scrapy是python的一个网络爬虫框架,关于它的介绍有很多资料,这里不做过多介绍(好吧我承认我还不是很懂...)。我现在还在摸索阶段,因为用scrapy爬取的第一个网站非常简单,不涉及登陆、验证、翻页、封号等等问题,仅仅是用spiders中抓取页面内容,然后在pipelines中存入数据库,所以现阶段了解的东西还不多,在此仅将自己这段时间的学习成果进行总结分享。
一、scrapy框架安装
(一)需要安装东西
1、python安装:我用的版本是2,7,8
2、pywin32安装——我不明白在Scrapy中它是干嘛使的/(ㄒoㄒ)/~~
3、twisted安装
Twisted是用Python实现的基于事件驱动的网络引擎框架,Scrapy使用了Twisted异步网络库来处理网络通讯。
(1)安装zope.interface
(2)安装pyopenssl
(3)安装twisted
4、安装lxml
5、安装scrapy
(二)windows系统下的安装
1、其他包安装
在windows系统下,除了scrapy本身,其余的包都可以找到exe文件,运行傻瓜安装即可,有一点需要注意,如果电脑本身安装了多个版本的python,在安装的时候选择指定python的路径。
2、scrapy安装
(1)下载源码——进入源码——python setup.py install
(2)安装pip(python的一个包安装工具)—— pip install Scrapy
3、附我的安装包网盘下载地址:http://pan.baidu.com/s/1dExYh2p
(三)linux系统下的安装——Centos
1、安装方法和命令
1)系统软件安装
(1)yum——Centos下的软件包管理器——yum install python2.7
安装系统需要的软件包时,需要用到这个命令,但是有一点,yum会自动安装最新版。
(2)wget——获取软件包,之后可以进行解压,然后手动安装(此种方式也可以用于python库的安装)
wget -c http://www.python.org/ftp/python/2.6.5/Python-2.6.5.tar.bz2
2)python库安装
(1)下载安装脚本.py文件(wget方法)——python **.py
(2)下载源码,进入根目录——python setup.py install
(3)easy_install——easy_install Scrapy
(4)pip——用于安装python的相关包——pip install Scrapy
2、安装步骤
1)python安装——python2.7.6
(1)获取安装包:wget http://python.org/ftp/python/2.7.6/Python-2.7.6.tar.xz
(2)解压:xz Python-2.7.6.tar.xz
tar xvf Python-2.7.6.tar
(3)进入源码:cd Python-2.7.6
(4)安装:
配置:./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
安装: make && make altinstall
(5)建立软连接,将系统默认的python指向python2.7:
删除原来的软连接:rm -rf /usr/bin/python
建立新的软连接:ln -s /usr/local/bin/python2.7 /usr/bin/python
现在在命令行输入python,就是默认的2.7版本了
2)esay_install——方便之后的python库安装
(1)方法1:yum install setuptool
我最初用的是这种方法,但是正如前面所述,此种方法默认安装的最新版本(3.*),它将库安装在了python3中。
(2)方法2:wget
wget --no-check-certificate https://bootstrap.pypa.io/ez_setup.py
python ez_setup.py --insecure(因为此时python的默认的是2.7,所以会安装在2.7下)
之后可以按照python的方式建立easy_install的软连接,因为此时系统中可能装有不同版本的setuptools,指定自己需要的版本。
(3)pip安装——可以利用easy_install 安装一下pip——easy_install pip
注意:pip/easy_install——对应python2
pip3/easy_install3——对应python3
3)安装twisted
(1)安装zope.interface——easy_install zope.interface
(2)安装gcc:yum install gcc -y
(3)安装twisted:easy_install twisted
4)安装pyOpenSSL
(1)依赖:yum install libffi libffi-devel openssl-devel -y
(2)easy_install pyOpenSSL
5)安装Scrapy
(1)依赖:yum install libxml2 libxslt libxslt-devel -y
(2)easy_install scrapy
问题:在最后一步easy_install scrapy时,报了一个错误
Setup script exited with error: command 'gcc' failed with exit status 1????
我怀疑是python-devel的版本问题,可是找了n多资料,也还没有解决/(ㄒoㄒ)/~~
二、Scrapy应用(windows下)
一)新建一个Scrapy项目
进入指定目录,按住Shift键,点击鼠标右键,选择在此处打开命令行:
输入命令:scrapy startproject scrapyLearning--------新建一个项目
tree -/f scrapyLearing 可以查看一下目录结构
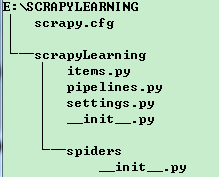
(1)spdiders文件夹下的py文件:爬取数据——爬到网页;获取数据
(2)items.py:类似于MVC或者Django框架中的model
(3)pipelines.py:存储数据,spider.py执行完会自动调用pipilines.py,将爬取到的数据存储下来
(4)settings.py:一些配置信息,目前我只是加过pipeline,其他还没有操纵过
二)案例-爬取一个网站的数据,存入到MySql中,代码的部分截图如下(部分名字马赛克了一下...):
1、整个代码结构
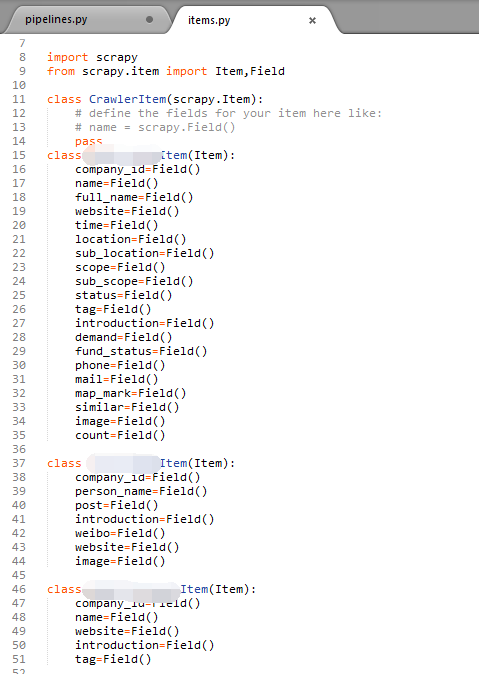
2、item——定义了多了Item,每一个对应一个数据库表
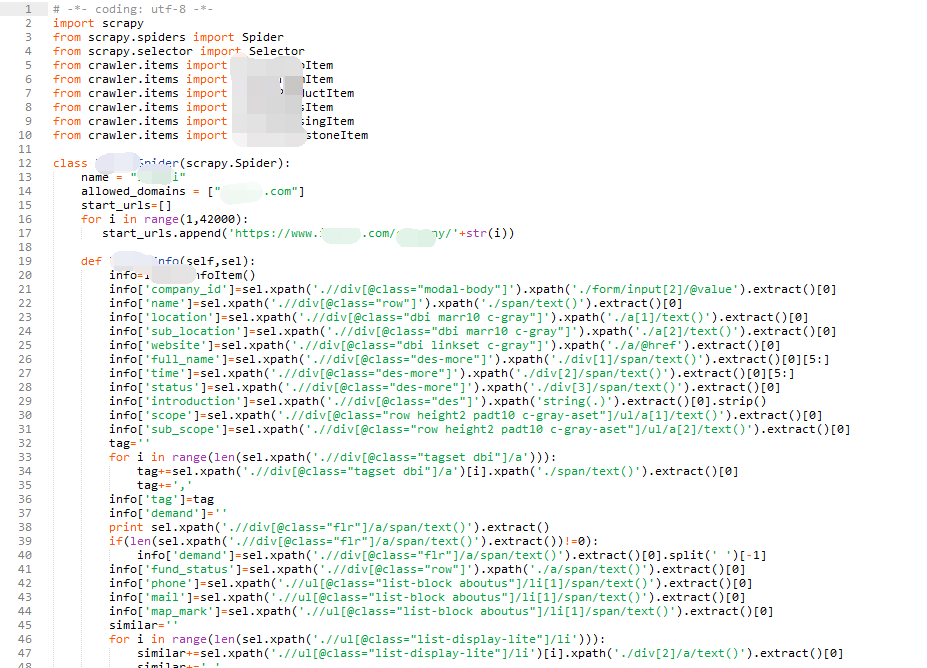
3、spider
运行命令:scrapy genspider spaiderName “***.com”--------- 新建一个爬虫(后两个参数是爬虫的名字和域名)
(1)把定义的那些item都引入进来
(2)start_urls——要爬取的url,因为此网站要爬取的各个url是连续的,所以就用一个循环即可,程序会依次处理每一个url
(3)xpath方法提取页面中的元素
(4)return info,把提取到的数据返回——之后会调用pipeline对数据进行存储
4、pipelines
(1)因为有不同的类型的item,所以首先判断是哪个类型,然后再分别调用不同的处理方法
(2)之后对数据库进行操作

5、settings
指定一下需要用到的pipeline——ITEM_PIPELINES = ['crawler.pipelines.CrawlerPipeline']
以上,就是一个完整的运用scrapy框架进行网络爬取的过程,非常简单,难点在于分析页面结构和对于异常情况的处理。当然,本例子爬取的网站比较简单,像Rules等都还没有用到,日后用到会进一步总结更新。
6、运行爬虫
通过命令: scrapy crawl spiderName