在这篇文章中,我们将讨论mask R-CNN背后的一些理论,以及如何在PyTorch中使用预训练的mask R-CNN模型。
1.语义分割、目标检测和实例分割
之前已经介绍过:
1、语义分割:在语义分割中,我们分配一个类标签(例如。狗、猫、人、背景等)对图像中的每个像素。
2、目标检测:在目标检测中,我们将类标签分配给包含对象的包围框。
一个非常自然的想法是把两者结合起来。我们只想在一个对象周围识别一个包围框,并且找到包围框中的哪些像素属于对象。 换句话说,我们想要一个掩码,它指示(使用颜色或灰度值)哪些像素属于同一对象。 产生上述掩码的一类算法称为实例分割算法。mask R-CNN就是这样一种算法。
实例分割和语义分割有两种不同
1、在语义分割中,每个像素都被分配一个类标签,而在实例分割中则不是这样。
2、在语义分割中,我们不区分同一类的实例。例如,语义分割中属于“Person”类的所有像素都将在掩码中分配相同的颜色/值。在实例分割中,它们被分配到不同的值,我们能够告诉它们哪个像素对应于哪个人。 要了解更多关于图像分割的信息,请查看我们已经详细解释过的帖子。
Mask R-CNN结构
mask R-CNN的网络结构是我们以前讨论过的FasterR-CNN的扩展。
回想一下,faster R-CNN架构有以下组件
卷积层:输入图像经过几个卷积层来创建特征图。如果你是初学者,把卷积层看作一个黑匣子,它接收一个3通道的输入图像,并输出一个空间维数小得多(7×7),但通道非常多(512)的“图像”。
区域提案网络(RPN)。卷积层的输出用于训练一个网络,该网络提取包围对象的区域。
分类器:同样的特征图也被用来训练一个分类器,该分类器将标签分配给框内的对象。
此外,回想一下,FasterR-CNN 比 Fast R-CNN更快,因为特征图被计算一次,并被RPN和分类器重用。 mask R-CNN将这个想法向前推进了一步。除了向RPN和分类器提供特征图外,mask R-CNN还使用它来预测边界框内对象的二值掩码。 研究 MaskR-CNN的掩码预测部分的一种方法是,它是一个用于语义分割的完全卷积网络(FCN)。唯一的区别是在mask R-CNN里,FCN被应用于边界框,而且它与RPN和分类器共享卷积层。 下图显示了一个非常高层次的架构。
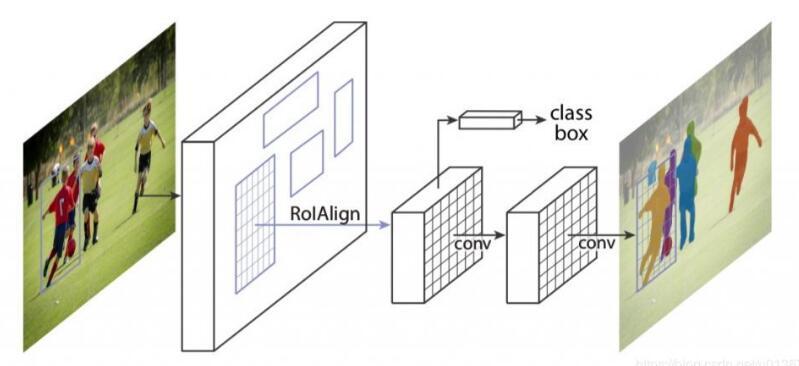
2.在PyTorch中使用mask R-CNN[代码]
在本节中,我们将学习如何在PyTorch中使用预先训练的MaskR-CNN模型。
2.1.输入和输出
mask R-CNN模型期望的输入是张量列表,每个张量的类型为(n,c,h,w),元素在0-1范围内。图像的大小随意。
n是图像的个数
c为通道数 RGB图像为3
h是图像的高度
w是图像的宽度
模型返回 :
包围框的坐标
模型预测的存在于输入图像中的类的标签以及对应标签的分数
标签中每个类的掩码。
2.2 预训练模型
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True) model.eval()
2.3 模型的预测
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
def get_prediction(img_path, threshold):
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
print('pred')
print(pred)
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x>threshold][-1]
print("masks>0.5")
print(pred[0]['masks']>0.5)
masks = (pred[0]['masks']>0.5).squeeze().detach().cpu().numpy()
print("this is masks")
print(masks)
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())]
masks = masks[:pred_t+1]
pred_boxes = pred_boxes[:pred_t+1]
pred_class = pred_class[:pred_t+1]
return masks, pred_boxes, pred_class
代码功能如下:
从图像路径中获取图像
使用PyTorch变换将图像转换为图像张量
通过模型传递图像以得到预测结果
从模型中获得掩码、预测类和包围框坐标
每个预测对象的掩码从一组11个预定义的颜色中随机给出颜色,以便在输入图像上将掩码可视化。
def random_colour_masks(image):
colours = [[0, 255, 0],[0, 0, 255],[255, 0, 0],[0, 255, 255],[255, 255, 0],[255, 0, 255],[80, 70, 180],[250, 80, 190],[245, 145, 50],[70, 150, 250],[50, 190, 190]]
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
r[image == 1], g[image == 1], b[image == 1] = colours[random.randrange(0,10)]
coloured_mask = np.stack([r, g, b], axis=2)
return coloured_mask
代码中有一些打印信息帮助分析处理过程
2.4 实例分割工作流程
def instance_segmentation_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
masks, boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for i in range(len(masks)):
rgb_mask = random_colour_masks(masks[i])
img = cv2.addWeighted(img, 1, rgb_mask, 0.5, 0)
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)
plt.figure(figsize=(20,30))
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
掩码、预测类和边界框是通过get_prediction获得的
每个掩码从11种颜色中随机给出颜色。 每个掩码按比例1:0.5被添加到图像中,使用了opencv。
包围框是用cv2.rectangle绘制的,上面有类名。
显示最终输出
完整代码如下:
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import torch
import numpy as np
import cv2
import random
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
def get_prediction(img_path, threshold):
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
print('pred')
print(pred)
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x>threshold][-1]
print("masks>0.5")
print(pred[0]['masks']>0.5)
masks = (pred[0]['masks']>0.5).squeeze().detach().cpu().numpy()
print("this is masks")
print(masks)
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())]
masks = masks[:pred_t+1]
pred_boxes = pred_boxes[:pred_t+1]
pred_class = pred_class[:pred_t+1]
return masks, pred_boxes, pred_class
def random_colour_masks(image):
colours = [[0, 255, 0],[0, 0, 255],[255, 0, 0],[0, 255, 255],[255, 255, 0],[255, 0, 255],[80, 70, 180],[250, 80, 190],[245, 145, 50],[70, 150, 250],[50, 190, 190]]
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
r[image == 1], g[image == 1], b[image == 1] = colours[random.randrange(0,10)]
coloured_mask = np.stack([r, g, b], axis=2)
return coloured_mask
def instance_segmentation_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
masks, boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for i in range(len(masks)):
rgb_mask = random_colour_masks(masks[i])
img = cv2.addWeighted(img, 1, rgb_mask, 0.5, 0)
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)
plt.figure(figsize=(20,30))
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
2.5 示例
示例1:以小鸡为例,会识别为鸟类
instance_segmentation_api('chicken.jpg')
输入图像:

输出结果:

处理过程中的打印信息:
pred
[{'boxes': tensor([[176.8106, 125.6315, 326.8023, 400.4467],
[427.9514, 130.5811, 584.2725, 403.1004],
[289.9471, 169.1313, 448.9896, 410.0000],
[208.7829, 140.7450, 421.3497, 409.0258],
[417.7833, 137.5480, 603.2806, 405.6804],
[174.3626, 132.7247, 330.4560, 404.6956],
[291.6709, 165.4233, 447.1820, 401.7686],
[171.9978, 114.4133, 336.9987, 410.0000],
[427.0312, 129.5812, 584.2130, 405.4166]], grad_fn=<StackBackward>), 'labels': tensor([16, 16, 16, 16, 20, 20, 20, 18, 18]), 'scores': tensor([0.9912, 0.9910, 0.9894, 0.2994, 0.2108, 0.1995, 0.1795, 0.1655, 0.0516],
grad_fn=<IndexBackward>), 'masks': tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
...,
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]], grad_fn=<UnsqueezeBackward0>)}]
masks>0.5
tensor([[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
...,
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]]])
this is masks
[[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
...
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]]
masks = (pred[0]['masks']>0.5).squeeze().detach().cpu().numpy()使masks变为[n x h x w],且元素为bool值,为后续指定随机颜色做了准备,r[image == 1], g[image == 1], b[image == 1] = colours[random.randrange(0,10)],将掩码列表中属于实际对象的区域变成随机彩色,其余部分仍为0.这些代码充分展示了python中高级切片的魔力,当然用到的是numpy和torch.tensor里的功能。
示例2:棕熊
instance_segmentation_api('bear.jpg', threshold=0.8)
输入图像:

输出图像:

打印信息:
pred
[{'boxes': tensor([[ 660.3120, 340.5351, 1235.1614, 846.9672],
[ 171.7622, 426.9127, 756.6520, 784.9360],
[ 317.9777, 184.6863, 648.0856, 473.6469],
[ 283.0787, 200.8575, 703.7324, 664.4083],
[ 354.9362, 308.0444, 919.0403, 812.0120]], grad_fn=<StackBackward>), 'labels': tensor([23, 23, 23, 23, 23]), 'scores': tensor([0.9994, 0.9994, 0.9981, 0.5138, 0.0819], grad_fn=<IndexBackward>), 'masks': tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]], grad_fn=<UnsqueezeBackward0>)}]
masks>0.5
tensor([[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]],
[[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]]])
this is masks
[[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]]
3、GPU与CPU时间对比
def check_inference_time(image_path, gpu=False):
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
img = Image.open(image_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
if gpu:
model.cuda()
img = img.cuda()
else:
model.cpu()
img = img.cpu()
start_time = time.time()
pred = model([img])
end_time = time.time()
return end_time-start_time
cpu_time = sum([check_inference_time('./people.jpg', gpu=False) for _ in range(5)])/5.0
gpu_time = sum([check_inference_time('./people.jpg', gpu=True) for _ in range(5)])/5.0
print('\n\nAverage Time take by the model with GPU = {}s\nAverage Time take by the model with CPU = {}s'.format(gpu_time, cpu_time))
结果:
Average Time take by the model with GPU = 0.5736178874969482s, Average Time take by the model with CPU = 10.966966199874879s
以上这篇在Pytorch中使用Mask R-CNN进行实例分割操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。