一、Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop框架最核心的设计包含两个方面,一是分布式文件系统(Hadoop Distributed File System),简称HDFS;二是分布式计算框架MapReduce。简单来说,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
Hadoop这个名字并不是一个缩写,是其创始人Doug Cutting的孩子给一头大象取的名字,这个名字本身并不具有描述性。
二、HDFS架构
一个分布式存储系统。
1、特点
(1)主从模式,一个主结点,多个从结点(默认三个)
(2)Block(块)为最小的存储单位,默认为64MB。一个文件划分为多个分块(chunk)进行存储
(3)一次写入,多次读取的访问模式
2、各结点的作用
(1)namenode,主结点,用来存储元数据信息,管理文件系统的命名空间。
(2)datanode,从结点,存储数据信息;并定期向namenode发送它们所储存块的列表。
(3)Secondary namenode,帮助NameNode合并编辑日志,减少NameNode的启动时间
namenode和datanode不难理解,但是Secondary namenode的作用看到过多种说法,有一种如下:
fsimage是namenode启动时对整个系统的快照
edit log是namenode启动后,对文件系统的改动序列,只有在namenode再次启动时,这些edit log才会合并到fsimage中
所以,如果edit log过于长,namenode启动就会非常慢
secondary namenode会定时去namenode取edit log,并更新到自己的fsimage上,之后复制到namenode中,namenode启动时直接用这个快照。
另一方面,因为secondary namenode的工作内容,当namenode出现故障时,也可以起到一定的作用
3、工作流程
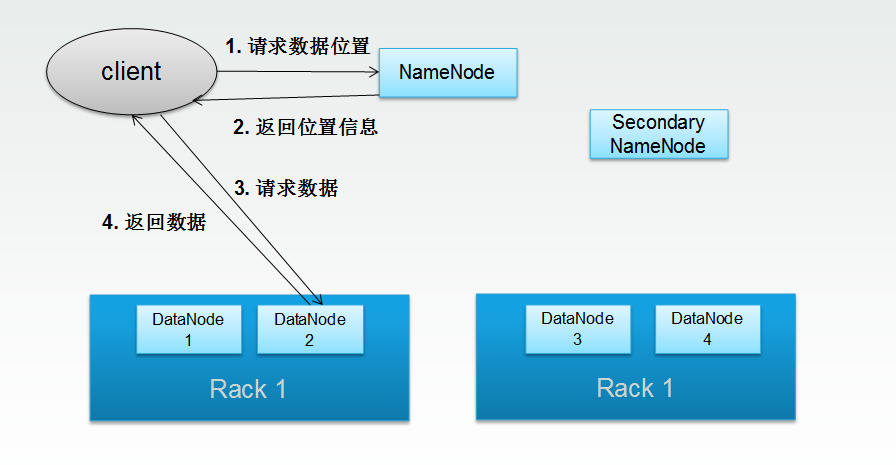
简单理解的话,对于读数据来说,如上图所示:
1)客户端发送请求,从主结点返回数据存储的位置信息;
2)客户端根据具体的位置信息从datanode获取数据。
但是,真实过程要复杂的多
(1)客户端读取HDFS中的数据
1)客户端对DistributedFileSystem对象(分布式文件系统)调用open()方法打开文件系统
2)DistributedFileSystem对namenode创建一个RPC调用,请求文件地址
namenode返回文件各block所在的datanode地址(返回所有副本的地址,但是会按距离排序)
DistributedFileSystem返回一个FSDataInputStream对象(文件定位输入流)给客户端
FSDataInputStream封装了DFSInputStream对象(管理结点的I/O)
3)客户端对上述输入流调用read方法
4)DFSInputStream连接存储着文件起始块的距离最近的datanode,将数据从datanode返回到客户端
传输完毕,DFSInputStream会关闭与datanode的连接
5)对下一个block执行步骤4的操作
6)读取完毕,客户端对FSDataInputStream调用close()方法
(2)客户端将文件写入HDFS
下面的过程,首先创建一个新文件,并把数据写入该文件,最后关闭文件
1)客户端对DistributedFileSytem对象调用create()方法创建文件
2)DistributedFileSystem对namenode创建一个RPC调用,请求在文件系统的命名空间中创建一个新文件
namenode执行各种不同的检查确认这个文件不存在,以及客户端有创建这个文件的权限
如果检查不通过,文件创建失败并向客户端返回一个IOException异常
若通过,namenode增加一条创建新文件的记录,
DistributedFileSystem向客户端返回一个FSDataOutputStream对象
FSDataOutputStream封装了DFSOutputStream对象(管理结点的I/O)
3)客户端写入数据
DFSOutputStream将数据分成一个个的数据块,并写入内部队列,称为“数据队列”
DataStreamer处理数据队列,根据datanode列表要求namenode分配适合的新块来存储数据备份
一组datanode构成一个管线,假设复本为3,则管线中有3个结点
4)DataStreamer将数据块流式传输到管线中的第1个datanode,
该datanode存储数据并将它发送到第二个datanode,第二个到第三个同理
DFSOutputStream同时也维护着一个“确认队列”,等待datanode的确认回执
5)当收到确认回执时,才会删除队列中的数据信息
6)写入完毕,客户端对FSDataOutputStream调用close()方法
7)DistributedFileSystem向namenode发送文件写入完成信号
4、优点:
(1)容错性:数据多复本存储,如果datanode结点发生故障,会自动备份数据
(2)最短路径读取:namenode可以出最佳的路径,返回给文件流进行数据读取
(3)可扩展性:如果新增机器,namenode会自动开始存储数据到该机器。
4、缺陷
(1)单点故障问题:若namenode结点出现故障,整个HDFS将会失效
(2)安全问题:Client可以绕过NameNode直接对DataNode进行读写操作
三、MapReduce
一个基于分布式存储系统的分布式计算框架。
1、MapReduce程序执行步骤
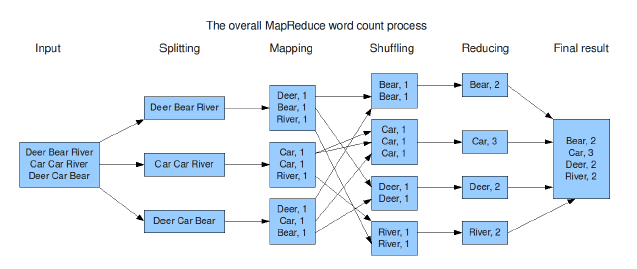
(1)输入
(2)split过程:切分输入数据
(3)map过程(映射):将数据解析成key/value对
(4)shuffle&sort过程(分组排序):根据key值对键值对进行分组,将具有相同key的数据分成一组,每一组发给一个reduce处理
(5)Reduce过程(规约):对数据进行规约处理
(6)输出
2、MapReduce任务的执行流程
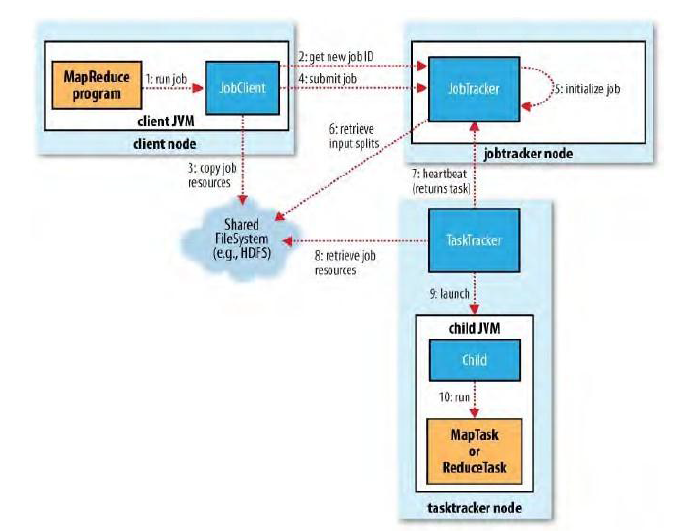
(1)用户启动程序:用户通过Hadoop命令启动运行MapReduce程序
(2)JobClient获取作业ID:JobClient联系JobTracker获取一个作业ID
(3)JobClient初始化准备:
① 将代码、配置、切片信息等复制到HDFS
② 根据输入数据路径、Block大小以及设定的分片大小对数据进行切割划分
③ 对输出目录进行检查
(4)JobClient提交作业:JobClient将作业ID和对应的资源信息提交各JobTracker
(5)JobTracer初始化作业:JobTracker将用户提交的信息封装到对象用于进行跟踪,同时将作业加入到作业调度器
(6)JobTracker获取分片信息:JobTracker获取每个分片的位置、边界等信息
(7)TaskerTracker获取任务:TaskTracker通过心跳机制从JobTracker获取任务信息(任务ID、数据位置)
(8)TaskerTracker获取数据:TaskerTracker从HDFS中读取数据,并复制到自己的机器上
(9)TaskerTracker运行任务:TaskerTracker启动子JVM运行任务
(10)具体的Map或Reduce执行:在子JVM中,Map或者Reduce任务进行执行。
执行完后,通知TaskTracker,TaskTracker再通知给JobTracker,再通知给客户端
备注:
(1)Job:作业,通常整个要处理的工作内容称为作业,一个Job包含多个Task
(2)Task:任务,一个作业划分为多个任务进行处理
(3)心跳机制:TaskTracker会以一定的频率向JobTracker进行信息反馈,报告当前所处的状态等等。
四、后续内容
1、Hadoop伪分布式环境搭建
2、MapReduce简单应用程序(Java/Python)和相关Hadoop命令
3、Hadoop生态圈简单介绍