1、什么是Fiddler?
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件)。
Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。同类的工具有: httpwatch, firebug, wireshark。
Fiddler使用,参考:https://www.cnblogs.com/miantest/p/7289694.html
Fiddler下载:https://www.telerik.com/fiddler
傻瓜式安装,一键到底。
2、手机APP抓包设置
2.1 、Fiddler设置
打开Fiddler软件,打开工具的设置。(Fiddler软件菜单栏:Tools->Options)
在HTTPS中设置如下:
在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突:
载后在手机里打开,命名。安装
局域网设置
使用Fiddler进行手机抓包,首先要确保手机和电脑的网络在一个内网中,可以使用让电脑和手机都连接同一个路由器。当然,也可以让电脑开放WIFI热点,手机连入。
这里,我使用的方法是,让手机和电脑同时连入一个路由器中。最后,让手机使用电脑的代理IP进行上网。
首先,查看电脑的IP地址,在cmd中使用命令ipconfig查看电脑IP地址。找到无线局域网WLAN的IPv4地址,记下此地址。
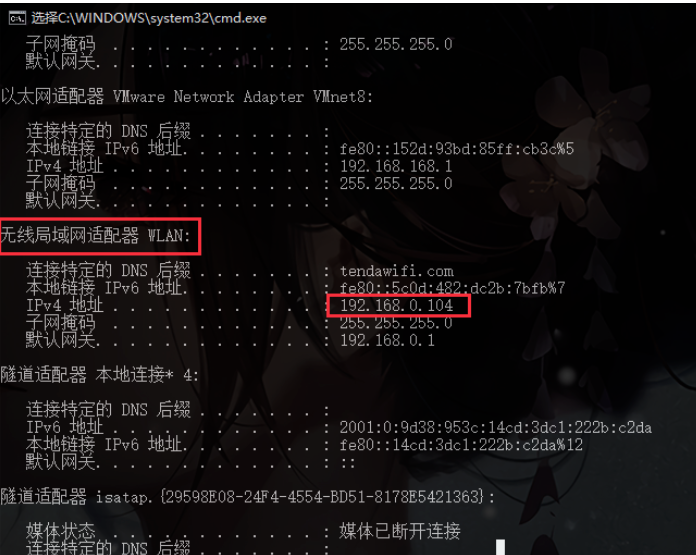
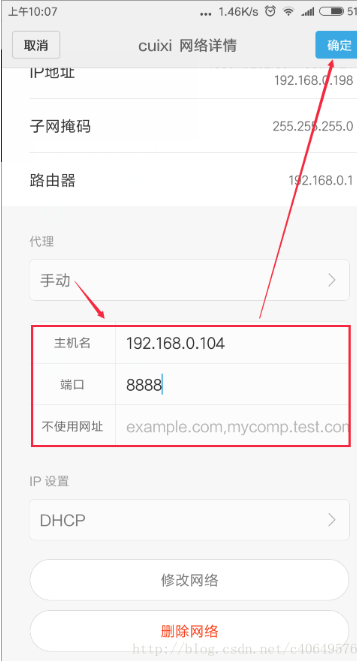
在手机上,点击连接的WIFI进行网络修改,添加代理。进行手动设置,主机名即为上图中找到的IP地址,端口号即为Fiddler设置中的端口号8888:
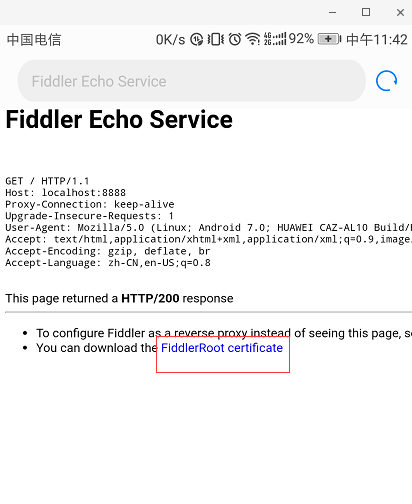
2.2 、安全证书下载
在手机浏览器中输入地址:http://localhost:8888/,点击FiddlerRoot certificate,下载安全证书:
2.3、 安全证书安装
以华为手机为例:
在手机设置--->高级设置-->安全---->显示受信任的CA证书--->用户
安装成功后,显示如下:
3、Fiddler手机抓包测试
上述步骤都设置完成之后,用手机打开今日头条app,截图如下:
我们再来看fidder抓取的数据情况:
可以复制url和head内容
GET http://cards.iqiyi.com/views_search/3.0/search?card_v=3.0&scrn_res=1080,1788&keyword=%E5%8E%A6%E9%97%A8%E8%A7%86%E9%A2%91%E5%A4%B4%E6%9D%A1&source=suggest&qr=0&mode=1&duration_level=0&publish_date=0&bitrate=0&need_qc=0&s_sr=1&from_rpage=qy_home&origin=0&psp_vip=0&s_token=main%23%E5%8E%A6%E9%97%A8%E8%A7%86%E9%A2%91&app_k=3179f25bc69e815ad828327ccf10c539&app_v=10.3.5&platform_id=10&dev_os=7.0&dev_ua=HUAWEI+CAZ-AL10&net_sts=1&qyid=864590038380239&cupid_v=3.35.002&psp_uid=1732414636&psp_cki=03RdTbm2uf4Km2X6Mvs1lAVDAg4l6om2Uf0HWm32122YH5VCFgxKvr4m2UFiOwCwBuvlcCu9c&imei=c0497fcececef4b5a2a4f4156d6fd726&aid=47628a3804ad50be&mac=14:5F:94:B3:E0:AD&scrn_scale=3&secure_p=GPhone&secure_v=1&core=1&api_v=8.8&profile=%7B%22group%22%3A%221%2C2%22%2C%22counter%22%3A2%7D&province_id=2007&service_filter=&service_sort=&layout_v=44.115&device_type=0&cupid_uid=864590038380239&psp_status=1&app_gv=&gps=116.373202,39.962811&bdgps=116.385157,39.970314&lang=zh_CN&app_lm=cn&req_times=0&req_sn=1556011726525 HTTP/1.1 qyid: 864590038380239_47628a3804ad50be_14Z5FZ94ZB3ZE0ZAD Connection: Keep-Alive t: 512025323 sign: 04876862c652470b54dd1add698631d5
4、python代码测试
有了上面这些信息就可以写代码了
# -*- coding: UTF-8 -*-
import requests
from urllib import request
import time
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from pyquery import PyQuery as pq
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
import json
class app_data:
def __init__(self):
self.headers = {'Accept-Charset': 'UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'lf-hl.snssdk.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'X-SS-REQ-TICKET': '1544235590880',
'sdk-version': '1',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 7.0; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10) NewsArticle/7.0.1 cronet/TTNetVersion:pre_blink_merge-277498-gd2bb364e 2018-08-24',
'X-SS-TC': '0'
}
self.headers2 = {
'Accept': '*/*',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 7.0; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/56.0.2924.87 Mobile Safari/537.36 JsSdk/2 NewsArticle/7.0.1 NetType/wifi',
'X-Requested-With': 'com.ss.android.article.news'
}
def catch_app_data(self,link):
if not link:
link=self.heros_url1
req = requests.get(url=link, headers=self.headers,verify=False).json()
data = req.get("data")
name = data.get("name")
print('账号:', name)
verified_content = data.get("verified_content")
print('认证:', verified_content)
area = data.get("area")
print('位置:', area)
description = data.get("description")
print('简介:', description)
user_id = data.get("user_id")
print('user_id:', user_id)
def cat_app_list(self,keyword='中餐厅'):
url = 'https://lf-hl.snssdk.com/api/search/content/?from=search_tab'
'&keyword='+keyword+''
'&cur_tab_title=search_tab'
'&plugin_enable=3'
'&iid=53115531269'
'&device_id=52727404130'
'&ac=wifi'
'&channel=huawei&aid=13'
'&app_name=news_article'
'&version_code=701'
'&version_name=7.0.1'
'&device_platform=android'
'&ab_group=94567'
'%252C102749%252C181430'
'&abflag=3'
'&device_type=HUAWEI%2BCAZ-AL10'
'&device_brand=HUAWEI'
'&language=zh'
'&os_api=24'
'&os_version=7.0'
'&uuid=864590038380239'
'&openudid=47628a3804ad50be'
'&manifest_version_code=701'
'&resolution=1080*1788'
'&dpi=480'
'&update_version_code=70108'
'&_rticket=1544497762334'
'&fp=DrT_L2w1cST5FlT_F2U1FYK7FrxO'
'&tma_jssdk_version=1.5.4.2'
'&rom_version=emotionui_5.0.4_caz-al10c00b386'
'&plugin=26958&search_sug=1'
'&forum=1&count=10'
'&format=json'
'&source=input'
'&pd=synthesis'
'&keyword_type='
'&action_type=input_keyword_search'
'&search_position=search_tab'
'&from_search_subtab='
'&offset=0'
'&search_id='
'&has_count=0&qc_query='
head = {
'Accept': '*/*',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 7.0; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/56.0.2924.87 Mobile Safari/537.36 JsSdk/2 NewsArticle/7.0.1 NetType/wifi',
'X-Requested-With': 'com.ss.android.article.news'
}
req = requests.get(url=url, headers=head,verify=False).json()
data = req.get("data")
url_list = []
for item in data:
display_list = item.get('display')
if display_list:
album_group_dict = display_list.get('album_group')
if album_group_dict:
extra = str(album_group_dict.get('extra'))
item_list = extra.split(',')
for e in item_list:
if e.find("album_group_url") > -1:
url = e[e.find(":") + 1:]
url = url.replace(""", "")
url_list.append(url)
break
else:
url = display_list.get('url')
if url:
url_list.append(url)
print(url_list)
def catchdata_sogo(self,url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
# self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
# self.driver.set_page_load_timeout(20)
# self.driver.maximize_window()
try:
self.driver.get(url)
print(url)
# handles = self.driver.window_handles # 获取当前窗口句柄集合(列表类型)
# self.driver.switch_to.window(handles[2 - 1])
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
elements = doc("div[class='content-txt']").find("p")
for element in elements.items():
print(element.text())
elements = doc("p[class='mod-base-item']").find("span")
for element in elements.items():
print(element.text())
except Exception as ex:
print(ex)
def catchdata_so(self, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
# self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
# self.driver.set_page_load_timeout(20)
# self.driver.maximize_window()
try:
self.driver.get(url)
print(url)
# handles = self.driver.window_handles # 获取当前窗口句柄集合(列表类型)
# self.driver.switch_to.window(handles[2 - 1])
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
elements = doc("div[class='cp-info-main']")
for element in elements.items():
print(element('h3').text())
# print(element("p[class='js-info-upinfo']").text())
print(element('p').text())
except Exception as ex:
print(ex)
def test(self,link):
req = requests.get(url=link, headers=self.headers2, verify=False)
json_str = req.content.decode()
print(json_str)
if __name__ == '__main__':
obj = app_data()
# http://m.video.so.com/android/va/Zs5sb3Ny7JA4DT.html
# https://m.douguo.com/search/trecipe/%E4%B8%AD%E9%A4%90%E5%8E%85/0?f=tt
# https://baike.sogou.com/m/fullLemma?ch=jrtt.search.item&cid=xm.click&lid=167408303
# obj.catch_app_data('')
# 湖南卫视中餐厅
# keywords = ['湖南卫视中餐厅','农广天地','看台','十年','CCTV-4远方的家','CCTV热线12']
# for keyword in keywords:
# obj.cat_app_list(keyword)
# print('
')
obj.cat_app_list('CCTV热线12')
# obj.catchdata_sogo('https://baike.sogou.com/m/fullLemma?ch=jrtt.search.item&cid=xm.click&lid=167408303#lemmaHome')
# obj.catchdata_so('http://m.video.so.com/android/va/Zs5sb3Ny7JA4DT.html')
# obj.catchdata_so('http://m.video.so.com/android/va/YcMpcKVv82YBDz.html')
# obj.parserurl()
# obj.test('http://m.video.so.com/android/va/Zs5sb3Ny7JA4DT.html')
输出结果如下:
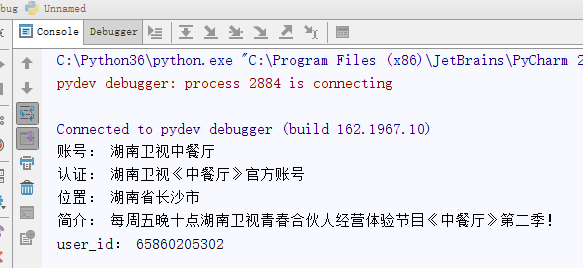
5、总结
需要注意的是,必须先运行Fidder,然后再在手机上进行相关的操作,顺序不能乱,如果在不运行fidder的情况下,操作手机,将无法联网
抓不到https包,fiddler并不是支持全部协议
fiddler并不支持全部协议,目前已知的有http2、tcp、udp、websocket等,如果应用走了以上协议,那么fiddler肯定是抓不到的。
http2:因为fiddler是基于.net framework实现的,因为.net framework不支持http2,所以fiddler无法抓取http2
证书写死在app中,fiddler不能抓取
fiddler抓包的原理是中间人攻击,也就是说,两头瞒,欺骗客户端&&欺骗服务器端,如果https证书写死在app里,也就是说,app不信任fiddler颁发给它的证书,
app只信任自己的证书,fiddler没法瞒客户端了,因此fiddler也就抓取不到包了。
再多说几句,如果是自己开发的app,开发调试方便起见,可以使用类似wireshark的工具导入服务器证书,抓包解密。
