 1,2,dots ,m
]
对α的约束是拉格朗日函数提供,并不是我们问题本身的约束。这里突然多了个max操作是让g满足我们的条件约束。我们的约束是(g(x)<0)如果这个约束不满足,那么因为α和β的值是任意的,对g的max操作就会是正无穷。后面的min操作就没有意义了。
对于这样问题满足一定条件时,我们可以转换为其对偶问题,即min和max互换位置。这里省略了很多细节,请翻阅参考:
[max _ { alpha } min _ { heta } quad frac { 1} { 2} heta ^ { T } heta + sum _ { i = 1} ^ { m } alpha _ { i } left( 1- y _ { i } left( heta ^ { T } x _ { i } + b
ight)
ight)
]
[ ext{ s.t. } quad alpha _ { i } geq 0,quad i = 1,2,dots ,m
]
因为内层的min没有约束,我们可以直接求导得到最小值。
[frac { partial mathcal { L } } { partial heta } = mathbf { 0} Rightarrow w = sum _ { i = 1} ^ { m } alpha _ { i } y _ { i } x _ { i }
]
[frac { partial mathcal { L } } { partial b } = 0Rightarrow sum _ { i = 1} ^ { m } alpha _ { i } y _ { i } = 0
]
化简为:
[min _ { alpha } frac { 1} { 2} sum _ { i = 1} ^ { m } sum _ { j = 1} ^ { m } alpha _ { i } alpha _ { j } y _ { i } y _ { j } x _ { i } ^ { T } x _ { j } - sum _ { i = 1} ^ { m } alpha _ { i }
]
[ ext{ s.t. } sum _ { i = 1} ^ { m } alpha _ { i } y _ { i } = 0
]
[alpha _ { i } geq 0,quad i = 1,2,dots ,m
]
注意这里是min不是max是因为取了负号。那么最终的优化问题只与这个α有关。
我们回顾一下整个的流程:
首先回顾一下,最初带入拉格朗日算子得到的是,关于θ和α的双变量的单极值带双约束的问题,我们把约束条件放进转化为另一个极值。这样变成一个关于θ和α的双变量双极值单约束问题。再利用对偶问题,交换极值位置,使得内层的极值问题是无约束的,对其求解,用α消去了θ变成了关于α的单变量的单极值双约束问题,最后这个问题就可以用普通的二次规划进行求解了。
这里并不想太过于纠结数学上细节。但是把整个转化的过程理清楚即可。
KKT条件
因为这是一个有条件的优化问题,极值处需要满足:
- 主问题可行:$$g _ { i } ( w ) leq 0,h _ { i } ( w) = 0$$
- 对偶问题可行:$$alpha_igeq0$$
- 互补松弛:$$alpha _ { i } g _ { i } ( w ) = 0$$
这三个要满足的条件就是KKT条件。
支持向量
一般来说条件约束的函数极值一般会在约束处取到极值。所以说如下图所示:

我们取到约束的地方就是那两条虚线的地方。在虚线上的点就叫做支持向量,这也是支持向量机名称的由来。也就是说因为我们衡量误差的方式,最后求解的问题只会和这个支持向量相关,即我们直线只由支持向量决定。
于是假设函数最终表示成:
[h ( x ) = operatorname{sign} left( sum _ { i in S V } alpha _ { i } y _ { i } leftlangle x _ { i } , x
ight
angle + b
ight)
]
SV表示支持向量,<>表示内积操作。
核函数
问题背景
回忆一下我们在求解问题中提到的基本假设就是,样本集线性可分,但是对于线性不可分的情况怎么办呢。
我们可以把样本集映射到更高维度空间上使得其线性可分。比如上面那张图,是二维平面上面样本集,如果我们把这些点投影到一维空间上面,比如说x轴。点就会变密。如果投影到零维空间上,那么所有点都变成了一个点。基于这样的直觉,我们可以认为样本集在越高维度空间上是越稀疏的。所以核函数的作用就是把样本集投影到更高维度空间上使其稀疏变得线性可分。
构造假设
在拉格朗日乘子法中我们求解得到了α并用α替代了w得到了新的假设函数:
[h(x)= sum _ { i = 1} ^ { n } alpha _ { i } y ^ { ( i ) } leftlangle x ^ { ( i ) } ,x
ight
angle + b
]
也就是说如果新来了一个样本,我们要判断类别的话,只要和原来样本集中的点做内积计算即可。
回到刚才的问题上来,我们想把样本集映射到更高维度的空间上。假设函数中的我们做了内积运算(langle x ^ { ( i ) } ,x
angle)得到了一个值。所以要做的就是把x映射到更高维的空间再做内积运算即可。
如果(phi ( x ))表示的是对向量x的一个映射,那么定义核函数k就是:
[K ( x ,z ) = phi ( x ) ^ { T } phi ( z )
]
比如我们一个核函数为:
[K ( x ,z ) = left( x ^ { T } z
ight) ^ { 2}
]
即:
[left.�egin{aligned} K ( x ,z ) & = left( sum _ { i = 1} ^ { n } x _ { i } z _ { i }
ight) left( sum _ { j = 1} ^ { n } x _ { j } z _ { j }
ight) \ & = sum _ { i = 1} ^ { n } sum _ { j = 1} ^ { n } x _ { i } x _ { j } z _ { i } z _ { j } \ & = sum _ { i ,j = 1} ^ { n } left( x _ { i } x _ { j }
ight) left( z _ { i } z _ { j }
ight) end{aligned}
ight.
]
那么(phi ( x ))的映射就是:
[phi ( x ) = left[ �egin{array} { c } { x _ { 1} x _ { 1} } \ { x _ { 1} x _ { 2} } \ { x _ { 1} x _ { 3} } \ { x _ { 2} x _ { 1} } \ { x _ { 2} x _ { 1} } \ { x _ { 2} x _ { 1} } \ { x _ { 2} x _ { 2} } \ { x _ { 3} x _ { 2} } \ { x _ { 3} x _ { 3} } end{array}
ight]
]
那么是不是任意的映射都可以作为核函数呢,当然并不是。详细请翻一下参考。
软间距
问题背景
仍然是回到之前那个线性可分的假设中,首先我们假设样本集线性可分,如果线性不可分就映射到高维使得其线性可分。但是如果映射到高纬度还是线性不可分呢。或者这样的一种情况:

本来我们的决策边界是左边这样的,但是如果出现了一个新的样本o我们的决策边界可能会变成右边这样。然而我们仔细思考一下对于右边这个样本集是不是虚线那条决策边界会更好一下。因为很有可能新的那个样本是一个被采样错误的样本。
于是因为存在线性不可分和采样错误的样本的存在。我们需要在衡量误差的时候对被假设函数分类错误的样本有一定的容忍度。
衡量误差
我们引入一个(xi)值(也叫做松弛变量)表示我们对分类错误的容忍度。
[left.�egin{array} { c l } min _ {w ,b }& frac { 1} { 2} | | w | | ^ { 2} + C sum _ { i = 1} ^ { m } xi _ { i }\{ ext{ s.t. } } & { y ^ { ( i ) } left( w ^ { T } x ^ { ( i ) } + b
ight) geq 1- xi _ { i } ,quad i = 1,ldots ,m } \ & { xi _ { i } geq 0,} quad { i = 1,ldots ,m } end{array}
ight.
]
写在约束条件中的(1-xi)其实就是允许支持向量向着决策边界方向移动了,这样间距就会变小,所以叫软间距,这给予了我们容忍分类错误的能力。
而写在优化条件里面中的(xi)是使得分类错误不能太多,所以常数C就是我们对于错误的容忍度。
于是我们可以调节C改变优化的条件来使得这个分类器对于错误容忍度不同来构造更健壮的分类器。
小结
首先我们由最大间距的直觉来构造了一个新的分类器,也就是我们的支持向量机原始问题。我们再对其对偶问题求解得到对偶形式。再对线性不可分的情况下利用核函数映射到高纬。并引入软间距允许误差的存在也有利于线性不可分的情况。
参考
从零构建支持向量机