数据类型:整数、浮点数、字符串、布尔类型、列表、元组、字典、空值等。
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等,是一个有序的、不可变的字符的集合。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符来标识,如

表示的字符串是:

一、这里说一下转义字符:
表示换行, 表示制表符(按一下Tab键或者是按八下空格键),字符本身也要转义,所以\表示的字符就是
特殊情况1:如果字符串里面有很多字符都需要转义,就需要加很多,为了简化,Python还允许用r''表示''内部的字符串默认不转义

特殊情况2:如果字符串内部有很多换行,用
写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容
2.1 如果在交互式命令行内输入,注意在输入多行内容时,提示符由>>>变为...,提示你可以接着上一行输入,注意...是提示符,不是代码的一部分;

2.2 如果写成程序并存为.py文件,就如下图

二、字符串常用的函数:

布尔值(布尔类型)
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来;
布尔值可以用and、or和not运算。
列表
list是一种有序可变的集合,可以随时添加和删除其中的元素。常见操作:创建、增删改查、切片、循环、排序、扩展等。
创建:names = ['emily','zinp',1,5,8,1]
查找(索引):names[1]、names[-1]
查找全部元素个数:len(names)
查找某元素个数:names.count(1)
查找某元素索引值:names.index(5)、names.index(1)———如有重复元素,默认输出第一个元素的索引值
增加:names.append('Alex') ---往list中追加元素到末尾
names.insert(1,'hongbin') ---往list元素中间穿插元素
删除:names.pop() ---删除list末尾的元素
names.pop(i) ---通过索引删除list指定位置的元素
names.remove('zinp')---直接删除list中某元素
del names[2] ---del是全局性的删除,也可以删除整个列表或其他变量
修改:要把某个元素替换成别的元素,可以直接赋值给对应的索引位置
切片:顾头不顾尾


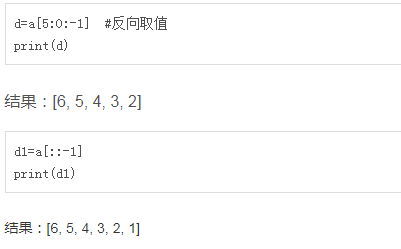
循环: for i in names:
print(i)
排序:names.sort()
print(names) --------按照ASCII码进行排序
扩展:直接将列表相加:n1 + n2
用函数extend:n1.extend(n2)
元组
元组跟列表差不多,也是存一组数,只不过元组一旦创建就不可修改,也称只读列表。
创建:names = ('Alex',1,2,[3,4,'Zinp’])
功能:index
count
切片
字典
字典是一种Key-value的数据类型,使用就像上学时用到的字典,通过笔画、字母来查对应页的详细内容。
特性:1、Key-value
2、Key必须可hash,且必须为不可变数据类型、必须唯一
3、可存放任意多个值,可修改,可以不唯一
4、无序
5、查找速度快
举个例子,假设要根据同学的名字查找对应的成绩,如果用list实现,需要两个list:
names = ['Michael', 'Bob', 'Tracy']
scores = [95, 75, 85]
给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长。
如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下:
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
dict就是第二种实现方式,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
把数据放入dict的方法,除了初始化时指定外,还可以通过key放入:
>>> d['Adam'] = 67
>>> d['Adam']
67
由于一个key只能对应一个value,所以,多次对一个key放入value,后面的值会把前面的值冲掉:
>>> d['Jack'] = 90
>>> d['Jack']
90
>>> d['Jack'] = 88
>>> d['Jack']
88
如果key不存在,dict就会报错:
>>> d['Thomas']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Thomas'
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False
二是通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
注意:返回None的时候Python的交互环境不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。