论文地址:Deep Residual Network for Joint Demosaicing and Super-Resolution
一、简介
简介去马赛克(demosaicing)和超分辨率(super-resolution)各自领域的研究概况以及两者之间的关系(本质上都是图像重构的过程),并阐述了两种研究各自的缺陷——产生图像伪影等非真实的人造特征,两种算法的分别进行使误差叠加从而更加明显。于是作者提出将两个步骤合并在一起进行,提出一种进行去马赛克和超分算法的联合神经网络结构,从而减少图像伪影的出现,避免误差迭代增强,一些常见的分别处理生成的伪影都在这个联合过程中都消除了。(从图一确实可以看出作者提出的算法效果)
此外,超分辨率方法通常只对亮度通道进行超分辨率(而对色度通道进行插值),与之不同的是,作者的网络直接生成全色的三通道超分辨率输出。

图一
二、相关工作
首先简要介绍了CFA阵列(主要是拜尔阵列)的原理,然后分别给出近年来(2018年以前)的去马赛克和超分辨率领域各自的发展历程、经典算法及其优劣。首先作者举出几种较为代表性的去马赛克算法包括各种经典的线性插值算法、FlexISP方法、SEM框架以及在去马赛克算法中应用神经网络的开山鼻祖DemosaicNet网络。然后列举了单一去马赛克算法的弊端——容易产生各种图像伪影,如假着色(false coloring)、摩尔纹(Moiré effect)以及拉链伪影(zippering)等(具体图像例举见图二,三张图分别出现了假着色、摩尔纹效应和拉链伪影)。
 图二
图二
然后作者又分析了超分辨率算法的发展历程。由稀疏编码的方法发展至各种逐渐复杂的卷积神经网络方法,后来也出现了更复杂的包含跳层连接和残差网络块的神经网络。但是他们有一个普遍问题,就是几乎所有超分辨率方法均是对图像的其中一个通道——亮度通道(Y通道)进行超分辨率(理由是人眼对于光的亮度比对颜色更加敏感),而对其他两个通道(CbCr通道)进行简单的双三次插值,再与超分后的Y通道拼合。这样做的缺点是它们没有充分利用各色带的相关性,当颜色伪影是从较低分辨率的图像中继承过来时,这些方法可能会产生质量较差的输出。
三、提出模型
如图三,作者首先给出了一幅图像从自然界的真实场景最后变成Bayer阵列的过程——首先经过了图像传感器的采集后相当于经过了一层滤波,给图像造成了模糊和噪声,然后再经历了下采样分辨率降低,最后采样得到拜尔阵列。作者的目的是希望近似给出这个过程的逆过程,使得给出输入为拜尔阵列,输出得到的ISR能够尽量接近IHR。一般来说,输入IBayer是一个大小为H × W × 1的实值张量,而IHR是大小为r*H × r*W × 3的张量。 这个问题是高度不适定的(什么是不适定呢,可以简单理解为一个输入对应多个可能的输出,即解不唯一且不稳定,具体请看参考博客),因为下采样和马赛克效应都是不可逆过程。为了解决这个问题,传统方法通常会设计非线性的滤波器,结合关于通道间和通道内相关性的先验的启发式方法。然而深度卷积神经网络是此类方法的更好替代品,因为卷积层可以通过大量的训练图像数据自动学习利用通道间和通道内的相关性。此外,单独使用一组卷积层可以使所有的参数联合优化,以集中最小化一个目标,就像文章中的任务——联合去马赛克和超分辨率一样。因此,作者以数据驱动的方式构建网络框架:从一大组高质量的图像IHR中创建训练集,并使用与图中所示的图像形成模型相同的过程产生输入IBayer。然后在这个数据集上训练作者提出的CNN。

图三
从概念上来说(我也不知道为什么文章中屡次出现Conceptually这个词,可能对于许多约定俗成的理论就类似着“显然”的作用吧orz),用于图像重构的CNN一般分为三个部分——色彩提取、特征提取与非线性映射,以及高分辨率图像重建。基于此作者提出了网络的大致结构如图四。这是一个前馈的全连接卷积神经网络,目的是为了实现ISR = F(IBayer)这一步中的映射F。
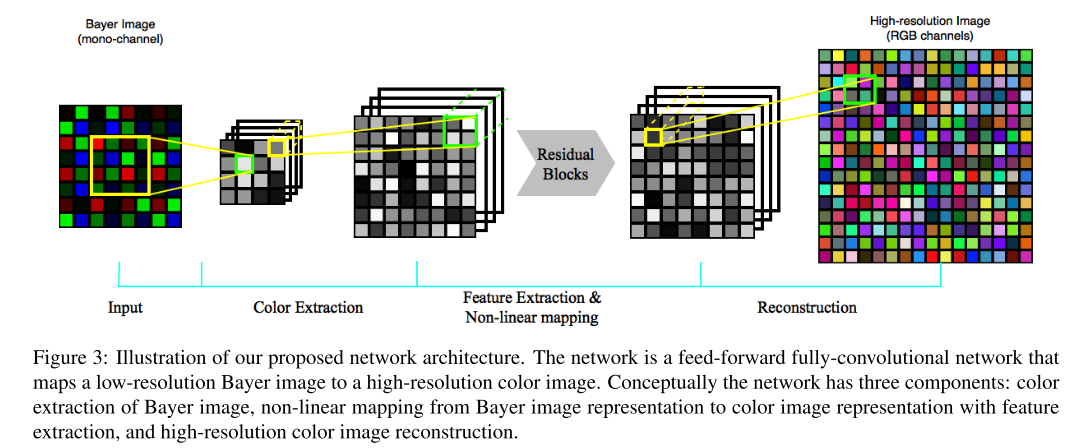
图四
1.颜色提取
第一步将拜尔阵列的单通道分离成多个颜色通道。拜耳图像是一个矩阵,三个颜色通道样本以一个通道的规律排列。为了保证平移不变性的同时降低后面的计算成本,必须在一开始就将拜耳图像中的颜色分成不同的通道。拜耳图案是有规律的,空间结构大小为s × s,其中s=2,由于相邻颜色也可能影响输出结果,作者建的第一个卷积层L1,空间大小为2*s,步长为s。即:
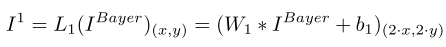
其中W1为大小为2*s × 2*s(即4 × 4)深度为C=256的卷积核。同时还建立了一个亚像素卷积层L2,将颜色特征上采样回原始分辨率,即:

实验证明此亚像素层可以减少棋盘效应。同时,由于以上几步的操作都是线性的,在前两层中没有引入ReLu激活函数。
2.特征提取&非线性映射
为了探索每个颜色通道内和通道之间的关系,以及在高分辨率的流形中重现拜耳图像,作者在这一步骤中利用了一组卷积层。借鉴之前的许多网络,在从低级到高级任务的计算机视觉问题中,残差网络在准确度和训练速度上都表现出优异的性能。于是作者就构建了一组nb个残差块,每个残差块的架构与Enhanced Deep Residual Networks for Single Image Super-Resolution这篇文章中的结构类似,如图五所示。同时,为了保持网络输出范围的灵活性,作者去掉了其中所有的BatchNorm层;而且为了避免神经元退化和梯度消失等问题,作者用PReLu来代替ReLu函数。同时残差网络的每个通道数均为256。
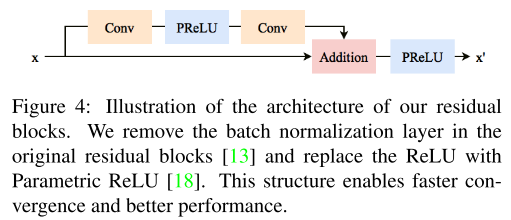 图五
图五
3.图像重构
在重建阶段,借鉴ESPCN里的sub-pixel(亚像素)结构,将通道数减少4倍从而使得图像的高和宽分别提升两倍,达到超分辨率的目的。网络的整体结构如图六所示。

图六
参考博客:心中无码,自然高清 || 联合去马赛克与超分辨率研究论文Pytorch复现
图像伪影:http://www.shunlioptotech.com/afscope/wap_doc/4897284.html
不适定问题:计算机视觉中的不适定问题(ill-posed problem)