MySQL
0. SQL语言的分类
- 数据库查询语言DQL:select、where、order by、group by、having
- 数据库定义语言DDL:create、alter、drop
- 数据库操作语言DML:update、delete、insert
- 事务处理语言TPC:commit、rollback
- 数据控制语言DCL:grant、revoke
1.SQL语言
通常对数据库的增删改查,简称为C(create)R(read)U(update)D(delete)。
2.基本命令
#创键自定义数据库
CREATE DATABASE 数据库名;
CREATE DATABASE 数据库名 CHARACTER SET 编码格式;
CREATE DATABASE IF NOT EXISTS 数据库名;
# 查看数据库创键信息
SHOW CREATE DATABASE 数据库名;
# 查看当前使用的数据库
SELECT DATABASE()
# 使用数据库
USE 数据库名;
3. 数据查询【DQL】
3.1 数据库表的基本结构
关系数据库是以表格(Table)进行数据存储,表格由"行"和"列"组成
- 经验:执行查询语句返回的结果集是一张虚拟表。
3.2 SQL语句执行顺序
from->on->join->where->group by->having->select->distinct->order by->limit
3.2.1 SQL语句编写顺序

3.2.2 条件查询
语法:SELECT 列名 FROM 表名 WHERE 条件;
1.关系判断(>,<,=,!=,>=,<=,<>【不等于】)
2.逻辑判断(and,or,not)
3.区间判断(between ... and)
4.控制判断(IS NULL、IS NOT NULL)
5.枚举查询(IN(值1,值2...))
6.模糊查询(LIKE _:单个任意字符,%:任意长度字符)
7.分支查询(CASE-WHERE-END)
8.子查询【重点】
1.作枚举查询条件 - 放在WHERE中 - 多行单列
- 注:当子查询结果集为"多行单列"时可以使用ALL或ANY关键字
2.作为一张表 - 放在FROM后 - 多行多列
语法:SELECT 列名 FROM (子查询的结果集) AS 表别名 WHERE 条件;
- 注:将子查询的"多行多列"的结果作为外部查询的一张表,做第二次查询
- 注:子查询作为临时表,可以为其创建一个临时表名
3.2.3 时间查询
语法:SELECT 时间函数([参数列表])
- 经验:执行事件函数查询,会自动生成一张虚表(一行一列)
3.2.3 字符串查询
语法:SELECT 字符串函数([参数列表])
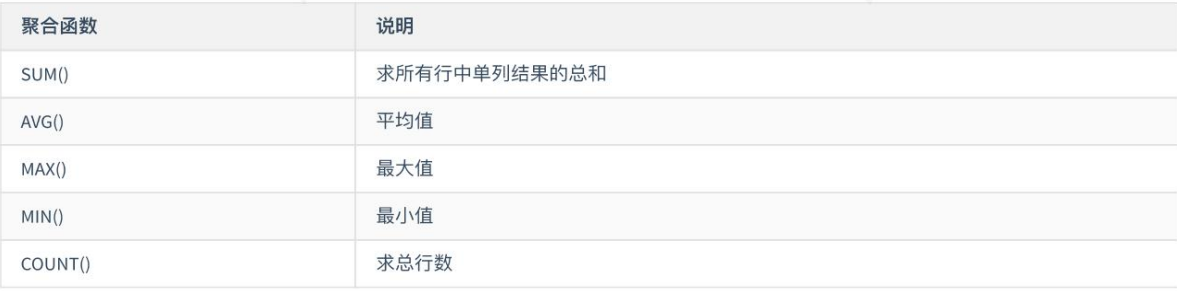
3.3 聚合函数 - 自动忽略null值,不进行统计
语法:SELECT 聚合函数(列名) FROM 表名;
- 经验:对多条数据的单列进行统计,返回统计后的一行结果。
3.4 分组查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组依据(列);

- 注:分组查询中,select显示的列只能是分组依据列,或者聚合函数,不能出现其他列。
3.5 分组过滤查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组列 HAVING 过滤规则;

3.6 限定查询
语法:SELECT 列名 FROM 表名 LIMIT 起始行,查询行数;

3.7 合并查询
;合并两张表的的结果(去除重复记录)
SELECT * FROM 表名1 UNION SELECT * FROM 表名2;
;合并两张表的结果(不去出重复记录)
SELECT * FROM 表名1 UNION ALL SELECT * FROM 表名2;
3.8 表连接查询
语法:SELECT 列名 FROM 表1 连接方式 表2 ON 连接条件;
连接方式:
INNER JOIN:内连接,匹配不到不返回
LEFT JOIN ON:左外连接,以左表为主表依次向右匹配,匹配到返回结果,匹配不到对应列返回NULL值填充
RIGHT JOIN ON:右外连接,以右表为主表依次向左匹配,匹配到返回结果,匹配不到对应列返回NULL值填充
4. DML操作【重点】
4.1 新增(INSERT)
增加一行:INSERT INTO 表名(列1,列2...) VALUES(值1,值2...);
增加多行:INSERT INTO 表名(列1,列2...) VALUES(值1,值2),(值1,值2),...,(值1,值2);
4.2 修改(UPDATE)
UPDATE 表名 SET 列1 = 值1,列2 = 值2,... WHERE 条件;
4.3 删除(DELETE)
DELETE FROM 表名 WHERE 条件;
- 注意:删除时,如如不加WHERE条件,删除的是整张表的数据
4.4 清空整张表 - 清空数据
TRUNCATE TABLE 表名;
- 注:RRUNCATE与DELETE不加WHERE删除整表数据不同,TRUNCATE是把原表销毁,再建一个新表
5. 数据表操作
5.1 数据表的创键(CREATE)
CREATE TABLE 表名(
列名 数据类型 [约束],
列名 数据类型 [约束]
)[charset=utf8]
5.2 数据表的修改(ALTER)
ALTER TABLE 表名 操作;
5.2.1 向现有表中添加列
ALTER TABLE 表名 ADD 列名 数据类型;
5.2.2 修改表中的列
ALTER TABLE 表名 MODIFY 列名 数据类型;
5.2.3 删除表中的列
ALTER TABLE 表名 DROP 列名;
5.2.4 修改列名
ALTER TABLE 表名 CHANGE 列名 新列名 数据类型;
- 注:修改列名时,在给定列新名称时,要指定列的类型和约束
5.3 数据表的删除(DROP)
# 删除学生表
DROP TABLE subject;
6. 约束
6.1 实体完整性约束 - 限制行
表中的一行数据代表一个实体(entity),实体完整性的作用是标识每一行数据不重复、实体唯一。
6.1.1 主键约束
PRIMARY KEY唯一,标识表中的一行数据,此列的值不可重复,且不能为NULL。
6.1.2 唯一约束
UNIQUE唯一,标识表中的一行数据,不可重复,可以为NULL
6.1.3 自动增长列
AUTO_INCREMENT自动增长,给主键数值列添加自动增长。从1开始,每次加1。不能单独使用和主键配合。
6.2 域完整性约束 - 限制列
限制列的单元格的数据正确性
6.2.1 非空约束
NOT NULL非空,此列必须有值
6.2.2 默认值约束
DEFAULT值为列赋予默认值,当新增数据不指定值时,书写DEFAULT,以指定的默认值进行填充。
6.2.3 引用完整性约束【重点】
语法:CONSTRAINT 引用名 FOREIGN KEY(列名) REFERENCES 被引用表名(列名)
详解:FOREIGN KEY引用外部表的某个列的值,新增数据时,约束此列的值必须是引用表中存在的值。
- 注意:当两张表存在引用关系,要执行删除操作,一定要先删除从表(引用表),在删除主表(被引用表)
- 注意:创键关联表时,先创建主表,在创建从表
6.3 常用约束用法
6.3.1 主键自增长
PRIMARY KEY AUTO_INCREMENT
6.3.2 唯一非空约束
UNIQUE NOT NULL
7. 事务【重点】
7.1 事务的概念
事务是一个原子操作。是一个最小执行单元。可以由一个或多个SQL语句组成,在同一个事务当中,所有的SQL语句都成功执行时,整个事务成功,有一个SQL语句执行失败,整个事务都执行失败。
7.2 事务的边界
开始:连接到数据库,执行一条DML(增,删,改)语句。上一个事务结束后,又输入一条DML语句,即事务的开始。
结束:
- 提交:
a.显示提交:commit;
b.隐式提交:一条创键、删除的语句,正常退出(客户端退出连接);
2)回滚:
a.显示回滚:rollback;
b.隐式回滚:非正常退出(断电、宕机),执行里创键、删除的语句,但是失败了,会为这个无效的语句执行回滚。
7.3 事务的原理
数据库会为每个客户端都维护一个空间独立的缓存区(回滚段),一个事务中所有的增删改语句的执行结果都会缓存在回滚段中,只有当事务中所有SQL语句均正常结束(commit),才会将回滚段中的数据同步到数据库。否则无论因为哪种原因失败,整个事务将回滚(rollback)。
7.4 事务的特性
- Atomicity(原子性)
表示一个事务内的所有操作是一个整体,要么全部成功,要么全部失败
- Consistency(一致性)
表示一个事务内有一个操作失败时,所有的更改过的数据都必须回滚到修改前状态。
- Isolation(隔离性)
事务查看数据操作是数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。
- Durability(持久性)
持久性事务完成之后,它对于系统的影响是永久性的。
7.5 事务应用
应用环境:基于增删改语句的操作结果(均返回操作后受影响的行数),可通过程序逻辑手动控制事务提交或回滚。
#1.开启事务
START TRANSACTION;
#2.禁止自动提交
set AutoCommit=0;
#3.事务内执行DML语句
#4.事务内语句都成功了,执行commit
COMMIT
#5.事务内如果出现错误,执行ROLLBACK;
ROLLBACK
8. 权限管理
8.1 创建用户
CREATE USER 用户名 IDENTIFIED BY 密码;
8.2 授权 - GRANT
GRANT ALL ON 数据库.表 TO 用户名;
8.3 撤销权限
REVOKE ALL ON 数据库.表 FROM 用户名;
- 注:具体权限可以百度,ALL是所有权限
8.4 删除用户
DROP USER 用户名;
9. 视图 - 就是为了方便查询使用的,一般仅用于查询使用
9.1 视图概念 - 保障数据库系统安全
视图,虚拟表,从一个表或多个表中查询出来的表,作用和真实表一样,包含一系列带有行和列的数据。视图中,用户可以使用SELECT语句查询数据,也可以使用INSERT,UPDATE,DELETE修改记录,视图可以使用户操作方便,并保障数据库系统安全。
当用户对数据库中的一张或者多张表的某些字段的组合感兴趣,而又不想每次键入这些查询时,用户就可以定义一个视图,以便解决这个问题。视图中列可以来自于表里的不同列,这些列都是用户所感兴趣的数据列。
视图与表不同,它在物理上不是真实存在的,而是一个虚表。在数据库里仅存放视图的定义,而不存放视图对应的数据。视图中的这些数据存放在其对应的表中,如果表中的数据发生了变化,从视图中查询出的数据也会随之发生改变。从这个意义来看,视图就像一个窗口,透过它可以看到数据库中用户感兴趣的数据及变化。每一次查看视图或引用视图的的时候,都会运行一次视图上的查询。
用户可以使用SELECT语句从视图里查询数据,对于符合一定约束条件的视图,还可以使用INSERT、UPDATE、DELETE、MERGE INTO等语句修改视图对应的基础表里的数据。视图在提供操作方便的同时,还可以保障数据库数据的安全。
9.2 视图特点
- 优点
- 简单化,数据所见即所得
- 安全性,用户只能查询或修改他们所能见得到的数据。
- 逻辑独立性,可以屏蔽真实表结构变化带来的影响。
- 缺点
- 性能相对较差,简单的查询也会变得稍显复杂。
- 修改不方便,特别是负责的聚合视图基本无法修改。
9.3 视图的创建
9.3.1 创键视图
语法:CREATE VIEW 视图名 AS 查询数据源表语句;
9.3.2 使用视图
把视图当作表正常操作即可
9.3.3 视图的修改
- 方式一:CREATE OR REPLACE VIEW 视图名 AS 查询语句 ; 如果视图存在则进行修改,反之创键
- 方式二:ALTER VIEW 视图名 AS 查询语句 ; 直接对已存在的视图进行修改
9.3.4 视图的删除
DROP VIEW 视图名
9.3.5 视图的注意事项
1.视图不会独立存储数据,原表发生改变,视图也发生改变。没有任何查询优化。
2.如果试图包含以下结构中的一种,则视图不可更新
- 聚合函数的结果
- DISTINCE去重后的结果
- GROUP BY 分组后的结果
- HAVING 筛选后的结果
- UNION、UNION ALL联合后的结果
9.4 什么时候使用视图
当需要对某的表的一列或几列单独查询时,为了减少麻烦,可以使用视图把这几列单独取出来
10. 索引 - 为了优化查询,一般作用于表的字段上
10.1 索引的作用
索引的目的在于提高查询效率
10.2 创建索引
语法:CREATE INDEX 索引名称 ON 表名(字段名称(长度))
10.3 索引的优缺点
1.使用索引会影响更新和插入速度,因为还要修改索引文件
2.索引要占用内存
3.一般之间以给需要经常查询的表的字段建立索引,加快查询速度