在本章中,我们将给出几个使用数据库的Tornado Web应用的例子。我们将从一个简单的RESTful API例子起步,然后创建3.1.2节中的Burt's Book网站的完整功能版本。
本章中的例子使用MongoDB作为数据库,并通过pymongo作为驱动来连接MongoDB。当然,还有很多数据库系统可以用在Web应用中:Redis、CouchDB和MySQL都是一些知名的选择,并且Tornado自带处理MySQL请求的库。我们选择使用MongoDB是因为它的简单性和便捷性:安装简单,并且能够和Python代码很好地融合。它结构自然,预定义数据结构不是必需的,很适合原型开发。
在本章中,我们假设你已经在机器上安装了MongoDB,能够运行示例代码,不过也可以在远程服务器上使用MongoDB,相关的代码调整也很容易。如果你不想在你的机器上安装MongoDB,或者没有一个适合你操作系统的MongoDB版本,你也可以选择一些MongoDB主机服务。我们推荐使用MongoHQ。在我们最初的例子中,假设你已经在你的机器上运行了MongoDB,但使用远程服务器(包括MongoHQ)运行的MongoDB时,调整代码也很简单。
我们同样还假设你已经有一些数据库的经验了,尽管并不一定是特定的MongoDB数据库的经验。当然,我们只会使用MongoDB的一点皮毛;如果想获得更多信息请查阅MongoDB文档(http://www.mongodb.org/display/DOCS/Home)让我们开始吧!
4.1 使用PyMongo进行MongoDB基础操作
在我们使用MongoDB编写Web应用之前,我们需要了解如何在Python中使用MongoDB。在这一节,你将学会如何使用PyMongo连接MongoDB数据库,然后学习如何使用pymongo在MongoDB集合中创建、取出和更新文档。
PyMongo是一个简单的包装MongoDB客户端API的Python库。你可以在http://api.mongodb.org/python/current/下载获得。一旦你安装完成,打开一个Python解释器,然后跟随下面的步骤。
4.1.1 创建连接
首先,你需要导入PyMongo库,并创建一个到MongoDB数据库的连接。
>>> import pymongo
>>> conn = pymongo.Connection("localhost", 27017)
前面的代码向我们展示了如何连接运行在你本地机器上默认端口(27017)上的MongoDB服务器。如果你正在使用一个远程MongoDB服务器,替换localhost和27017为合适的值。你也可以使用MongoDB URI来连接MongoDB,就像下面这样:
>>> conn = pymongo.Connection( ... "mongodb://user:password@staff.mongohq.com:10066/your_mongohq_db")
前面的代码将连接MongoHQ主机上的一个名为your_mongohq_db的数据库,其中user为用户名,password为密码。你可以在http://www.mongodb.org/display/DOCS/Connections中了解更多关于MongoDB URI的信息。
一个MongoDB服务器可以包括任意数量的数据库,而Connection对象可以让你访问你连接的服务器的任何一个数据库。你可以通过对象属性或像字典一样使用对象来获得代表一个特定数据库的对象。如果数据库不存在,则被自动建立。
>>> db = conn.example or: db = conn['example']
一个数据库可以拥有任意多个集合。一个集合就是放置一些相关文档的地方。我们使用MongoDB执行的大部分操作(查找文档、保存文档、删除文档)都是在一个集合对象上执行的。你可以在数据库对象上调用collection_names方法获得数据库中的集合列表。
>>> db.collection_names() []
当然,我们还没有在我们的数据库中添加任何集合,所以这个列表是空的。当我们插入第一个文档时,MongoDB会自动创建集合。你可以在数据库对象上通过访问集合名字的属性来获得代表集合的对象,然后调用对象的insert方法指定一个Python字典来插入文档。比如,在下面的代码中,我们在集合widgets中插入了一个文档。因为widgets集合并不存在,MongoDB会在文档被添加时自动创建。
>>> widgets = db.widgets or: widgets = db['widgets'] (see below)
>>> widgets.insert({"foo": "bar"})
ObjectId('4eada0b5136fc4aa41000000')
>>> db.collection_names()
[u'widgets', u'system.indexes']
(system.indexes集合是MongoDB内部使用的。处于本章的目的,你可以忽略它。)
在之前展示的代码中,你既可以使用数据库对象的属性访问集合,也可以把数据库对象看作一个字典然后把集合名称作为键来访问。比如,如果db是一个pymongo数据库对象,那么db.widgets和db['widgets']同样都可以访问这个集合。
4.1.2 处理文档
MongoDB以文档的形式存储数据,这种形式有着相对自由的数据结构。MongoDB是一个"无模式"数据库:同一个集合中的文档通常拥有相同的结构,但是MongoDB中并不强制要求使用相同结构。在内部,MongoDB以一种称为BSON的类似JSON的二进制形式存储文档。PyMongo允许我们以Python字典的形式写和取出文档。
为了在集合中 创建一个新的文档,我们可以使用字典作为参数调用文档的insert方法。
>>> widgets.insert({"name": "flibnip", "description": "grade-A industrial flibnip", "quantity": 3})
ObjectId('4eada3a4136fc4aa41000001')
既然文档在数据库中,我们可以使用集合对象的find_one方法来取出文档。你可以通过传递一个键为文档名、值为你想要匹配的表达式的字典来告诉find_one找到 一个特定的文档。比如,我们想要返回文档名域name的值等于flibnip的文档(即,我们刚刚创建的文档),可以像下面这样调用find_oen方法:
>>> widgets.find_one({"name": "flibnip"})
{u'description': u'grade-A industrial flibnip',
u'_id': ObjectId('4eada3a4136fc4aa41000001'),
u'name': u'flibnip', u'quantity': 3}
请注意_id域。当你创建任何文档时,MongoDB都会自动添加这个域。它的值是一个ObjectID,一种保证文档唯一的BSON对象。你可能已经注意到,当我们使用insert方法成功创建一个新的文档时,这个ObjectID同样被返回了。(当你创建文档时,可以通过给_id键赋值来覆写自动创建的ObjectID值。)
find_one方法返回的值是一个简单的Python字典。你可以从中访问独立的项,迭代它的键值对,或者就像使用其他Python字典那样修改值。
>>> doc = db.widgets.find_one({"name": "flibnip"})
>>> type(doc)
<type 'dict'>
>>> print doc['name']
flibnip
>>> doc['quantity'] = 4
然而,字典的改变并不会自动保存到数据库中。如果你希望把字典的改变保存,需要调用集合的save方法,并将修改后的字典作为参数进行传递:
>>> doc['quantity'] = 4
>>> db.widgets.save(doc)
>>> db.widgets.find_one({"name": "flibnip"})
{u'_id': ObjectId('4eb12f37136fc4b59d000000'),
u'description': u'grade-A industrial flibnip',
u'quantity': 4, u'name': u'flibnip'}
让我们在集合中添加更多的文档:
>>> widgets.insert({"name": "smorkeg", "description": "for external use only", "quantity": 4})
ObjectId('4eadaa5c136fc4aa41000002')
>>> widgets.insert({"name": "clobbasker", "description": "properties available on request", "quantity": 2})
ObjectId('4eadad79136fc4aa41000003')
我们可以通过调用集合的find方法来获得集合中所有文档的列表,然后迭代其结果:
>>> for doc in widgets.find():
... print doc
...
{u'_id': ObjectId('4eada0b5136fc4aa41000000'), u'foo': u'bar'}
{u'description': u'grade-A industrial flibnip',
u'_id': ObjectId('4eada3a4136fc4aa41000001'),
u'name': u'flibnip', u'quantity': 4}
{u'description': u'for external use only',
u'_id': ObjectId('4eadaa5c136fc4aa41000002'),
u'name': u'smorkeg', u'quantity': 4}
{u'description': u'properties available on request',
u'_id': ObjectId('4eadad79136fc4aa41000003'),
u'name': u'clobbasker',
u'quantity': 2}
如果我们希望获得文档的一个子集,我们可以在find方法中传递一个字典参数,就像我们在find_one中那样。比如,找到那些quantity键的值为4的集合:
>>> for doc in widgets.find({"quantity": 4}):
... print doc
...
{u'description': u'grade-A industrial flibnip',
u'_id': ObjectId('4eada3a4136fc4aa41000001'),
u'name': u'flibnip', u'quantity': 4}
{u'description': u'for external use only',
u'_id': ObjectId('4eadaa5c136fc4aa41000002'),
u'name': u'smorkeg',
u'quantity': 4}
最后,我们可以使用集合的remove方法从集合中删除一个文档。remove方法和find、find_one一样,也可以使用一个字典参数来指定哪个文档需要被删除。比如,要删除所有name键的值为flipnip的文档,输入:
>>> widgets.remove({"name": "flibnip"})
列出集合中的所有文档来确认上面的文档已经被删除:
>>> for doc in widgets.find():
... print doc
...
{u'_id': ObjectId('4eada0b5136fc4aa41000000'),
u'foo': u'bar'}
{u'description': u'for external use only',
u'_id': ObjectId('4eadaa5c136fc4aa41000002'),
u'name': u'smorkeg', u'quantity': 4}
{u'description': u'properties available on request',
u'_id': ObjectId('4eadad79136fc4aa41000003'),
u'name': u'clobbasker',
u'quantity': 2}
4.1.3 MongoDB文档和JSON
使用Web应用时,你经常会想采用Python字典并将其序列化为一个JSON对象(比如,作为一个AJAX请求的响应)。由于你使用PyMongo从MongoDB中取出的文档是一个简单的字典,你可能会认为你可以使用json模块的dumps函数就可以简单地将其转换为JSON。但,这还有一个障碍:
>>> doc = db.widgets.find_one({"name": "flibnip"})
>>> import json
>>> json.dumps(doc)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
[stack trace omitted]
TypeError: ObjectId('4eb12f37136fc4b59d000000') is not JSON serializable
这里的问题是Python的json模块并不知道如何转换MongoDB的ObjectID类型到JSON。有很多方法可以处理这个问题。其中最简单的方法(也是我们在本章中采用的方法)是在我们序列化之前从字典里简单地删除_id键。
>>> del doc["_id"]
>>> json.dumps(doc)
'{"description": "grade-A industrial flibnip", "quantity": 4, "name": "flibnip"}'
一个更复杂的方法是使用PyMongo的json_util库,它同样可以帮你序列化其他MongoDB特定数据类型到JSON。我们可以在http://api.mongodb.org/python/current/api/bson/json_util.html了解更多关于这个库的信息。
4.2 一个简单的持久化Web服务
现在我们知道编写一个Web服务,可以访问MongoDB数据库中的数据。首先,我们要编写一个只从MongoDB读取数据的Web服务。然后,我们写一个可以读写数据的服务。
4.2.1 只读字典
我们将要创建的应用是一个基于Web的简单字典。你发送一个指定单词的请求,然后返回这个单词的定义。一个典型的交互看起来是下面这样的:
$ curl http://localhost:8000/oarlock
{definition: "A device attached to a rowboat to hold the oars in place",
"word": "oarlock"}
这个Web服务将从MongoDB数据库中取得数据。具体来说,我们将根据word属性查询文档。在我们查看Web应用本身的源码之前,先让我们从Python解释器中向数据库添加一些单词。
>>> import pymongo
>>> conn = pymongo.Connection("localhost", 27017)
>>> db = conn.example
>>> db.words.insert({"word": "oarlock", "definition": "A device attached to a rowboat to hold the oars in place"})
ObjectId('4eb1d1f8136fc4be90000000')
>>> db.words.insert({"word": "seminomadic", "definition": "Only partial
ly nomadic"})
ObjectId('4eb1d356136fc4be90000001')
>>> db.words.insert({"word": "perturb", "definition": "Bother, unsettle
, modify"})
ObjectId('4eb1d39d136fc4be90000002')
代码清单4-1是我们这个词典Web服务的源码,在这个代码中我们查询刚才添加的单词然后使用其定义作为响应。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import pymongo
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class Application(tornado.web.Application):
def __init__(self):
handlers = [(r"/(w+)", WordHandler)]
conn = pymongo.Connection("localhost", 27017)
self.db = conn["example"]
tornado.web.Application.__init__(self, handlers, debug=True)
class WordHandler(tornado.web.RequestHandler):
def get(self, word):
coll = self.application.db.words
word_doc = coll.find_one({"word": word})
if word_doc:
del word_doc["_id"]
self.write(word_doc)
else:
self.set_status(404)
self.write({"error": "word not found"})
if __name__ == "__main__":
tornado.options.parse_command_line()
http_server = tornado.httpserver.HTTPServer(Application())
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
在命令行中像下面这样运行这个程序:
$ python definitions_readonly.py
现在使用curl或者你的浏览器来向应用发送一个请求。
$ curl http://localhost:8000/perturb
{"definition": "Bother, unsettle, modify", "word": "perturb"}
如果我们请求一个数据库中没有添加的单词,会得到一个404错误以及一个错误信息:
$ curl http://localhost:8000/snorkle
{"error": "word not found"}
那么这个程序是如何工作的呢?让我们看看这个程序的主线。开始,我们在程序的最上面导入了import pymongo库。然后我们在我们的TornadoApplication对象的__init__方法中实例化了一个pymongo连接对象。我们在Application对象中创建了一个db属性,指向MongoDB的example数据库。下面是相关的代码:
conn = pymongo.Connection("localhost", 27017)
self.db = conn["example"]
一旦我们在Application对象中添加了db属性,我们就可以在任何RequestHandler对象中使用self.application.db访问它。实际上,这正是我们为了取出pymongo的words集合对象而在WordHandler中get方法所做的事情。
def get(self, word):
coll = self.application.db.words
word_doc = coll.find_one({"word": word})
if word_doc:
del word_doc["_id"]
self.write(word_doc)
else:
self.set_status(404)
self.write({"error": "word not found"})
在我们将集合对象指定给变量coll后,我们使用用户在HTTP路径中请求的单词调用find_one方法。如果我们发现这个单词,则从字典中删除_id键(以便Python的json库可以将其序列化),然后将其传递给RequestHandler的write方法。write方法将会自动序列化字典为JSON格式。
如果find_one方法没有匹配任何对象,则返回None。在这种情况下,我们将响应状态设置为404,并且写一个简短的JSON来提示用户这个单词在数据库中没有找到。
4.2.2 写字典
从字典里查询单词很有趣,但是在交互解释器中添加单词的过程却很麻烦。我们例子的下一步是使HTTP请求网站服务时能够创建和修改单词。
它的工作流程是:发出一个特定单词的POST请求,将根据请求中给出的定义修改已经存在的定义。如果这个单词并不存在,则创建它。例如,创建一个新的单词:
$ curl -d definition=a+leg+shirt http://localhost:8000/pants
{"definition": "a leg shirt", "word": "pants"}
我们可以使用一个GET请求来获得已创建单词的定义:
$ curl http://localhost:8000/pants
{"definition": "a leg shirt", "word": "pants"}
我们可以发出一个带有一个单词定义域的POST请求来修改一个已经存在的单词(就和我们创建一个新单词时使用的参数一样):
$ curl -d definition=a+boat+wizard http://localhost:8000/oarlock
{"definition": "a boat wizard", "word": "oarlock"}
代码清单4-2是我们的词典Web服务的读写版本的源代码。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import pymongo
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class Application(tornado.web.Application):
def __init__(self):
handlers = [(r"/(w+)", WordHandler)]
conn = pymongo.Connection("localhost", 27017)
self.db = conn["definitions"]
tornado.web.Application.__init__(self, handlers, debug=True)
class WordHandler(tornado.web.RequestHandler):
def get(self, word):
coll = self.application.db.words
word_doc = coll.find_one({"word": word})
if word_doc:
del word_doc["_id"]
self.write(word_doc)
else:
self.set_status(404)
def post(self, word):
definition = self.get_argument("definition")
coll = self.application.db.words
word_doc = coll.find_one({"word": word})
if word_doc:
word_doc['definition'] = definition
coll.save(word_doc)
else:
word_doc = {'word': word, 'definition': definition}
coll.insert(word_doc)
del word_doc["_id"]
self.write(word_doc)
if __name__ == "__main__":
tornado.options.parse_command_line()
http_server = tornado.httpserver.HTTPServer(Application())
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
除了在WordHandler中添加了一个post方法之外,这个源代码和只读服务的版本完全一样。让我们详细看看这个方法吧:
def post(self, word):
definition = self.get_argument("definition")
coll = self.application.db.words
word_doc = coll.find_one({"word": word})
if word_doc:
word_doc['definition'] = definition
coll.save(word_doc)
else:
word_doc = {'word': word, 'definition': definition}
coll.insert(word_doc)
del word_doc["_id"]
self.write(word_doc)
我们首先做的事情是使用get_argument方法取得POST请求中传递的definition参数。然后,就像在get方法一样,我们尝试使用find_one方法从数据库中加载给定单词的文档。如果发现这个单词的文档,我们将definition条目的值设置为从POST参数中取得的值,然后调用集合对象的save方法将改变写到数据库中。如果没有发现文档,则创建一个新文档,并使用insert方法将其保存到数据库中。无论上述哪种情况,在数据库操作执行之后,我们在响应中写文档(注意首先要删掉_id属性)。
4.3 Burt's Books
在第三章中,我们提出了Burt's Book作为使用Tornado模板工具构建复杂Web应用的例子。在本节中,我们将展示使用MongoDB作为数据存储的Burt's Books示例版本呢。
4.3.1 读取书籍(从数据库)
让我们从一些简单的版本开始:一个从数据库中读取书籍列表的Burt's Books。首先,我们需要在我们的MongoDB服务器上创建一个数据库和一个集合,然后用书籍文档填充它,就像下面这样:
>>> import pymongo
>>> conn = pymongo.Connection()
>>> db = conn["bookstore"]
>>> db.books.insert({
... "title":"Programming Collective Intelligence",
... "subtitle": "Building Smart Web 2.0 Applications",
... "image":"/static/images/collective_intelligence.gif",
... "author": "Toby Segaran",
... "date_added":1310248056,
... "date_released": "August 2007",
... "isbn":"978-0-596-52932-1",
... "description":"<p>[...]</p>"
... })
ObjectId('4eb6f1a6136fc42171000000')
>>> db.books.insert({
... "title":"RESTful Web Services",
... "subtitle": "Web services for the real world",
... "image":"/static/images/restful_web_services.gif",
... "author": "Leonard Richardson, Sam Ruby",
... "date_added":1311148056,
... "date_released": "May 2007",
... "isbn":"978-0-596-52926-0",
... "description":"<p>[...]>/p>"
... })
ObjectId('4eb6f1cb136fc42171000001')
(我们为了节省空间已经忽略了这些书籍的详细描述。)一旦我们在数据库中有了这些文档,我们就准备好了。代码清单4-3展示了Burt's Books Web应用修改版本的源代码burts_books_db.py。
import os.path
import tornado.locale
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
import pymongo
define("port", default=8000, help="run on the given port", type=int)
class Application(tornado.web.Application):
def __init__(self):
handlers = [
(r"/", MainHandler),
(r"/recommended/", RecommendedHandler),
]
settings = dict(
template_path=os.path.join(os.path.dirname(__file__), "templates"),
static_path=os.path.join(os.path.dirname(__file__), "static"),
ui_modules={"Book": BookModule},
debug=True,
)
conn = pymongo.Connection("localhost", 27017)
self.db = conn["bookstore"]
tornado.web.Application.__init__(self, handlers, **settings)
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.render(
"index.html",
page_title = "Burt's Books | Home",
header_text = "Welcome to Burt's Books!",
)
class RecommendedHandler(tornado.web.RequestHandler):
def get(self):
coll = self.application.db.books
books = coll.find()
self.render(
"recommended.html",
page_title = "Burt's Books | Recommended Reading",
header_text = "Recommended Reading",
books = books
)
class BookModule(tornado.web.UIModule):
def render(self, book):
return self.render_string(
"modules/book.html",
book=book,
)
def css_files(self):
return "/static/css/recommended.css"
def javascript_files(self):
return "/static/js/recommended.js"
if __name__ == "__main__":
tornado.options.parse_command_line()
http_server = tornado.httpserver.HTTPServer(Application())
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
正如你看到的,这个程序和第三章中Burt's Books Web应用的原始版本几乎完全相同。它们之间只有两个不同点。其一,我们在我们的Application中添加了一个db属性来连接MongoDB服务器:
conn = pymongo.Connection("localhost", 27017)
self.db = conn["bookstore"]
其二,我们使用连接的find方法来从数据库中取得书籍文档的列表,然后在渲染recommended.html时将这个列表传递给RecommendedHandler的get方法。下面是相关的代码:
def get(self):
coll = self.application.db.books
books = coll.find()
self.render(
"recommended.html",
page_title = "Burt's Books | Recommended Reading",
header_text = "Recommended Reading",
books = books
)
此前,书籍列表是被硬编码在get方法中的。但是,因为我们在MongoDB中添加的文档和原始的硬编码字典拥有相同的域,所以我们之前写的模板代码并不需要修改。
像下面这样运行应用:
$ python burts_books_db.py
然后让你的浏览器指向http://localhost:8000/recommended/。这次,页面和硬编码版本的Burt's Books看起来几乎一样(参见图3-6)。
4.3.2 编辑和添加书籍
我们的下一步是添加一个接口用来编辑已经存在于数据库的书籍以及添加新书籍到数据库中。为此,我们需要一个让用户填写书籍信息的表单,一个服务表单的处理程序,以及一个处理表单结果并将其存入数据库的处理函数。
这个版本的Burt's Books和之前给出的代码几乎是一样的,只是增加了下面我们要讨论的一些内容。你可以跟随本书附带的完整代码阅读下面部分,相关的程序名为burts_books_rwdb.py。
4.3.2.1 渲染编辑表单
下面是BookEditHandler的源代码,它完成了两件事情:
- GET请求渲染一个显示已存在书籍数据的HTML表单(在模板book_edit.html中)。
- POST请求从表单中取得数据,更新数据库中已存在的书籍记录或依赖提供的数据添加一个新的书籍。
下面是处理程序的源代码:
class BookEditHandler(tornado.web.RequestHandler):
def get(self, isbn=None):
book = dict()
if isbn:
coll = self.application.db.books
book = coll.find_one({"isbn": isbn})
self.render("book_edit.html",
page_title="Burt's Books",
header_text="Edit book",
book=book)
def post(self, isbn=None):
import time
book_fields = ['isbn', 'title', 'subtitle', 'image', 'author',
'date_released', 'description']
coll = self.application.db.books
book = dict()
if isbn:
book = coll.find_one({"isbn": isbn})
for key in book_fields:
book[key] = self.get_argument(key, None)
if isbn:
coll.save(book)
else:
book['date_added'] = int(time.time())
coll.insert(book)
self.redirect("/recommended/")
我们将在稍后对其进行详细讲解,不过现在先让我们看看如何在Application类中建立请求到处理程序的路由。下面是Application的__init__方法的相关代码部分:
handlers = [
(r"/", MainHandler),
(r"/recommended/", RecommendedHandler),
(r"/edit/([0-9Xx-]+)", BookEditHandler),
(r"/add", BookEditHandler)
]
正如你所看到的,BookEditHandler处理了两个不同路径模式的请求。其中一个是/add,提供不存在信息的编辑表单,因此你可以向数据库中添加一本新的书籍;另一个/edit/([0-9Xx-]+),根据书籍的ISBN渲染一个已存在书籍的表单。
4.3.2.2 从数据库中取出书籍信息
让我们看看BookEditHandler的get方法是如何工作的:
def get(self, isbn=None):
book = dict()
if isbn:
coll = self.application.db.books
book = coll.find_one({"isbn": isbn})
self.render("book_edit.html",
page_title="Burt's Books",
header_text="Edit book",
book=book)
如果该方法作为到/add请求的结果被调用,Tornado将调用一个没有第二个参数的get方法(因为路径中没有正则表达式的匹配组)。在这种情况下,默认将一个空的book字典传递给book_edit.html模板。
如果该方法作为到类似于/edit/0-123-456请求的结果被调用,那么isdb参数被设置为0-123-456。在这种情况下,我们从Application实例中取得books集合,并用它查询ISBN匹配的书籍。然后我们传递结果book字典给模板。
下面是模板(book_edit.html)的代码:
{% extends "main.html" %}
{% autoescape None %}
{% block body %}
<form method="POST">
ISBN <input type="text" name="isbn"
value="{{ book.get('isbn', '') }}"><br>
Title <input type="text" name="title"
value="{{ book.get('title', '') }}"><br>
Subtitle <input type="text" name="subtitle"
value="{{ book.get('subtitle', '') }}"><br>
Image <input type="text" name="image"
value="{{ book.get('image', '') }}"><br>
Author <input type="text" name="author"
value="{{ book.get('author', '') }}"><br>
Date released <input type="text" name="date_released"
value="{{ book.get('date_released', '') }}"><br>
Description<br>
<textarea name="description" rows="5"
cols="40">{% raw book.get('description', '')%}</textarea><br>
<input type="submit" value="Save">
</form>
{% end %}
这是一个相当常规的HTML表单。如果请求处理函数传进来了book字典,那么我们用它预填充带有已存在书籍数据的表单;如果键不在字典中,我们使用Python字典对象的get方法为其提供默认值。记住input标签的name属性被设置为book字典的对应键;这使得与来自带有我们期望放入数据库数据的表单关联变得简单。
同样还需要记住的是,因为form标签没有action属性,因此表单的POST将会定向到当前URL,这正是我们想要的(即,如果页面以/edit/0-123-456加载,POST请求将转向/edit/0-123-456;如果页面以/add加载,则POST将转向/add)。图4-1所示为该页面渲染后的样子。
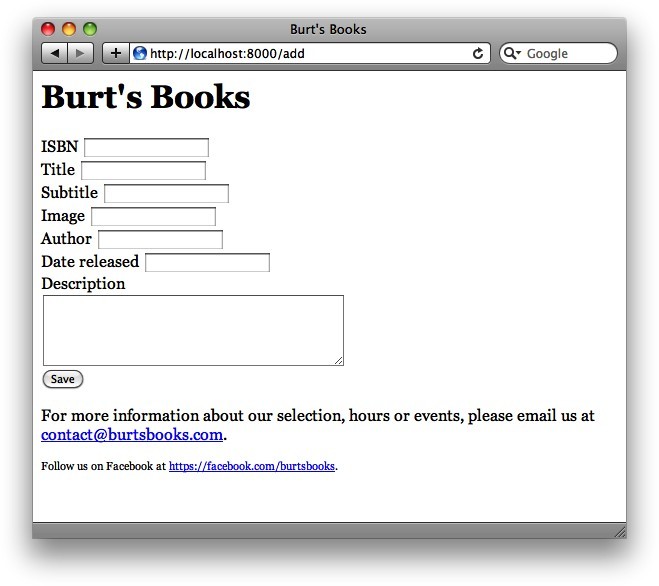
图4-1 Burt's Books:添加新书的表单
4.3.2.3 保存到数据库中
让我们看看BookEditHandler的post方法。这个方法处理书籍编辑表单的请求。下面是源代码:
def post(self, isbn=None):
import time
book_fields = ['isbn', 'title', 'subtitle', 'image', 'author',
'date_released', 'description']
coll = self.application.db.books
book = dict()
if isbn:
book = coll.find_one({"isbn": isbn})
for key in book_fields:
book[key] = self.get_argument(key, None)
if isbn:
coll.save(book)
else:
book['date_added'] = int(time.time())
coll.insert(book)
self.redirect("/recommended/")
和get方法一样,post方法也有两个任务:处理编辑已存在文档的请求以及添加新文档的请求。如果有isbn参数(即,路径的请求类似于/edit/0-123-456),我们假定为编辑给定ISBN的文档。如果这个参数没有被提供,则假定为添加一个新文档。
我们先设置一个空的字典变量book。如果我们正在编辑一个已存在的书籍,我们使用book集合的find_one方法从数据库中加载和传入的ISBN值对应的文档。无论哪种情况,book_fields列表指定哪些域应该出现在书籍文档中。我们迭代这个列表,使用RequestHandler对象的get_argument方法从POST请求中抓取对应的值。
此时,我们准备好更新数据库了。如果我们有一个ISBN码,那么我们调用集合的save方法来更新数据库中的书籍文档。如果没有的话,我们调用集合的insert方法,此时要注意首先要为date_added键添加一个值。(我们没有将其包含在我们的域列表中获取传入的请求,因为在图书被添加到数据库之后date_added值不应该再被改变。)当我们完成时,使用RequestHandler类的redirect方法给用户返回推荐页面。我们所做的任何改变可以立刻显现。图4-2所示为更新后的推荐页面。
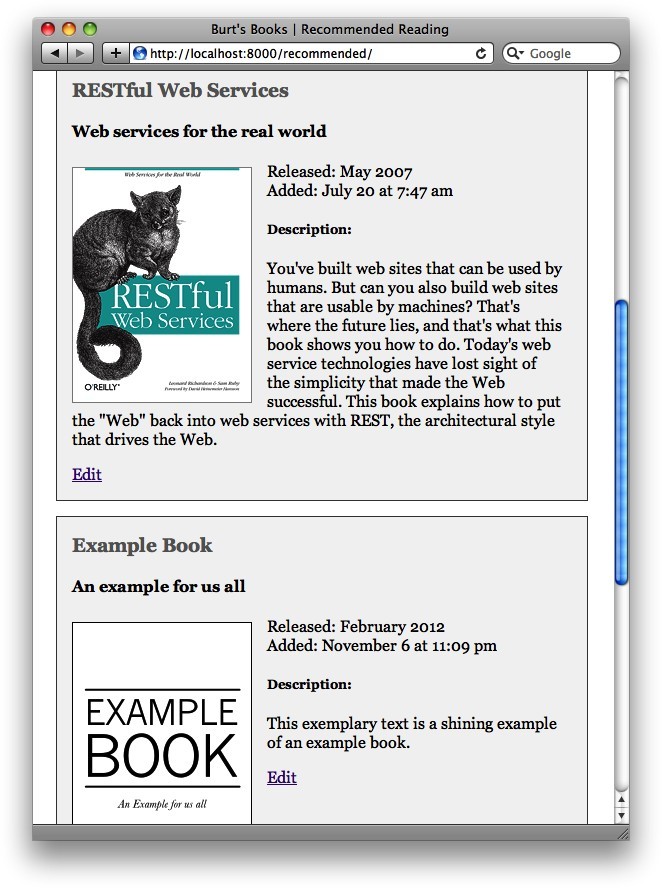
图4-2 Burt's Books:带有新添加书籍的推荐列表
你还将注意到我们给每个图书条目添加了一个"Edit"链接,用于链接到列表中每个书籍的编辑表单。下面是修改后的图书模块的源代码:
<div class="book" style="overflow: auto">
<h3 class="book_title">{{ book["title"] }}</h3>
{% if book["subtitle"] != "" %}
<h4 class="book_subtitle">{{ book["subtitle"] }}</h4>
{% end %}
<img src="{{ book["image"] }}" class="book_image"/>
<div class="book_details">
<div class="book_date_released">Released: {{ book["date_released"]}}</div>
<div class="book_date_added">Added: {{ locale.format_date(book["date_added"],
relative=False) }}</div>
<h5>Description:</h5>
<div class="book_body">{% raw book["description"] %}</div>
<p><a href="/edit/{{ book['isbn'] }}">Edit</a></p>
</div>
</div>
其中最重要的一行是:
<p><a href="/edit/{{ book['isbn'] }}">Edit</a></p>
编辑页面的链接是把图书的isbn键的值添加到字符串/edit/后面组成的。这个链接将会带你进入这本图书的编辑表单。你可以从图4-3中看到结果。
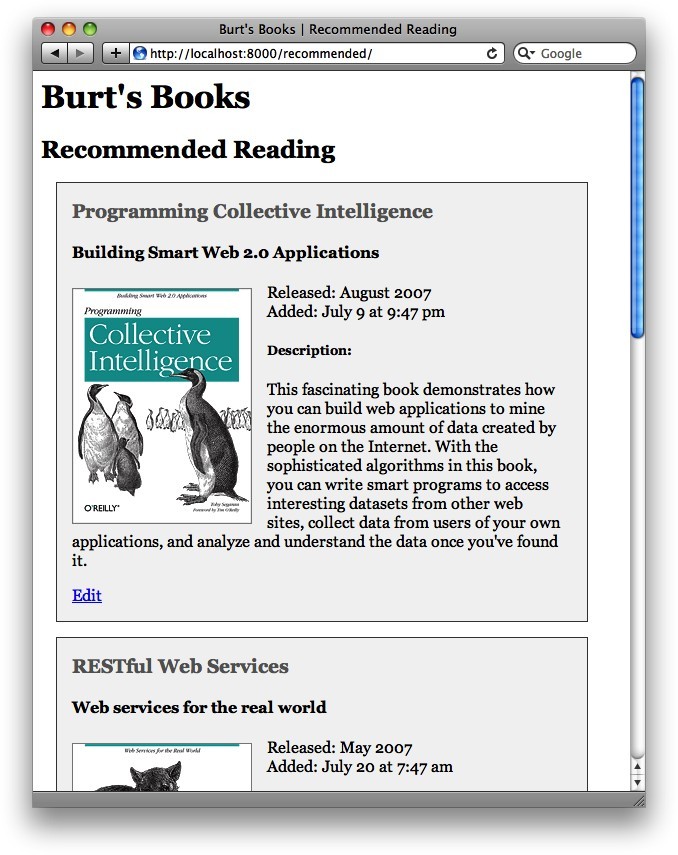
图4-3 Burt's Books:带有编辑链接的推荐列表
4.4 MongoDB:下一步
我们在这里只覆盖了MongoDB的一些基础知识--仅仅够实现本章中的示例Web应用。如果你对于学习更多更用的PyMongo和MongoDB知识感兴趣的话,PyMongo教程(http://api.mongodb.org/python/2.0.1/tutorial.html)和MongoDB教程(http://www.mongodb.org/display/DOCS/Tutorial)是不错的起点。
如果你对使用Tornado创建在扩展性方面表现更好的MongoDB应用感兴趣的话,你可以自学asyncmongo(https://github.com/bitly/asyncmongo),这是一种异步执行MongoDB请求的类似PyMongo的库。我们将在第5章中讨论什么是异步请求,以及为什么它在Web应用中扩展性更好。