|
摘要:性能可能是目前计算领域中了解最少并且被错误引用的衡量标准之一。技术人员和应用程序供应商的常见做法是:将性能视为一个可以稳妥地留待在项目或系统实现末尾执行的调整工作来解决的问题。与此相对的是,作为系统评估的衡量标准,大多数用户都将性能视为评价一个系统是否适合特定用途的最重要甚至最关键的因素之一。本文描述在 2002 年 10 月间,作为 Capital Markets Company (Capco) 和 Microsoft 之间的联合项目的一部分,在位于华盛顿州雷德蒙市的 Microsoft ISV Laboratories (ISV Labs) 进行的一个基准测试练习。
本页内容
简介
性能可能是目前计算领域中了解最少并且被错误引用的衡量标准之一。技术人员和应用程序供应商的常见做法是:将性能视为一个可以稳妥地留待在项目或系统实现的末尾执行的调整工作来解决的问题。与此相对的是,作为系统评估的衡量标准,大多数用户都将性能视为评价一个系统是否适合特定用途的最重要甚至最关键的因素之一。本文描述在 2002 年 10 月间,作为 Capital Markets Company (Capco) 和 Microsoft 之间的联合项目的一部分,在位于华盛顿州雷德蒙市的 Microsoft ISV Laboratories (ISV Labs) 进行的一个基准测试练习。
该项目是 Capco 接受新加坡证券交易所 (SGX) 的委托而启动的,目的是提供业务评估以及为该交易所的集中式事务处理实用工具开发技术体系结构。该实用工具需要为新加坡市场的证券和固定收益交易领域中的参与者的交易后、结算前交互提供匹配的服务。主要处理引擎的设计是在一个名为软件性能工程 (SPE) [SMITH90, SMWIL02] 的过程之后完成的 — 在该过程中,整个设计和验证练习是从性能角度而不是从传统的面向对象设计角度建模的。
Capco 创建了两个子系统,分别称为 STP Bridge(一个通信基础结构和交易所网关)和 STE(一个可缩放的事务引擎)。这两个子系统都在该基准测试练习中得到了使用。
处理模型
STE 的体系结构基于松耦合、无状态的消息处理组件,这些组件排列在队列网络中,以获得高可伸缩性、高性能以及极高的事务吞吐量。对于 SGX,通过分析他们在过去几年中的交易历史记录,计算出了大约 600 个消息/秒的最坏情况事务处理负载;这一数据证明是 1998 年发生的上一次亚洲金融危机期间(当时的交易所交易数量被认为异乎寻常地高)所需的最高处理水平。该值被用作基准/目标处理加载。另外,还设置了 2000 个消息/秒的弹性负载目标,以确保在成功的前提下,该体系结构具有足够的余量来应付将来的预期贸易额增长和变动。
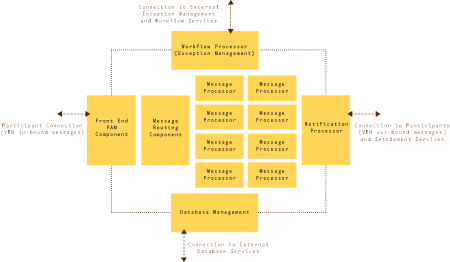
图 1. 处理引擎模型 使用通过消息队列而不是通过更传统的组件接口 (API) 通信的松耦合组件这一决策,要求直接通过消息本身(持久性消息流)或者通过在消息经过各种处理步骤时对其加以充实(临时性消息流)来在组件之间传递信息。处理组件本身在很大程度上是相互独立和无状态的。与传统的整体式应用程序开发方法比较,这会带来很多好处 — 例如,对于单个组件而言,这会降低软件开发风险和实现成本;而对于整个处理引擎而言,则会使其具有更高的可伸缩性和灵活性。大多数常规设计只支持两种可能的可伸缩性维度中的一种:向上扩展 — 通过增加处理器资源(内存、CPU 等)来增加处理能力,或向外扩展 — 通过增加处理节点的数量来增加处理能力。该体系结构支持上述两种类型的扩展。
STE 处理引擎的总体体系结构如图 1 所示。
该体系结构由很多个 STE 组件组成,这些组件负责处理基础贸易业务活动的子区域。该引擎所提供的业务过程支持是通过将整个贸易生命周期分解为一组相关的原子消息而实现的。每个市场参与者都会在交易执行期间生成和接收这些原子消息的各种子集。
该体系结构表明,业务过程本身必须能够由完全异步的可交换的操作集表示,也就是说,它必须能够按照任何顺序处理消息。这样可以不必对遍及该引擎的消息处理和业务操作进行同步(这会使应用程序变得相当缓慢和复杂)。请注意,同步不同于在正常处理中应用的消息相关。其他几个“自治计算”需求在该处理模型中得到满足。其中包括不信任系统、幂等操作、状态管理、消息相关、上下文管理、试探性操作、消息取消和事务补偿1 等概念。
经过处理引擎的业务级消息流部分地基于 Global Straight Through Processing Association (GSTPA) 所建议的执行模型,该组织推荐了一个类似的用于跨境贸易结算的集中式实用工具模型。SGX 处理模型可能需要建立与其他集中式实用工具(如 GSTPA)的操作链接,因此所使用的消息集部分地基于 GSTPA 所使用的那些消息集,以便在将来提高互操作性2。
新加坡市场的业务过程被简化为四个主要消息类型,即 Notice of Execution (NOE)、Trade Allocation (ALC)、Net Proceeds Allocation (NPR) 和 Settlement Instructions (SET)。围绕这些消息类型的过程涉及到很多交互,这些交互产生了大约 35 个构成整个业务操作模型的消息变体。正如金融服务业中最近发生的事件所表明的那样,该实用工具可能的处理量的范围会相当大。因此,该练习特别强调该体系结构支持高可伸缩性需求的能力。
性能建模
有效的基准测试练习使其他机构可以自己重复该基准并且能够取得类似的结果。另外,还需要通过合理的数学技术来支持体系结构模型的参数,以便对各种实现技术对性能产生的影响进行评估,从而决定使用某种特定的实现技术。图 2 显示用于该基准中性能分析的队列网络模型。请注意,该模型与客户端的 Participant Access Module (PAM) 密切协作。通过以这种方式测试基准,会使人感觉到该练习的结果无论好坏都是可信和有效的,并且可以将这些结果作为案例研究的基础,以便直接通过在金融服务业中处理 (STP) 计划作为全面高性能的一部分,应用队列网络模型来处理交易后、结算前信息。
测量性能
当没有识别可用来在类似的系统之间进行有效比较的性能单位时,会发生性能工程的一个最令人沮丧的方面。性能是一种主观质量,其绝对值通常只取决于系统的用户,而不取决于任何系统算法或过程。性能的这一模糊方面导致即使没有对基础技术进行任何相伴的物理更改,特定系统的性能特征的观察值也会出现变动。任何基准的结果都要受到广泛的解释,而这可能对软件系统的任何比较性分析产生危害。难以实现的性能 是基准的一种几乎与用户的性能观点没有任何关系的常见特征。在大量已经发布的基准示例中,都存在难以实现的性能;这些基准的结果通常意味着在现实世界中完全无法获得的高级别性能。例如,ADSL 连接提供 512 K 的理论下载速度,但实际上却受到在同一交换机上与其他用户争用的限制。因此,在系统之间进行性能比较的更现实的方式是,为易于在测试环境外部再现并且从系统用户的角度来看有意义的操作情况建立衡量标准。要在基准测试过程中避免出现这些种类的令人沮丧的问题,需要使用实用的技术为已实现系统的性能提供可支持的且可再现的数字。所选择的技术基于 Buzen 和 Denning 的工作 [BDEN78],以便基于合理的数学原理获得可信的性能数字。
操作基准
基准的用途是验证 Microsoft 平台技术之上的体系结构设计的合理性,以及在与将要呈现给潜在系统用户且与操作需求高度相关的环境中建立基准的可信性。要实现这一目标,必须首先使用与最终实现的实用工具一致的容量和过程加载水平来执行基准测试,然后按照既能够在实验室中又能在现场再现的方式执行基准测试。对于实验室练习,创建了一组测试管理组件,以便执行端到端分析。这些组件包括一个可扩展的消息驱动程序以及相应的可扩展消息池,它们带有从上述两个端点获得的性能度量标准。性能数字是按照充分处理构成已知数量金融交易的已知数量的消息所需的时间计算的。
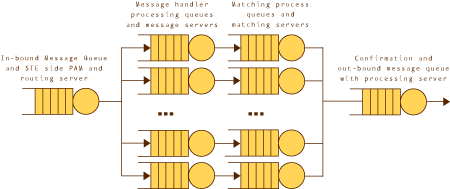
图 2. 队列网络模型 Buzen 和 Denning 方法
Buzen 和 Denning [BDEN78] 描述了一种用于评估队列网络软件系统性能的实用技术。本质上,他们认为,可以使用简单的并且可以容易地在一段时间内度量的队列长度来建立他们已经为队列网络定义的所有性能衡量标准。Buzen 和 Denning 技术的实现产生了如图 3 所示的网络模型执行图。
可以将简单的队列模型与关联服务器一起视为一个队列,如图 3所示;其中,消息从左侧的入站队列中到达(到达),由该服务器处理,然后从右侧离去(完成)。Buzen 和 Denning 技术涉及到按照固定的时间间隔对服务器的队列长度进行取样,记录仍然位于队列中的消息的数量,并且在一段时间内继续进行观察。
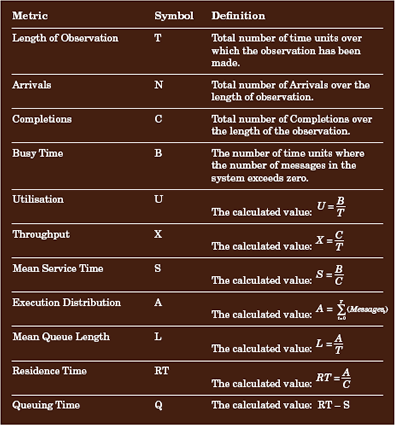
经过观察所得到的图形称为执行图,它明确显示了消息的到达(即,图形高度的增加)和完成(即,图形高度的减小)。使用这些数字,Buzen 和 Denning 从 J.D.C. Little 所建立的原始结果(称为 Little's Law [LITTL61])派生了一组公式,以便确定所有必需的性能衡量标准。这些公式的摘要如表 1 所示。
表 1. Buzen 和 Denning 公式
测量性能 要完成性能测量,需要使用一组标准的业务消息来表示该实用工具的平均业务过程生命周期。标准“交易”是使用一个 NOE (Notice of Execution) 消息、两个 ALC (Trade Allocation) 消息、两个 NPR (Net Proceeds) 消息和两个 SET (Settlement Instruction) 消息创建的。因此,标准交易包含 7 个基本消息,它们与参与者之间的必备的应答和确认消息一起组成了测试的整个信息集。系统在完成交易的处理后,还会生成另外一个消息,该消息称为 CLS (Clearing and Settlement) 消息。
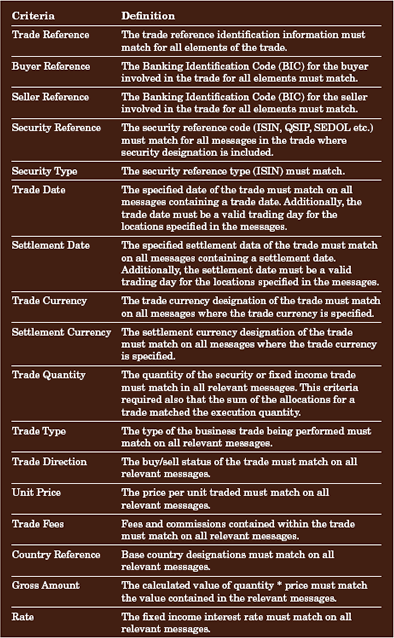
在 GSTPA 规范中,消息中需要有多达 17 个不同的元素相匹配,整个交易才能被视为有效。这些要求因要匹配的特定消息类型而异,但有时必须应用所有 17 个匹配条件,交易才能得到处理。完整的匹配条件集显示在表 2 中,以供参考。
表 2. 消息匹配条件
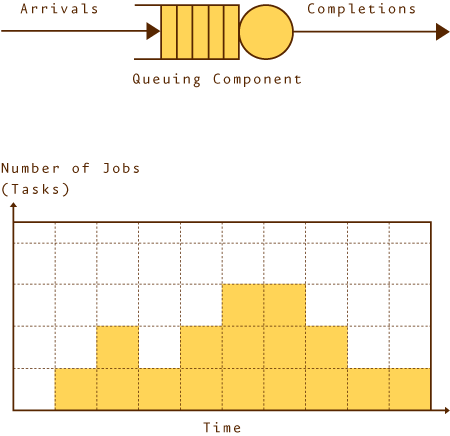
图 3. 简单的执行图
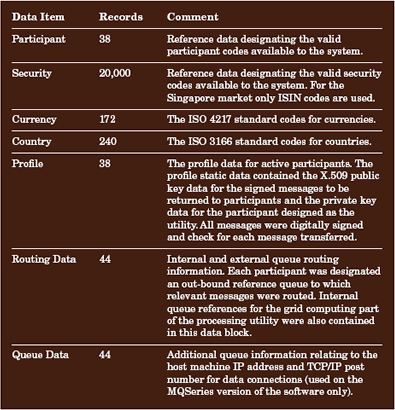
匹配过程需要在收到每个消息时,扫描消息数据库匹配表,以查找在每个消息中指定交易的所有元素。当扫描得到必需的 7 个匹配原子消息时,一个有效的 CLS 消息会被发送到测试系统的出站队列。除了匹配过程以外,新加坡市场的业务过程还要求验证某些消息项目内容的有效性,例如,货币和国家/地区名称、证券引用代码、付款和结算日期以及参与者标识信息。创建一个静态数据集合以构成该实用工具的基本参考数据,如表 3 所示。
表 3. 静态数据参数
为了建立基准结果,使用静态数据生成了测试消息集。消息生成器组件用来随机选择适当的静态数据,然后将其组合为由 7 个独立消息组成的标准交易。创建了两个核心消息集;第一个包含 250,000 个交易(1,750,000 个消息),第二个包含 1,000,000 个交易(7,000,000 个消息)。正常的业务周期要求所有匹配或未匹配的交易都在系统中保留 3 天,然后从系统数据库中清除;但是,我们决定保持所有已处理的交易信息,以便研究数据库性能随着容量的增加而恶化的情况。
消息集以 XML 格式存储在标准文本文件中,以便做好向处理引擎中传输的准备。为了监视基准并获得所需的性能衡量标准,构建了一组管理组件。这包括一个消息驱动程序组件、一个消息池组件以及一个附加组件(该组件按照固定时间间隔监视入站和出站消息队列的队列长度以及内部队列长度)。消息驱动程序组件按顺序处理测试消息集文件,并且在将它们发送到处理引擎的入站队列之前应用数字签名。
每个自主运行并且没有与系统中的其他进程发生争用的消息驱动程序都可以达到 8000 个消息/秒的处理速度。该数字非常接近于 Microsoft 为 MSMQ 产品提供的基准结果。消息池组件读取发往 CLS 队列的信息,并且监视通过系统处理给定数量的消息所花费的时间。监视组件在图 4中显示。
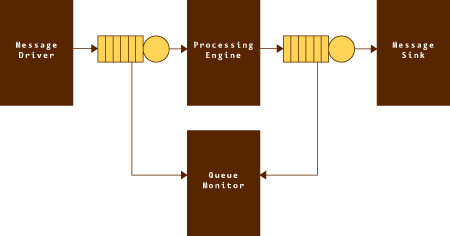
图 4. 基准监视装置
硬件环境
为处理实用工具建议的体系结构的性质有助于采用多台计算机来实现较高的性能。要在整个体系结构内部消除资源争用问题,使用多台单 CPU 计算机要比使用单台多 CPU 计算机更好。所使用的硬件是表 4 中显示的计算机集的 4 个实例。
表 4. 基本硬件环境 (x4)
为了在基准测试期间横向扩展处理功能,我们简单地部署了该基本硬件环境的多个副本。除了表 4中列出的硬件以外,还使用了 8 个单 CPU 计算机来承载消息驱动程序,并用来记录基准结果的监视和消息池组件。数据库被放置在针对级别 0 支持(最高吞吐量、最低可恢复性)配置的 Compaq MSA 1000 RAID(廉价磁盘冗余阵列)存储设备上。由于交易所实用工具的业务方案对于连接到该实用工具、灾难恢复站点和联机双系统冗余的每个参与者都要求具备本地(即客户端)数据库支持,所以与 RAID 级别 0 配置所提供的性能改进相比,失去 RAID 可恢复性是一个较小的代价。我们开始时认为单个数据库存储设备可以管理整个交易事务容量。但是,在执行基准测试期间,我们很快明白内部磁盘队列达到了极高的水平。稍后,我们将了解如何避免该问题。
软件环境
用于各种硬件平台和支持软件组件的软件操作环境在表 5 中列出。尽管在测试该基准时尚未发布 Windows Server 2003 的 RTM,但其候选产品 (RC1) 已经可以使用,并且人们认为它足够稳定和完整,可以作为基准的有效部分。所有适用的 Service Pack 都被应用于该操作环境,其中包括用于外围设备的任何第三方驱动程序。
表 5. 软件操作环境数据项参考
扩展体系结构
对于基准测试,向上扩展模型涉及到在 4 CPU 的计算机(比基本处理节点增加 2 台)上执行软件组件以及在 64 位 Itanium 处理器上执行代码。尽管 Itanium 计算机只包含 2 个处理器,但可用总线和 I/O 带宽要比标准 32 位平台高得多,并且得到的结果确实是鼓舞人心的。我们没有时间对向上扩展的模型进行彻底研究。我们利用的向外扩展模型要增加处理节点的数量:将处理引擎从 1 个增加到 8 个,将数据库处理器从 1 个增加到 4 个。我们花费了大量时间来研究向外扩展模型。
软件处理
STE 引擎组件是用 C/C++ 编写的。它们使用基于异常的试探法来处理 XML 消息:假设消息的内容和格式都是正确的,直到发生检测到错误(数据丢失或不正确)之类的情况为止。在发生异常时,有问题的消息被发送到指定的异常队列,以进行进一步的处理。后续异常解决过程没有包括在基准测试的范围中。每个消息内容的验证是针对已经预先加载到基于内存的数组中的静态数据进行的。验证过程涉及到将所需的静态数据组织到排序数组中(使用 C/C++ qsort 函数),以及通过查找该数组内部的项(使用 C/C++ bsearch 函数)来验证 XML 元素的存在。XML 消息中的数据元素是使用标准 C/C++ strstr 函数访问的。
基准结果
基准测试产生了一些有趣的结果。一些结果验证了应用程序设计,而其他结果则导致体系结构更改以便解决所识别的性能问题。我们得到的基本教训是:通常,需要调整以获得百分比级别的性能改善,需要重新设计架构以获得数量级的性能改善。
消息队列处理
基准测试是在两个基本级别进行的:第一个级别具有 250,000 个交易(175 万个消息),第二个级别具有 1,000,000 个交易(700 万个消息)。所有经过处理的信息都作为系统中的附加处理负载保留在数据库中。图 4 中显示的装置被用作基准评估的基础。在首次启动消息驱动程序组件时,我们注意到存在相当长的滞后时间,这主要是由于在处理消息流的单队列管理器中存在争用问题。
插入处理率是如此之高,以至于单队列管理器过程在每个运行的启动期间没有足够的时间将消息通过网络传输到远程处理计算机中。该问题导致的后果是,需要花费数秒钟进行初始传输,然后性能监视器才能在系统的处理节点上获得任何活动。图 5 解释了这一队列管理器争用过程。在实践中,几百万个消息作为单个输入到达该实用工具中几乎是不可能的事情,因此为了进行基准评估,可以忽略滞后效应。
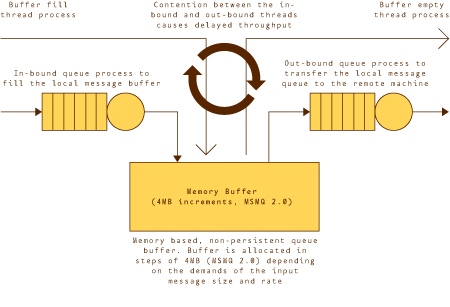
图 5. 单队列管理器争用过程
这一效应对于所有异步消息传输系统而言都是常见的,而不是仅限于用于基准的 MSMQ。当大量消息作为单个输入到达它们的入站队列(远程主机消息缓冲区)时,可以在处理组件中观察到类似的效应。这意味着在运行初始启动期间,处理组件会被推进到大约 100% 的载荷,然后在通过计算机的消息流平稳下来之后,就会趋向于稳定。
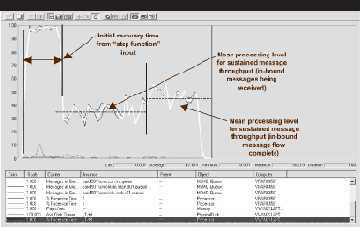
图 6. 典型组件的处理器时间
单个处理节点的典型性能监视器输出如图 6所示。在组合双处理器计算机的响应曲线中,可以清楚地看到初始消息爆炸的效应。
此外,在宿主计算机的响应图形的后半部分,可以看到流入队列管理器消息缓冲区中的入站消息完成处理的效应。这里,增加资源(或者更准确地说,减少争用)可以在处理周期的后面阶段中增加处理器能力的利用率。为了抵消过快地达到消息队列缓冲区限制以及在消息注入阶段发生不均匀的处理器利用率这两者产生的后果,我们添加了更大数量的入站队列过程和入站队列。这样,可以将入站消息负载聚集到更多的资源中,从而降低涉及到的滞后时间。
也许最大的差异是由使用 MSMQ 3.0 而不是 MSMQ 2.0 产生的。前者在进行新的缓冲区分配之前具有 4 GB 的内存缓冲区大小限制,这要比 MSMQ 2.03 中的 4 MB 缓冲区大小高三个数量级。
多节点处理
在 STE 的原始设计中,使用了单个数据库。随着处理节点(运行组件软件的双处理器计算机)数量的增加,我们注意到总体处理速率发生了明显的下降。这一处理吞吐量方面的下降现象如图 7 所示,其原因在于数据库组件内部的争用。争用的原因不在于操作系统或组件软件问题,而在于 RAID 阵列中发生过度的磁盘排队现象。这意味着,用于将信息传输到 RAID 阵列磁盘中的可用带宽不能满足 STE 的软件元素所产生的需求。
在分析将信息插入到数据库中的速率时,可以最为容易地看到这一效应。单数据库服务器的性能图形如图 8 所示。这里,图 7 中所示的数据库服务器的相应性能图形表明对数据库进行的插入操作急剧减少,原因在于随着处理节点数量的增加,在 RAID 阵列中出现磁盘排队现象。由这一排队现象所导致的可用资源争用问题意味着在原始设计中,系统无法合理地应付 2 个以上的处理节点。下一节讨论我们如何克服该问题。
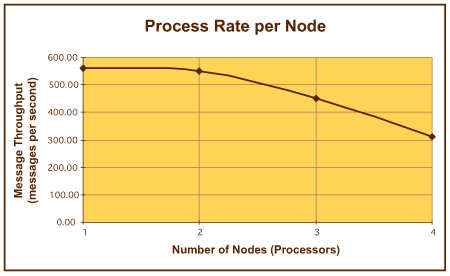
图 7. 每个节点的处理速率
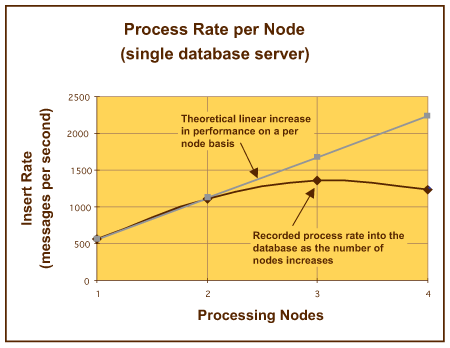
图 8. 每个节点的处理速率(单数据库引擎)
服务器哈希算法
在与 Microsoft SQL Server 团队就增加磁盘操作可用带宽的技术进行讨论之后,他们建议我们使用哈希算法,以便能够将多个数据库服务器结合到总体解决方案中。哈希算法的目的是对从消息数据中派生的交易使用唯一键,并且使用相应的哈希函数来产生能够解析为唯一的数据库服务器实例的单个数值。
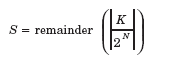
我们选择一个哈希算法以反映我们的业务需要,即总是将特定交易的组成消息发送到同一数据库服务器。对于基准,该键由表 2 中定义的匹配条件的子集组成。该键是通过将匹配条件值的选定子集串联起来,然后将其转换为单个非常长的整数构建而成的。然后,用表示所建议数据库服务器(或实例)数量的二进制值除以该数字,如下面的公式所示:
使用该公式4,我们通过用哈希来联合多个数据库服务器(或实例),非常有效地改善了性能。我们修改了所建议的实用工具的基础结构体系结构,以反映使用哈希算法包含多数据库解决方案这一事实,如图 9 所示。为了进行持续的基准测试,在软件组件内部提供了对最多 16 个数据库服务器的支持;但是,该系统是针对最多 4 个此类服务器进行的测试。使用哈希算法将数据库负载分布到四个数据库服务器中以重复执行上述测试时,产生了令人印象深刻的结果。
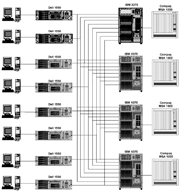
图 9. 最终的硬件基础结构方案
Little's Law 曲线
Buzen 和 Denning 所确定的性能衡量标准基于由 J.D.C. Little [LITTL61] 产生的基础结果。Little 所发现的一般化性能特征如图 10 所示。
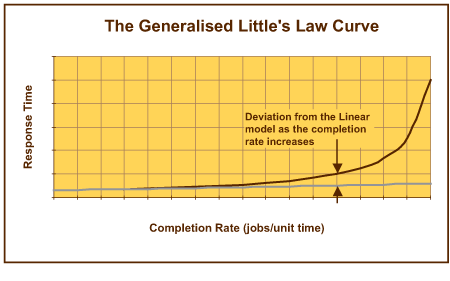
图 10. 一般化 Little's Law 曲线
对于任何队列模型,当处理特定数量的任务时,响应时间随着到达速率(对于均衡队列模型而言,为完成速率)的增加而增加。该曲线的特征是:在较早的阶段几乎是线性的,然后随着输入(和完成速率)的增加而逐渐变得更加类似于渐近线。
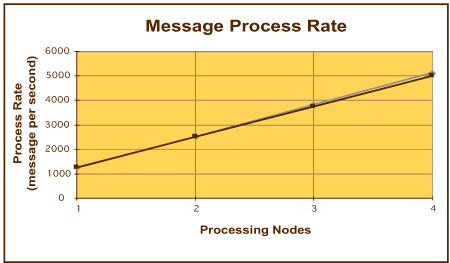
图 11. 通过多个数据库实例进行线性扩展(单数据库引擎)
第一个可以观察到的结果(图 11)表明,可用数据库带宽增加 400% 时,系统处于性能图形的线性部分,而随着处理组件从 1 个节点扩展到 4 个节点,产生了几乎线性的响应特征。实际上,所测定的结果在 1个和 4 个处理节点之间显示了极为线性的扩展,只与可观察到的线性模型存在非常小的偏差。但是,如果输入速率增加(在该示例中,通过将处理节点的数量增加到 8),则可以观察到与线性扩展情况之间的偏差。图 12显示所测定的这一效应。
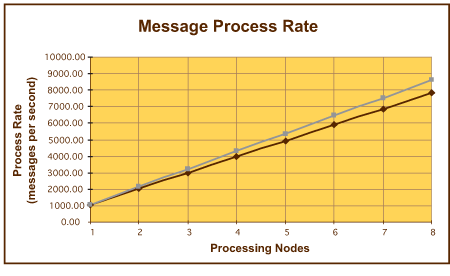
图 12. 八个处理节点性能曲线的可伸缩性
使用测定的结果,可以为测试队列网络模型绘制 Little's Law 曲线,如图 13 所示。结果显示,当处理节点的数量超过 4 个组件时,随着该数量的不断增加,队列模型的操作性能的下降越来越厉害,并且在增加到8个处理组件时,操作性能显著下降。
此时,值得注意的是,图 12中的图形左侧的刻度显示,整个 STE 队列模型的吞吐率大约为 7734 个消息/秒。显然,下一个要使用的扩展选项是将数据库服务器的个数增加到 8(即下一个可用的二进制倍数)。这样,只要适当增加所使用的处理节点的数量,我们就有理由期望看到消息处理吞吐率超过 15,000 个消息/秒。
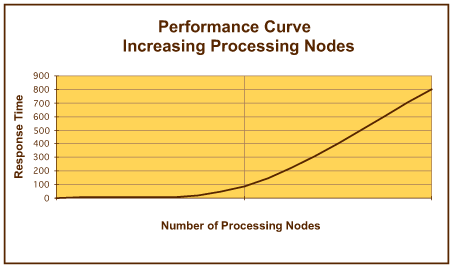
图 13:测定的 Little's Law 曲线
性能随着存储卷的增加而下降
在测定的处理速率,队列网络可以获得超过 27,842,400 个消息/小时(即 222,739,200 个消息/营业日)的稳定速率。在几分钟内测定的如此之高的处理速率能否持续下去?产生这样的疑问是合情合理的。为了确定该模型随着存储卷的增加而具有的特征,我们使用大约 2,000,000 个消息的处理负载作为基本数字,并且随后使用 7,000,000 个消息的处理运行,以便确定数据库卷的增加对总体性能的影响。所测定的消息吞吐量随着卷的增加而下降的情况如图 14所示。
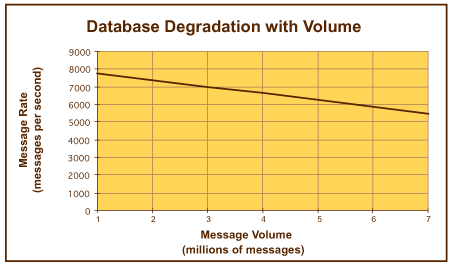
图 14. 数据库性能随着存储卷的增加而下降
这里,随着所处理的卷达到 7,000,000 个消息的目标,处理速率下降到 5,500 个消息/秒。即使是处于这一极端水平,队列模型也达到了大约 19,800,000 个消息/小时(即 158,400,000 个消息/营业日)的吞吐速率。除了这里显示的线性近似以外,结果的粒度不允许对性能下降效应进行更准确的测量。如果进行更细粒度的观察,则可以看到性能下降的速率将是一条曲线,而不是一条直线,这表明随着卷进一步增加,性能下降效应将会降低(这可能是用于现代 RDBMS 的 B 树结构的分页架构的特征)。
在该测试期间处理的 7,000,000 个消息代表着在相当短的时间内处理了 1,000,000 个交易。值得注意的是,在金融服务业中,有很多现有事务引擎的示例,虽然它们使用技术的额定性能级别高于在上述测试中使用的 Windows 计算机和基于 Intel 的计算机,但却无法达到这一操作水平。
Buzen 和 Denning 结果
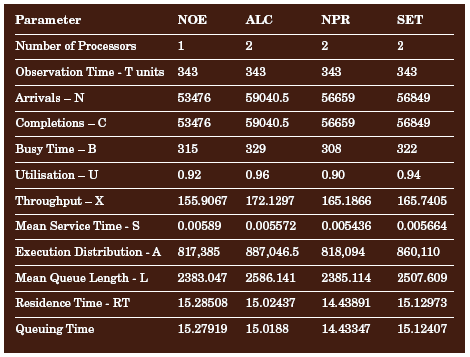
要确定单个组件的性能,需要确定 Buzen 和 Denning 衡量标准。监视过程测量用于队列网络模型的每个处理队列的长度,并且计算性能衡量标准。该计算过程中的一个示例结果如表 6 所示。
表 6. 示例 Buzen 和 Denning 结果计算
该示例显示了通过该队列模型处理的大约 398,573 个消息(取自两个处理节点之一,以作为示例)。支持 7 个软件组件(一个 NOE 组件以及 ALC、NPR 和 SET 软件模块各一个)的主计算机在按照 Windows 性能监视工具确定的监视时间间隔 (U) 内达到平均 93% 的利用率。对于吞吐量计算,必须记住的是,对于 ALC、NPR 和 SET 消息类型中的每一个,都有两个处理组件在运行。
因此,处理网络在测试期间获得了大约 1,162 个消息/时间单位的平均吞吐率,而滞后时间大约为 14.97 秒。在这种情况下,滞后是指在输入和输出消息处理之间的时间差。在测定的处理级别,进入网络的消息将在大约 14.97 秒钟以后出现在输出端。
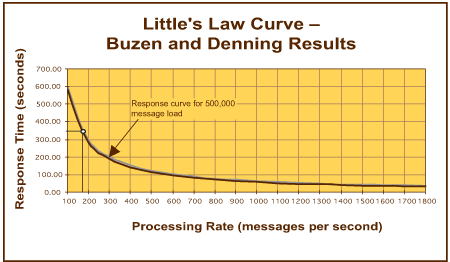
图 15. 测定的性能曲线
取样速率被设置为 7 秒时间间隔(因为使用了未校准的走时间隔),并且取样数据集为 500,000 个消息(两个消息驱动程序,每个带有来自标准测试数据集的 250,000 个消息)。在该示例中,有两个处理引擎(或主计算机),并且显示的结果取自这两个处理引擎中的一个(请注意,ALC、NPR 和 SET 组件的结果是在两个组件中经过聚集得到的,因为原始数据是根据用来向这两个组件提供消息的消息队列测定的)。NOE 消息略高的服务时间 (S) 反映出要求该组件具有更高的处理级别,原因在于审核线索持久性和验证处理。
图 15显示每个处理组件的性能曲线,并且标记总体性能点以便更加明确。这基本上就是 STE 处理引擎的一般化 Little's Law 曲线;但是,该一般化视图并未给出准确预测该引擎的操作性能所需的所有详细信息。显然,对于单个组件而言存在不同的完成速率,因此,根据您希望获得的性能衡量标准视图的不同,存在不同的相应性能值。这就造成该网络的性能操作区域 (POR),如图 16 中阴影区域所示。在该特定实例中,结果相当接近,因此相应的性能操作区域很狭窄。
但是,情况并非总是如此,在一些系统示例中,POR 覆盖的区域超过了平均性能水平的四倍。预测 POR 需要一些复杂的数学知识,这些知识超出了该基准练习的范围;但是,这里包含了 POR 的影响,以便解释在重复测试期间测定的结果的变动。
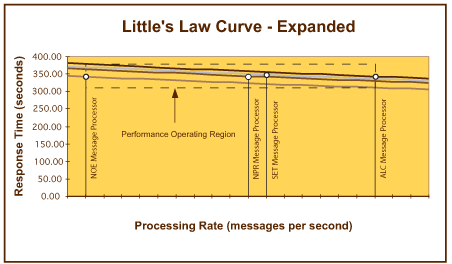
图 16. 测得的 Little's Law 曲线 评价和结论
基准令人印象深刻的结果是不言而喻的,并且能够很好地确定总体性能、可伸缩性和灵活性。整个引擎的吞吐率无疑使其成为金融服务业中交易后处理基础结构的一些最大的事务引擎之一。目标和弹性性能级别可以适当地稍微超出,并且有强烈的迹象表明,总体体系结构方法可以支持更大的消息吞吐量。无疑,值得说明的是借助于所获得的性能级别,Microsoft 当前提供的技术能够在任何金融机构的企业层内操作。企业层内部操作的某些方面(如弹性和可靠性)没有在该基准中进行测试,有待于针对该设计予以证明。但是,像这样的基于网络或网格计算的体系结构具有内在的特征,能够支持极高级别的弹性和可靠性。因此,使用高效的基于网格的处理计算机和低成本软件技术似乎是一个吸引人的组合。
低成本和高效实现
整个基准过程的更为重要的结果之一很可能是 Microsoft 技术现在已经证明能够发挥作用并扩展到企业级别。通过队列体系结构获得的处理速率无疑使 Microsoft 操作系统在网络计算领域具有了较高的功能和可伸缩性。该测试的第二个最为重要的结果是,在 Microsoft 环境中实现该系统的成本相当低。
潜在的提高领域
除了用来将基准结果细化的监视工具以外,Microsoft 还能够提供其他过程监视工具(这些工具将在 Visual Studio 2005 中提供),以便提供软件元素执行的详细视图。Microsoft 分析工具表明,软件组件平均花费了其时间的 30% 到 35% 来执行与从 XML 消息中提取数据相关的函数。这并不是一个令人过度吃惊的结果,因为软件组件的主要功能是验证和处理字符串类型。为了访问必需的信息,我们使用了 C/C++ strstr 搜索函数,并且将整个消息视为一个复杂字符串。(注意:对于我们的问题域而言,这要比直接使用 XML 分析器和带有 XSLT 的 DOM 对象快。)
尽管在普通环境中,使用 strstr 可以提供足够的性能级别,但还有一些可以用来从基于字符串的消息结构中提取信息的更为高效的技术。R.S. Boyer 和 J.S. Moore [BYMR77] 描述了一种用于搜索具有良好结构的字符串的非常高效的机制。当字符串的结构事先已知,并且字符串主要用在必需搜索大型文本字符串的应用程序(例如,数字库应用程序、编辑器或字处理器)中时,该算法可以很好地工作。
对于队列网络而言,使用该算法乍看起来似乎是不适当的,因为我们无法确定该网络内部收到的下一个消息结构的性质。但是,对于处理组件而言,该消息的结构是已知的,因为我们按照类型路由该消息,以便进行进一步的处理。使用 Boyer-Moore 算法可以在网络的现有实现上产生改进的结果;但是,对于 Boyer Moore 算法而言,XML 消息可能太小了(每个消息平均为 1,500 字节),以至于该算法无法产生使实现它所需的工作显得有价值的结果。
Itanium 和 64 位处理
队列网络模型的操作是使用在新的(起码当时是)Itanium 64 位硬件和 Windows 操作系统上运行的 SQL Server 的测试版测试的。尽管不能将该环境接受为生产基准环境(因为使用的是测试软件),但相应的结果可以指示将来使用这一未来的 Intel/Microsoft 技术所能得到的性能收益。在该硬件上,测定的吞吐量为平均 872 个消息/秒,考虑到执行测试的环境,我们认为该值是非常高的。首先,该结果是使用标准 SCSI 磁盘单元而不是在主要基准练习中使用的 RAID 阵列获得的。标准 SCSI 的性能要比 RAID 的性能低得多。其次,Itanium 数据库服务器只安装了两个处理器,而基准测试中的数据库引擎则使用了 8 个处理器。我们迫切期待在 64 位环境内执行完整基准测试的机会。
C# 和托管代码
我们还生成了软件组件,以便在 Microsoft C# 托管代码环境(在该环境中,可以在 C/C++ 和 C# 版本之间进行直接的比较)中使用。作为一项简单的测试,我们在操作模型之间比较了消息驱动程序的操作。所涉及到的过程相当简单,以便可以忽略低效编码的影响(实际起作用的代码行很少)。该过程需要获得准备好的消息文件,并且将数据流式输入到代码循环中。处理将一直进行,直到收到消息分隔符为止。
然后,将得到的消息包装到标准 GSTPA 标头中,并且向该消息块应用数字签名。接下来,将该消息写入到消息队列中,以便队列网络模型进行处理。该过程一直进行,直到所准备的整个文件被读取为止。我们感兴趣的参数是用来从数据文件中读取消息并将其排队的吞吐率。该测试的结果显示在图 17中。[这些结果清楚地表明,托管代码环境 (.NET Framework 1.1) 上的 C/C++ 的性能提高了。]
同样,指出以下事实也是理所当然的:结果还包括 C/C++ 和 C# 之间的互操作层(在访问 MSMQ 时,需要越过该层)的效率比较。乍看起来,有人可能会争辩说从性能角度而言,永远都不应该实现托管代码环境来代替 C/C++ 安装。但是,这一观点可能会令人误解,因为所有系统解决方案都是成本、性能和可靠性之间的折衷。
托管代码环境的总体性能结果反映了在产生大约 2000 个消息/秒的吞吐率的(简单)消息驱动程序组件上执行的测试。尽管该吞吐率是基础 C/C++ 级别的 25% 左右,但一定有必须考虑的补偿因素。C# 代码的生产效率要比可以通过 C/C++ 代码得到的生产效率高得多;实际上,用 C# 开发操作代码的速度给人留下了极为深刻的印象。
请注意,2000 个消息/秒(相当于 7,200,000 个消息/小时或 57,600,000 个消息/天)的较低吞吐率仍然被视为处于较高的事务引擎基准范围,并且随着托管代码变得更快,它只会变得更好。

图 17. 托管代码和非托管代码的比较
此外,在比较托管和非托管代码环境时必须小心。使用虚拟机环境(像 .NET Framework 中使用的公共语言运行库 (CLR))甚至基于 Java/J2EE VM 的环境可以产生与涉及基于内存的操作的 C/C++ 代码相当的基准数字。遗憾的是,这样的基准比较会使人对可以期望的总体性能级别产生错误的印象,因为大多数应用程序都包含本地和远程 I/O 操作的元素以及动态对象创建和删除。
相反,托管代码环境具有易于实现并且可以在可靠性和可管理性方面进行改进的优点,这使其能够在创建牺牲性能以换取较低的成本和较快的实现速度的应用程序时优越于 C/C++。假设对于 STE 系统的非托管代码实现,我们具有重要的难以实现的性能(参阅有关该主题的上述讨论),则由于该体系结构可以如此卓越地向上扩展,我们实际上是处于一个非常有利的位置,即我们可以对这一难以实现的性能加以折衷,以获得在该一般化体系结构的将来实现中使用托管代码的好处。 |