一,使用createBrowserHistory 和 createHashHistory 的 区别体现
1. 使用createBrowserHistory ()
// 使用createBrowserHistory的代码 import React from 'react'; import { Router, Route, Switch} from 'react-router-dom'; import { createHashHistory, createMemoryHistory, createBrowserHistory} from 'history'; import First from './container/First'; import Second from './container/Second'; import Third from './container/Third'; import Fourth from './container/Fourth'; const router = (props) => { return ( <Router history={createBrowserHistory()}> <Switch> <Route exact path={"/"} component={First} /> <Route exact path={"/first"} component={First} /> <Route exact path={"/second"} component={Second} /> <Route exact path={"/third"} component={Third} /> <Route exact path={"/fourth"} component={Fourth} /> </Switch> </Router> ) } export default router;
使用createBrowserHistory(),效果如下:

2. 使用createHashHistory()
//使用createHashHistory const router = (props) => { return ( <Router history={createHashHistory()}> <Switch> <Route exact path={"/"} component={First} /> <Route exact path={"/first"} component={First} /> <Route exact path={"/second"} component={Second} /> <Route exact path={"/third"} component={Third} /> <Route exact path={"/fourth"} component={Fourth} /> </Switch> </Router> ) } export default router;
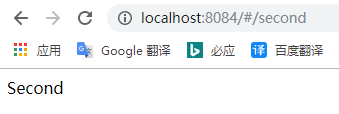
使用createHashHistory(),效果如下:
3. 通过上面的对比, 可以发现
createBrowserHistory() 和 createHashHistory() 的区别体现在 打开页面的路径上:
createBrowserHistory: http://localhost:8084/second
createHashHistory: http://localhost:8084/#/second
还有一个 createMemoryHistory
——现在来看看官方介绍:
- “browser history” - A DOM-specific implementation, useful in web browsers that support the HTML5 history API
- “hash history” - A DOM-specific implementation for legacy web browsers
- “memory history” - An in-memory history implementation, useful in testing and non-DOM environments like React Native
browserHistory: 是使用浏览器中的 History API 来处理 URL(使用 React Router 推荐的 history)
hashHistory: 是使用 URL 中的 hash(#)部分去创建路由
memoryHistory: 未使用,不做介绍
二,browserHistory 和 hashHistory 的优缺点比较
1. 先看看官方推荐的 browserHistory
browserHistory 是使用 React-Router 的应用推荐的 history方案。它使用浏览器中的 History API 用于处理 URL,创建一个像example.com/list/123这样真实的 URL 。
(摘自http://react-guide.github.io/react-router-cn/docs/guides/basics/Histories.html)
因为是使用真实的浏览器history,就像HTML网页间的跳转一样,和浏览器的操作配合完美(浏览器自带的“后退”,“前进”,“刷新” 按钮,浏览器会记录浏览history)
另外:此处需要解释一下单页面应用(SPA)和多页面应用(MPA):
1)多页面模式(MPA Multi-page Application):
多页面跳转需要刷新所有资源,每个公共资源(js、css等)需选择性重新加载
页面跳转:使用window.location.href = "./index.html"进行页面间的跳转;
数据传递:可以使用path?account="123"&password=""路径携带数据传递的方式,或者localstorage、cookie等存储方式2)单页面模式(SPA Single-page Application):
只有一个Web页面的应用,是一种从Web服务器加载的富客户端,单页面跳转仅刷新局部资源 ,公共资源(js、css等)仅需加载一次
页面跳转:使用js中的append/remove或者show/hide的方式来进行页面内容的更换;
数据传递:可通过全局变量或者参数传递,进行相关数据交互
多页面模式,就是多个HTML页面之间的操作,浏览器会通过自身的history处理好页面间的操作,
单页面模式,对于浏览器来说只有一个HTML页面,任何操作都在同一个页面内,浏览器无法监控到页面跳转(实际只是内容改变,路径没变)
在单页面模式下使用browserHistory 的问题是:只有一个真实的html页面,是无法体现出html页面之间跳转的效果的
这时就需要使用服务器配合,模拟出多个HTML页面,从而实现浏览器真实的页面跳转效果
2. 问题展示:
——在webpack 的 本地服务器模式下(webpack-dev-server插件模拟的本地服务器 )
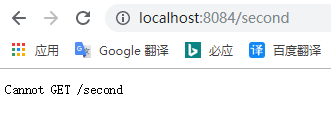
未开启historyApiFallback:
// 本地服务器 webpack-dev-server插件,开发中server,便于开发,可以热加载 devServer: { contentBase: './dist', //默认本地服务器所在的根目录 //historyApiFallback: true, inline: true, //源文件改变时刷新页面 port: 8084 //端口号,默认8080 },
开启historyApiFallback:
// 本地服务器 webpack-dev-server插件,开发中server,便于开发,可以热加载 devServer: { contentBase: './dist', //默认本地服务器所在的根目录 historyApiFallback: true, //开启 inline: true, //源文件改变时刷新页面 port: 8084 //端口号,默认8080 },
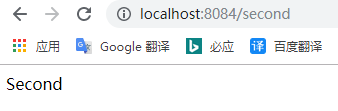
由此可见webpack-dev-server 中 设置 historyApiFallback 可以解决browserHistory 的问题
historyApiFallback 功能:
当使用 HTML5 History API 时,任意的
404响应都可能需要被替代为index.html
三,那么,非开发模式(打出来的包)怎么办??
方法一: 使用服务器进行相关配置,配合browserHistory进行使用
可以参考这篇文章: https://www.thinktxt.com/react/2017/02/26/react-router-browserHistory-refresh-404-solution.html
其实,就是通过服务器(无论Nginx,还是Node都可以)在浏览器方法该目录下(比如dist文件夹)的文件时,都返回 index.html,
比如访问 example.com/list/123 路径,
- 但是服务器下没有这个文件可供访问,
- 所以就需要通过设置服务器,当浏览器访问不存在的页面时,都给索引到 index.html
- 在index.html 我们的browserHistory 才能派上用场
方法二: 使用HashRouter,虽然路径 http://localhost:8084/#/second 多个‘#’,虽然项目内跳转页面可能会有问题。。。
如果有服务器端的动态支持,建议使用 BrowserRouter,否则建议使用 HashRouter。