废话不多说,直接上源代码:这个程序是加载进内核的模块,作用是:打印系统中所有进程的一些信息,注意:这是ubuntu系统下的操作
#include <linux/kernel.h>
#include <linux/sched.h> //这个文件定义了linux下的task_struct数据结构
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fdtable.h>
#include <linux/init_task.h> //里面定义了 init_task (0号进程)
//内核模块初始化函数
static int __init print_pid(void)
{
struct task_struct *task,*p; //指向PCB的指针
struct list_head *pos;//list_head是一个双向链表,用来链接os中的所有进程,我们可以用它访问系统中的所有进程,
//每个pcb内部都维护一个list_head类型的tasks链表,这样就可以通过>每个进程的pcb访问所有进程了
int count=0;//记录当前系统中的进程数目
printk("Hello World enter begin:
");
task=&init_task; //0号进程,所有进程的父进程,遍历进程链表list_head从0号进程开始
//list_for_each用来遍历进程链表,让pos从头指向task双向链表中的每一个结点(task_struct),list_for_each是一个宏
//list.h头文件中
list_for_each(pos,&task->tasks)
{
//list_entry是一个容器宏 ,作用是:让pos从指向结构体task_struct的成员tasks,变为指向结构提task_struct本身,
//由内部成员地址指向拥有该成员的结构体地址
p=list_entry(pos,struct task_struct,tasks);
count++; //++
printk("
");
//现在pos指向了每一个进程的pcb,那么就可以输出pcb中的信息了
printk("pid:%d; state:%lx; prio:%d; static_prio:%d; parent'pid:%d;",
p->pid,p->state,p->prio,p->static_prio,(p->parent)->pid);
}
printk("进程的个数:%d
",count);
return 0;
}
//内核退出函数
static void __exit pid_exit(void)
{
printk("exiting...
");
}
module_init(print_pid);
module_exit(pid_exit);
MODULE_LICENSE("GPL");
部分函数原型:
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
宏,用来遍历head链表,并且让pos指向每一个结点
#define list_for_each(pos, head)
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
ptr表示member的地址,type表示结构体的类型.member结构体中的成员
#define list_entry(ptr, type, member)
container_of(ptr, type, member)
2.task_struct数据结构简单介绍,信息太多了,这里仅仅介绍目前用的
task_struc位于<linux/sched.h>头文件中
//linux中进程的状态
/* Used in tsk->state:进程的状态都是2的次幂,保证"与"操作可以得到所有状态 */
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
#define __TASK_STOPPED 0x0004
#define __TASK_TRACED 0x0008
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
/* -1 unrunnable, 0 runnable, >0 stopped: 进程状态*/
volatile long state;
/* 父亲进程*/
struct task_struct __rcu *real_parent;
/* 养父进程 采用链表*/
struct task_struct __rcu *parent;
/*
* 子孙,兄弟,和组领导者进程,双向链表链接
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
//每个进程task_struct内都有一个list_head双向链表,用来链接系统中所有的进程pcb
//我们可以通过它来获得系统中所有的进程信息
struct list_head tasks;
//线程对应的pid
pid_t pid;
//线程组的pid
pid_t tgid;
....
//优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
...
插入一张图片说明进程之间的关系,养父是因为父亲可能被杀死,或者断了,那么系统要为当前进程找一个养父进程,否则当前进程及兄弟,孩子进程资源无法释放,导致内存用不了了(因为指针丢了,招不到这块内存的地址了)

系统中进程的组织方式:

3.Makefile文件编写
.c内核正文文件
Makefile文件用来编译产生内核.ko模块的
文件架构:

obj-m:=task_struct.o #产生task_struct模块的目标文件
#目标文件 文件 要与模块文件名字相同
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules #编译模块
#[Tab] 内核的路径 当前目录编译完放在哪里 表明编译的是内核>文件
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
4.编译

5.插入内核,并显示结果

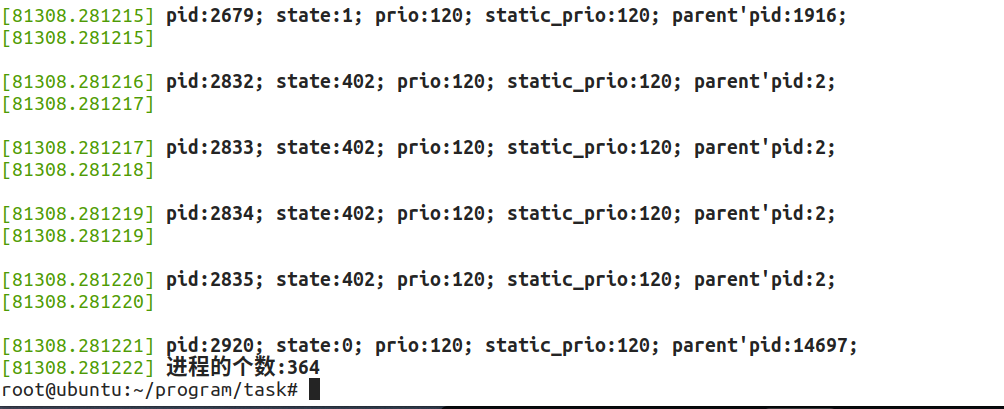
显示消息:使用命令dmesg,这里只截取了部分太多了,发现我的系统目前有364个进程
附录:完整的task_struct定义和sched.h头文件
/* SPDX-License-Identifier: GPL-2.0 */ #ifndef _LINUX_SCHED_H #define _LINUX_SCHED_H /* * Define 'struct task_struct' and provide the main scheduler * APIs (schedule(), wakeup variants, etc.) */ #include <uapi/linux/sched.h> #include <asm/current.h> #include <linux/pid.h> #include <linux/sem.h> #include <linux/shm.h> #include <linux/kcov.h> #include <linux/mutex.h> #include <linux/plist.h> #include <linux/hrtimer.h> #include <linux/seccomp.h> #include <linux/nodemask.h> #include <linux/rcupdate.h> #include <linux/refcount.h> #include <linux/resource.h> #include <linux/latencytop.h> #include <linux/sched/prio.h> #include <linux/sched/types.h> #include <linux/signal_types.h> #include <linux/mm_types_task.h> #include <linux/task_io_accounting.h> #include <linux/posix-timers.h> #include <linux/rseq.h> /* task_struct member predeclarations (sorted alphabetically): */ struct audit_context; struct backing_dev_info; struct bio_list; struct blk_plug; struct capture_control; struct cfs_rq; struct fs_struct; struct futex_pi_state; struct io_context; struct mempolicy; struct nameidata; struct nsproxy; struct perf_event_context; struct pid_namespace; struct pipe_inode_info; struct rcu_node; struct reclaim_state; struct robust_list_head; struct root_domain; struct rq; struct sched_attr; struct sched_param; struct seq_file; struct sighand_struct; struct signal_struct; struct task_delay_info; struct task_group; /* * Task state bitmask. NOTE! These bits are also * encoded in fs/proc/array.c: get_task_state(). * * We have two separate sets of flags: task->state * is about runnability, while task->exit_state are * about the task exiting. Confusing, but this way * modifying one set can't modify the other one by * mistake. */ /* Used in tsk->state:进程的状态都是2的次幂保证"与"操作可以得到所有状态 */ #define TASK_RUNNING 0x0000 #define TASK_INTERRUPTIBLE 0x0001 #define TASK_UNINTERRUPTIBLE 0x0002 #define __TASK_STOPPED 0x0004 #define __TASK_TRACED 0x0008 /* Used in tsk->exit_state: */ #define EXIT_DEAD 0x0010 #define EXIT_ZOMBIE 0x0020 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) /* Used in tsk->state again: */ #define TASK_PARKED 0x0040 #define TASK_DEAD 0x0080 #define TASK_WAKEKILL 0x0100 #define TASK_WAKING 0x0200 #define TASK_NOLOAD 0x0400 #define TASK_NEW 0x0800 #define TASK_STATE_MAX 0x1000 /* Convenience macros for the sake of set_current_state: */ #define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE) #define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED) #define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED) #define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD) /* Convenience macros for the sake of wake_up(): */ #define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE) /* get_task_state(): */ #define TASK_REPORT (TASK_RUNNING | TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE | __TASK_STOPPED | __TASK_TRACED | EXIT_DEAD | EXIT_ZOMBIE | TASK_PARKED) #define task_is_traced(task) ((task->state & __TASK_TRACED) != 0) #define task_is_stopped(task) ((task->state & __TASK_STOPPED) != 0) #define task_is_stopped_or_traced(task) ((task->state & (__TASK_STOPPED | __TASK_TRACED)) != 0) #define task_contributes_to_load(task) ((task->state & TASK_UNINTERRUPTIBLE) != 0 && (task->flags & PF_FROZEN) == 0 && (task->state & TASK_NOLOAD) == 0) #ifdef CONFIG_DEBUG_ATOMIC_SLEEP /* * Special states are those that do not use the normal wait-loop pattern. See * the comment with set_special_state(). */ #define is_special_task_state(state) ((state) & (__TASK_STOPPED | __TASK_TRACED | TASK_PARKED | TASK_DEAD)) #define __set_current_state(state_value) do { WARN_ON_ONCE(is_special_task_state(state_value)); current->task_state_change = _THIS_IP_; current->state = (state_value); } while (0) #define set_current_state(state_value) do { WARN_ON_ONCE(is_special_task_state(state_value)); current->task_state_change = _THIS_IP_; smp_store_mb(current->state, (state_value)); } while (0) #define set_special_state(state_value) do { unsigned long flags; /* may shadow */ WARN_ON_ONCE(!is_special_task_state(state_value)); raw_spin_lock_irqsave(¤t->pi_lock, flags); current->task_state_change = _THIS_IP_; current->state = (state_value); raw_spin_unlock_irqrestore(¤t->pi_lock, flags); } while (0) #else /* * set_current_state() includes a barrier so that the write of current->state * is correctly serialised wrt the caller's subsequent test of whether to * actually sleep: * * for (;;) { * set_current_state(TASK_UNINTERRUPTIBLE); * if (!need_sleep) * break; * * schedule(); * } * __set_current_state(TASK_RUNNING); * * If the caller does not need such serialisation (because, for instance, the * condition test and condition change and wakeup are under the same lock) then * use __set_current_state(). * * The above is typically ordered against the wakeup, which does: * * need_sleep = false; * wake_up_state(p, TASK_UNINTERRUPTIBLE); * * where wake_up_state() executes a full memory barrier before accessing the * task state. * * Wakeup will do: if (@state & p->state) p->state = TASK_RUNNING, that is, * once it observes the TASK_UNINTERRUPTIBLE store the waking CPU can issue a * TASK_RUNNING store which can collide with __set_current_state(TASK_RUNNING). * * However, with slightly different timing the wakeup TASK_RUNNING store can * also collide with the TASK_UNINTERRUPTIBLE store. Losing that store is not * a problem either because that will result in one extra go around the loop * and our @cond test will save the day. * * Also see the comments of try_to_wake_up(). */ #define __set_current_state(state_value) current->state = (state_value) #define set_current_state(state_value) smp_store_mb(current->state, (state_value)) /* * set_special_state() should be used for those states when the blocking task * can not use the regular condition based wait-loop. In that case we must * serialize against wakeups such that any possible in-flight TASK_RUNNING stores * will not collide with our state change. */ #define set_special_state(state_value) do { unsigned long flags; /* may shadow */ raw_spin_lock_irqsave(¤t->pi_lock, flags); current->state = (state_value); raw_spin_unlock_irqrestore(¤t->pi_lock, flags); } while (0) #endif /* Task command name length: */ #define TASK_COMM_LEN 16 extern void scheduler_tick(void); #define MAX_SCHEDULE_TIMEOUT LONG_MAX extern long schedule_timeout(long timeout); extern long schedule_timeout_interruptible(long timeout); extern long schedule_timeout_killable(long timeout); extern long schedule_timeout_uninterruptible(long timeout); extern long schedule_timeout_idle(long timeout); asmlinkage void schedule(void); extern void schedule_preempt_disabled(void); asmlinkage void preempt_schedule_irq(void); extern int __must_check io_schedule_prepare(void); extern void io_schedule_finish(int token); extern long io_schedule_timeout(long timeout); extern void io_schedule(void); /** * struct prev_cputime - snapshot of system and user cputime * @utime: time spent in user mode * @stime: time spent in system mode * @lock: protects the above two fields * * Stores previous user/system time values such that we can guarantee * monotonicity. */ struct prev_cputime { #ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE u64 utime; u64 stime; raw_spinlock_t lock; #endif }; enum vtime_state { /* Task is sleeping or running in a CPU with VTIME inactive: */ VTIME_INACTIVE = 0, /* Task runs in userspace in a CPU with VTIME active: */ VTIME_USER, /* Task runs in kernelspace in a CPU with VTIME active: */ VTIME_SYS, }; struct vtime { seqcount_t seqcount; unsigned long long starttime; enum vtime_state state; u64 utime; u64 stime; u64 gtime; }; /* * Utilization clamp constraints. * @UCLAMP_MIN: Minimum utilization * @UCLAMP_MAX: Maximum utilization * @UCLAMP_CNT: Utilization clamp constraints count */ enum uclamp_id { UCLAMP_MIN = 0, UCLAMP_MAX, UCLAMP_CNT }; #ifdef CONFIG_SMP extern struct root_domain def_root_domain; extern struct mutex sched_domains_mutex; #endif struct sched_info { #ifdef CONFIG_SCHED_INFO /* Cumulative counters: */ /* # of times we have run on this CPU: */ unsigned long pcount; /* Time spent waiting on a runqueue: */ unsigned long long run_delay; /* Timestamps: */ /* When did we last run on a CPU? */ unsigned long long last_arrival; /* When were we last queued to run? */ unsigned long long last_queued; #endif /* CONFIG_SCHED_INFO */ }; /* * Integer metrics need fixed point arithmetic, e.g., sched/fair * has a few: load, load_avg, util_avg, freq, and capacity. * * We define a basic fixed point arithmetic range, and then formalize * all these metrics based on that basic range. */ # define SCHED_FIXEDPOINT_SHIFT 10 # define SCHED_FIXEDPOINT_SCALE (1L << SCHED_FIXEDPOINT_SHIFT) /* Increase resolution of cpu_capacity calculations */ # define SCHED_CAPACITY_SHIFT SCHED_FIXEDPOINT_SHIFT # define SCHED_CAPACITY_SCALE (1L << SCHED_CAPACITY_SHIFT) struct load_weight { unsigned long weight; u32 inv_weight; }; /** * struct util_est - Estimation utilization of FAIR tasks * @enqueued: instantaneous estimated utilization of a task/cpu * @ewma: the Exponential Weighted Moving Average (EWMA) * utilization of a task * * Support data structure to track an Exponential Weighted Moving Average * (EWMA) of a FAIR task's utilization. New samples are added to the moving * average each time a task completes an activation. Sample's weight is chosen * so that the EWMA will be relatively insensitive to transient changes to the * task's workload. * * The enqueued attribute has a slightly different meaning for tasks and cpus: * - task: the task's util_avg at last task dequeue time * - cfs_rq: the sum of util_est.enqueued for each RUNNABLE task on that CPU * Thus, the util_est.enqueued of a task represents the contribution on the * estimated utilization of the CPU where that task is currently enqueued. * * Only for tasks we track a moving average of the past instantaneous * estimated utilization. This allows to absorb sporadic drops in utilization * of an otherwise almost periodic task. */ struct util_est { unsigned int enqueued; unsigned int ewma; #define UTIL_EST_WEIGHT_SHIFT 2 } __attribute__((__aligned__(sizeof(u64)))); /* * The load_avg/util_avg accumulates an infinite geometric series * (see __update_load_avg() in kernel/sched/fair.c). * * [load_avg definition] * * load_avg = runnable% * scale_load_down(load) * * where runnable% is the time ratio that a sched_entity is runnable. * For cfs_rq, it is the aggregated load_avg of all runnable and * blocked sched_entities. * * [util_avg definition] * * util_avg = running% * SCHED_CAPACITY_SCALE * * where running% is the time ratio that a sched_entity is running on * a CPU. For cfs_rq, it is the aggregated util_avg of all runnable * and blocked sched_entities. * * load_avg and util_avg don't direcly factor frequency scaling and CPU * capacity scaling. The scaling is done through the rq_clock_pelt that * is used for computing those signals (see update_rq_clock_pelt()) * * N.B., the above ratios (runnable% and running%) themselves are in the * range of [0, 1]. To do fixed point arithmetics, we therefore scale them * to as large a range as necessary. This is for example reflected by * util_avg's SCHED_CAPACITY_SCALE. * * [Overflow issue] * * The 64-bit load_sum can have 4353082796 (=2^64/47742/88761) entities * with the highest load (=88761), always runnable on a single cfs_rq, * and should not overflow as the number already hits PID_MAX_LIMIT. * * For all other cases (including 32-bit kernels), struct load_weight's * weight will overflow first before we do, because: * * Max(load_avg) <= Max(load.weight) * * Then it is the load_weight's responsibility to consider overflow * issues. */ struct sched_avg { u64 last_update_time; u64 load_sum; u64 runnable_load_sum; u32 util_sum; u32 period_contrib; unsigned long load_avg; unsigned long runnable_load_avg; unsigned long util_avg; struct util_est util_est; } ____cacheline_aligned; struct sched_statistics { #ifdef CONFIG_SCHEDSTATS u64 wait_start; u64 wait_max; u64 wait_count; u64 wait_sum; u64 iowait_count; u64 iowait_sum; u64 sleep_start; u64 sleep_max; s64 sum_sleep_runtime; u64 block_start; u64 block_max; u64 exec_max; u64 slice_max; u64 nr_migrations_cold; u64 nr_failed_migrations_affine; u64 nr_failed_migrations_running; u64 nr_failed_migrations_hot; u64 nr_forced_migrations; u64 nr_wakeups; u64 nr_wakeups_sync; u64 nr_wakeups_migrate; u64 nr_wakeups_local; u64 nr_wakeups_remote; u64 nr_wakeups_affine; u64 nr_wakeups_affine_attempts; u64 nr_wakeups_passive; u64 nr_wakeups_idle; #endif }; struct sched_entity { /* For load-balancing: */ struct load_weight load; unsigned long runnable_weight; struct rb_node run_node; struct list_head group_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; u64 nr_migrations; struct sched_statistics statistics; #ifdef CONFIG_FAIR_GROUP_SCHED int depth; struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif #ifdef CONFIG_SMP /* * Per entity load average tracking. * * Put into separate cache line so it does not * collide with read-mostly values above. */ struct sched_avg avg; #endif }; struct sched_rt_entity { struct list_head run_list; unsigned long timeout; unsigned long watchdog_stamp; unsigned int time_slice; unsigned short on_rq; unsigned short on_list; struct sched_rt_entity *back; #ifdef CONFIG_RT_GROUP_SCHED struct sched_rt_entity *parent; /* rq on which this entity is (to be) queued: */ struct rt_rq *rt_rq; /* rq "owned" by this entity/group: */ struct rt_rq *my_q; #endif } __randomize_layout; struct sched_dl_entity { struct rb_node rb_node; /* * Original scheduling parameters. Copied here from sched_attr * during sched_setattr(), they will remain the same until * the next sched_setattr(). */ u64 dl_runtime; /* Maximum runtime for each instance */ u64 dl_deadline; /* Relative deadline of each instance */ u64 dl_period; /* Separation of two instances (period) */ u64 dl_bw; /* dl_runtime / dl_period */ u64 dl_density; /* dl_runtime / dl_deadline */ /* * Actual scheduling parameters. Initialized with the values above, * they are continuously updated during task execution. Note that * the remaining runtime could be < 0 in case we are in overrun. */ s64 runtime; /* Remaining runtime for this instance */ u64 deadline; /* Absolute deadline for this instance */ unsigned int flags; /* Specifying the scheduler behaviour */ /* * Some bool flags: * * @dl_throttled tells if we exhausted the runtime. If so, the * task has to wait for a replenishment to be performed at the * next firing of dl_timer. * * @dl_boosted tells if we are boosted due to DI. If so we are * outside bandwidth enforcement mechanism (but only until we * exit the critical section); * * @dl_yielded tells if task gave up the CPU before consuming * all its available runtime during the last job. * * @dl_non_contending tells if the task is inactive while still * contributing to the active utilization. In other words, it * indicates if the inactive timer has been armed and its handler * has not been executed yet. This flag is useful to avoid race * conditions between the inactive timer handler and the wakeup * code. * * @dl_overrun tells if the task asked to be informed about runtime * overruns. */ unsigned int dl_throttled : 1; unsigned int dl_boosted : 1; unsigned int dl_yielded : 1; unsigned int dl_non_contending : 1; unsigned int dl_overrun : 1; /* * Bandwidth enforcement timer. Each -deadline task has its * own bandwidth to be enforced, thus we need one timer per task. */ struct hrtimer dl_timer; /* * Inactive timer, responsible for decreasing the active utilization * at the "0-lag time". When a -deadline task blocks, it contributes * to GRUB's active utilization until the "0-lag time", hence a * timer is needed to decrease the active utilization at the correct * time. */ struct hrtimer inactive_timer; }; #ifdef CONFIG_UCLAMP_TASK /* Number of utilization clamp buckets (shorter alias) */ #define UCLAMP_BUCKETS CONFIG_UCLAMP_BUCKETS_COUNT /* * Utilization clamp for a scheduling entity * @value: clamp value "assigned" to a se * @bucket_id: bucket index corresponding to the "assigned" value * @active: the se is currently refcounted in a rq's bucket * @user_defined: the requested clamp value comes from user-space * * The bucket_id is the index of the clamp bucket matching the clamp value * which is pre-computed and stored to avoid expensive integer divisions from * the fast path. * * The active bit is set whenever a task has got an "effective" value assigned, * which can be different from the clamp value "requested" from user-space. * This allows to know a task is refcounted in the rq's bucket corresponding * to the "effective" bucket_id. * * The user_defined bit is set whenever a task has got a task-specific clamp * value requested from userspace, i.e. the system defaults apply to this task * just as a restriction. This allows to relax default clamps when a less * restrictive task-specific value has been requested, thus allowing to * implement a "nice" semantic. For example, a task running with a 20% * default boost can still drop its own boosting to 0%. */ struct uclamp_se { unsigned int value : bits_per(SCHED_CAPACITY_SCALE); unsigned int bucket_id : bits_per(UCLAMP_BUCKETS); unsigned int active : 1; unsigned int user_defined : 1; }; #endif /* CONFIG_UCLAMP_TASK */ union rcu_special { struct { u8 blocked; u8 need_qs; u8 exp_hint; /* Hint for performance. */ u8 deferred_qs; } b; /* Bits. */ u32 s; /* Set of bits. */ }; enum perf_event_task_context { perf_invalid_context = -1, perf_hw_context = 0, perf_sw_context, perf_nr_task_contexts, }; struct wake_q_node { struct wake_q_node *next; }; struct task_struct { #ifdef CONFIG_THREAD_INFO_IN_TASK /* * For reasons of header soup (see current_thread_info()), this * must be the first element of task_struct. */ struct thread_info thread_info; #endif /* -1 unrunnable, 0 runnable, >0 stopped: */ volatile long state; /* * This begins the randomizable portion of task_struct. Only * scheduling-critical items should be added above here. */ randomized_struct_fields_start void *stack; refcount_t usage; /* Per task flags (PF_*), defined further below: */ unsigned int flags; unsigned int ptrace; #ifdef CONFIG_SMP struct llist_node wake_entry; int on_cpu; #ifdef CONFIG_THREAD_INFO_IN_TASK /* Current CPU: */ unsigned int cpu; #endif unsigned int wakee_flips; unsigned long wakee_flip_decay_ts; struct task_struct *last_wakee; /* * recent_used_cpu is initially set as the last CPU used by a task * that wakes affine another task. Waker/wakee relationships can * push tasks around a CPU where each wakeup moves to the next one. * Tracking a recently used CPU allows a quick search for a recently * used CPU that may be idle. */ int recent_used_cpu; int wake_cpu; #endif int on_rq; int prio; int static_prio; int normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; #ifdef CONFIG_CGROUP_SCHED struct task_group *sched_task_group; #endif struct sched_dl_entity dl; #ifdef CONFIG_UCLAMP_TASK /* Clamp values requested for a scheduling entity */ struct uclamp_se uclamp_req[UCLAMP_CNT]; /* Effective clamp values used for a scheduling entity */ struct uclamp_se uclamp[UCLAMP_CNT]; #endif #ifdef CONFIG_PREEMPT_NOTIFIERS /* List of struct preempt_notifier: */ struct hlist_head preempt_notifiers; #endif #ifdef CONFIG_BLK_DEV_IO_TRACE unsigned int btrace_seq; #endif unsigned int policy; int nr_cpus_allowed; const cpumask_t *cpus_ptr; cpumask_t cpus_mask; #ifdef CONFIG_PREEMPT_RCU int rcu_read_lock_nesting; union rcu_special rcu_read_unlock_special; struct list_head rcu_node_entry; struct rcu_node *rcu_blocked_node; #endif /* #ifdef CONFIG_PREEMPT_RCU */ #ifdef CONFIG_TASKS_RCU unsigned long rcu_tasks_nvcsw; u8 rcu_tasks_holdout; u8 rcu_tasks_idx; int rcu_tasks_idle_cpu; struct list_head rcu_tasks_holdout_list; #endif /* #ifdef CONFIG_TASKS_RCU */ struct sched_info sched_info; struct list_head tasks; #ifdef CONFIG_SMP struct plist_node pushable_tasks; struct rb_node pushable_dl_tasks; #endif struct mm_struct *mm; struct mm_struct *active_mm; /* Per-thread vma caching: */ struct vmacache vmacache; #ifdef SPLIT_RSS_COUNTING struct task_rss_stat rss_stat; #endif int exit_state; int exit_code; int exit_signal; /* The signal sent when the parent dies: */ int pdeath_signal; /* JOBCTL_*, siglock protected: */ unsigned long jobctl; /* Used for emulating ABI behavior of previous Linux versions: */ unsigned int personality; /* Scheduler bits, serialized by scheduler locks: */ unsigned sched_reset_on_fork:1; unsigned sched_contributes_to_load:1; unsigned sched_migrated:1; unsigned sched_remote_wakeup:1; #ifdef CONFIG_PSI unsigned sched_psi_wake_requeue:1; #endif /* Force alignment to the next boundary: */ unsigned :0; /* Unserialized, strictly 'current' */ /* Bit to tell LSMs we're in execve(): */ unsigned in_execve:1; unsigned in_iowait:1; #ifndef TIF_RESTORE_SIGMASK unsigned restore_sigmask:1; #endif #ifdef CONFIG_MEMCG unsigned in_user_fault:1; #endif #ifdef CONFIG_COMPAT_BRK unsigned brk_randomized:1; #endif #ifdef CONFIG_CGROUPS /* disallow userland-initiated cgroup migration */ unsigned no_cgroup_migration:1; /* task is frozen/stopped (used by the cgroup freezer) */ unsigned frozen:1; #endif #ifdef CONFIG_BLK_CGROUP /* to be used once the psi infrastructure lands upstream. */ unsigned use_memdelay:1; #endif unsigned long atomic_flags; /* Flags requiring atomic access. */ struct restart_block restart_block; pid_t pid; pid_t tgid; #ifdef CONFIG_STACKPROTECTOR /* Canary value for the -fstack-protector GCC feature: */ unsigned long stack_canary; #endif /* * Pointers to the (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->real_parent->pid) */ /* Real parent process: */ struct task_struct __rcu *real_parent; /* Recipient of SIGCHLD, wait4() reports: */ struct task_struct __rcu *parent; /* * Children/sibling form the list of natural children: */ struct list_head children; struct list_head sibling; struct task_struct *group_leader; /* * 'ptraced' is the list of tasks this task is using ptrace() on. * * This includes both natural children and PTRACE_ATTACH targets. * 'ptrace_entry' is this task's link on the p->parent->ptraced list. */ struct list_head ptraced; struct list_head ptrace_entry; /* PID/PID hash table linkage. */ struct pid *thread_pid; struct hlist_node pid_links[PIDTYPE_MAX]; struct list_head thread_group; struct list_head thread_node; struct completion *vfork_done; /* CLONE_CHILD_SETTID: */ int __user *set_child_tid; /* CLONE_CHILD_CLEARTID: */ int __user *clear_child_tid; u64 utime; u64 stime; #ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME u64 utimescaled; u64 stimescaled; #endif u64 gtime; struct prev_cputime prev_cputime; #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN struct vtime vtime; #endif #ifdef CONFIG_NO_HZ_FULL atomic_t tick_dep_mask; #endif /* Context switch counts: */ unsigned long nvcsw; unsigned long nivcsw; /* Monotonic time in nsecs: */ u64 start_time; /* Boot based time in nsecs: */ u64 real_start_time; /* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */ unsigned long min_flt; unsigned long maj_flt; /* Empty if CONFIG_POSIX_CPUTIMERS=n */ struct posix_cputimers posix_cputimers; /* Process credentials: */ /* Tracer's credentials at attach: */ const struct cred __rcu *ptracer_cred; /* Objective and real subjective task credentials (COW): */ const struct cred __rcu *real_cred; /* Effective (overridable) subjective task credentials (COW): */ const struct cred __rcu *cred; #ifdef CONFIG_KEYS /* Cached requested key. */ struct key *cached_requested_key; #endif /* * executable name, excluding path. * * - normally initialized setup_new_exec() * - access it with [gs]et_task_comm() * - lock it with task_lock() */ char comm[TASK_COMM_LEN]; struct nameidata *nameidata; #ifdef CONFIG_SYSVIPC struct sysv_sem sysvsem; struct sysv_shm sysvshm; #endif #ifdef CONFIG_DETECT_HUNG_TASK unsigned long last_switch_count; unsigned long last_switch_time; #endif /* Filesystem information: */ struct fs_struct *fs; /* Open file information: */ struct files_struct *files; /* Namespaces: */ struct nsproxy *nsproxy; /* Signal handlers: */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked; sigset_t real_blocked; /* Restored if set_restore_sigmask() was used: */ sigset_t saved_sigmask; struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; unsigned int sas_ss_flags; struct callback_head *task_works; #ifdef CONFIG_AUDIT #ifdef CONFIG_AUDITSYSCALL struct audit_context *audit_context; #endif kuid_t loginuid; unsigned int sessionid; #endif struct seccomp seccomp; /* Thread group tracking: */ u64 parent_exec_id; u64 self_exec_id; /* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */ spinlock_t alloc_lock; /* Protection of the PI data structures: */ raw_spinlock_t pi_lock; struct wake_q_node wake_q; #ifdef CONFIG_RT_MUTEXES /* PI waiters blocked on a rt_mutex held by this task: */ struct rb_root_cached pi_waiters; /* Updated under owner's pi_lock and rq lock */ struct task_struct *pi_top_task; /* Deadlock detection and priority inheritance handling: */ struct rt_mutex_waiter *pi_blocked_on; #endif #ifdef CONFIG_DEBUG_MUTEXES /* Mutex deadlock detection: */ struct mutex_waiter *blocked_on; #endif #ifdef CONFIG_DEBUG_ATOMIC_SLEEP int non_block_count; #endif #ifdef CONFIG_TRACE_IRQFLAGS unsigned int irq_events; unsigned long hardirq_enable_ip; unsigned long hardirq_disable_ip; unsigned int hardirq_enable_event; unsigned int hardirq_disable_event; int hardirqs_enabled; int hardirq_context; unsigned long softirq_disable_ip; unsigned long softirq_enable_ip; unsigned int softirq_disable_event; unsigned int softirq_enable_event; int softirqs_enabled; int softirq_context; #endif #ifdef CONFIG_LOCKDEP # define MAX_LOCK_DEPTH 48UL u64 curr_chain_key; int lockdep_depth; unsigned int lockdep_recursion; struct held_lock held_locks[MAX_LOCK_DEPTH]; #endif #ifdef CONFIG_UBSAN unsigned int in_ubsan; #endif /* Journalling filesystem info: */ void *journal_info; /* Stacked block device info: */ struct bio_list *bio_list; #ifdef CONFIG_BLOCK /* Stack plugging: */ struct blk_plug *plug; #endif /* VM state: */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; #ifdef CONFIG_COMPACTION struct capture_control *capture_control; #endif /* Ptrace state: */ unsigned long ptrace_message; kernel_siginfo_t *last_siginfo; struct task_io_accounting ioac; #ifdef CONFIG_PSI /* Pressure stall state */ unsigned int psi_flags; #endif #ifdef CONFIG_TASK_XACCT /* Accumulated RSS usage: */ u64 acct_rss_mem1; /* Accumulated virtual memory usage: */ u64 acct_vm_mem1; /* stime + utime since last update: */ u64 acct_timexpd; #endif #ifdef CONFIG_CPUSETS /* Protected by ->alloc_lock: */ nodemask_t mems_allowed; /* Seqence number to catch updates: */ seqcount_t mems_allowed_seq; int cpuset_mem_spread_rotor; int cpuset_slab_spread_rotor; #endif #ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock: */ struct css_set __rcu *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock: */ struct list_head cg_list; #endif #ifdef CONFIG_X86_CPU_RESCTRL u32 closid; u32 rmid; #endif #ifdef CONFIG_FUTEX struct robust_list_head __user *robust_list; #ifdef CONFIG_COMPAT struct compat_robust_list_head __user *compat_robust_list; #endif struct list_head pi_state_list; struct futex_pi_state *pi_state_cache; struct mutex futex_exit_mutex; unsigned int futex_state; #endif #ifdef CONFIG_PERF_EVENTS struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts]; struct mutex perf_event_mutex; struct list_head perf_event_list; #endif #ifdef CONFIG_DEBUG_PREEMPT unsigned long preempt_disable_ip; #endif #ifdef CONFIG_NUMA /* Protected by alloc_lock: */ struct mempolicy *mempolicy; short il_prev; short pref_node_fork; #endif #ifdef CONFIG_NUMA_BALANCING int numa_scan_seq; unsigned int numa_scan_period; unsigned int numa_scan_period_max; int numa_preferred_nid; unsigned long numa_migrate_retry; /* Migration stamp: */ u64 node_stamp; u64 last_task_numa_placement; u64 last_sum_exec_runtime; struct callback_head numa_work; /* * This pointer is only modified for current in syscall and * pagefault context (and for tasks being destroyed), so it can be read * from any of the following contexts: * - RCU read-side critical section * - current->numa_group from everywhere * - task's runqueue locked, task not running */ struct numa_group __rcu *numa_group; /* * numa_faults is an array split into four regions: * faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer * in this precise order. * * faults_memory: Exponential decaying average of faults on a per-node * basis. Scheduling placement decisions are made based on these * counts. The values remain static for the duration of a PTE scan. * faults_cpu: Track the nodes the process was running on when a NUMA * hinting fault was incurred. * faults_memory_buffer and faults_cpu_buffer: Record faults per node * during the current scan window. When the scan completes, the counts * in faults_memory and faults_cpu decay and these values are copied. */ unsigned long *numa_faults; unsigned long total_numa_faults; /* * numa_faults_locality tracks if faults recorded during the last * scan window were remote/local or failed to migrate. The task scan * period is adapted based on the locality of the faults with different * weights depending on whether they were shared or private faults */ unsigned long numa_faults_locality[3]; unsigned long numa_pages_migrated; #endif /* CONFIG_NUMA_BALANCING */ #ifdef CONFIG_RSEQ struct rseq __user *rseq; u32 rseq_sig; /* * RmW on rseq_event_mask must be performed atomically * with respect to preemption. */ unsigned long rseq_event_mask; #endif struct tlbflush_unmap_batch tlb_ubc; union { refcount_t rcu_users; struct rcu_head rcu; }; /* Cache last used pipe for splice(): */ struct pipe_inode_info *splice_pipe; struct page_frag task_frag; #ifdef CONFIG_TASK_DELAY_ACCT struct task_delay_info *delays; #endif #ifdef CONFIG_FAULT_INJECTION int make_it_fail; unsigned int fail_nth; #endif /* * When (nr_dirtied >= nr_dirtied_pause), it's time to call * balance_dirty_pages() for a dirty throttling pause: */ int nr_dirtied; int nr_dirtied_pause; /* Start of a write-and-pause period: */ unsigned long dirty_paused_when; #ifdef CONFIG_LATENCYTOP int latency_record_count; struct latency_record latency_record[LT_SAVECOUNT]; #endif /* * Time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */ u64 timer_slack_ns; u64 default_timer_slack_ns; #ifdef CONFIG_KASAN unsigned int kasan_depth; #endif #ifdef CONFIG_FUNCTION_GRAPH_TRACER /* Index of current stored address in ret_stack: */ int curr_ret_stack; int curr_ret_depth; /* Stack of return addresses for return function tracing: */ struct ftrace_ret_stack *ret_stack; /* Timestamp for last schedule: */ unsigned long long ftrace_timestamp; /* * Number of functions that haven't been traced * because of depth overrun: */ atomic_t trace_overrun; /* Pause tracing: */ atomic_t tracing_graph_pause; #endif #ifdef CONFIG_TRACING /* State flags for use by tracers: */ unsigned long trace; /* Bitmask and counter of trace recursion: */ unsigned long trace_recursion; #endif /* CONFIG_TRACING */ #ifdef CONFIG_KCOV /* Coverage collection mode enabled for this task (0 if disabled): */ unsigned int kcov_mode; /* Size of the kcov_area: */ unsigned int kcov_size; /* Buffer for coverage collection: */ void *kcov_area; /* KCOV descriptor wired with this task or NULL: */ struct kcov *kcov; #endif #ifdef CONFIG_MEMCG struct mem_cgroup *memcg_in_oom; gfp_t memcg_oom_gfp_mask; int memcg_oom_order; /* Number of pages to reclaim on returning to userland: */ unsigned int memcg_nr_pages_over_high; /* Used by memcontrol for targeted memcg charge: */ struct mem_cgroup *active_memcg; #endif #ifdef CONFIG_BLK_CGROUP struct request_queue *throttle_queue; #endif #ifdef CONFIG_UPROBES struct uprobe_task *utask; #endif #if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE) unsigned int sequential_io; unsigned int sequential_io_avg; #endif #ifdef CONFIG_DEBUG_ATOMIC_SLEEP unsigned long task_state_change; #endif int pagefault_disabled; #ifdef CONFIG_MMU struct task_struct *oom_reaper_list; #endif #ifdef CONFIG_VMAP_STACK struct vm_struct *stack_vm_area; #endif #ifdef CONFIG_THREAD_INFO_IN_TASK /* A live task holds one reference: */ refcount_t stack_refcount; #endif #ifdef CONFIG_LIVEPATCH int patch_state; #endif #ifdef CONFIG_SECURITY /* Used by LSM modules for access restriction: */ void *security; #endif #ifdef CONFIG_GCC_PLUGIN_STACKLEAK unsigned long lowest_stack; unsigned long prev_lowest_stack; #endif /* * New fields for task_struct should be added above here, so that * they are included in the randomized portion of task_struct. */ randomized_struct_fields_end /* CPU-specific state of this task: */ struct thread_struct thread; /* * WARNING: on x86, 'thread_struct' contains a variable-sized * structure. It *MUST* be at the end of 'task_struct'. * * Do not put anything below here! */ }; static inline struct pid *task_pid(struct task_struct *task) { return task->thread_pid; } /* * the helpers to get the task's different pids as they are seen * from various namespaces * * task_xid_nr() : global id, i.e. the id seen from the init namespace; * task_xid_vnr() : virtual id, i.e. the id seen from the pid namespace of * current. * task_xid_nr_ns() : id seen from the ns specified; * * see also pid_nr() etc in include/linux/pid.h */ pid_t __task_pid_nr_ns(struct task_struct *task, enum pid_type type, struct pid_namespace *ns); static inline pid_t task_pid_nr(struct task_struct *tsk) { return tsk->pid; } static inline pid_t task_pid_nr_ns(struct task_struct *tsk, struct pid_namespace *ns) { return __task_pid_nr_ns(tsk, PIDTYPE_PID, ns); } static inline pid_t task_pid_vnr(struct task_struct *tsk) { return __task_pid_nr_ns(tsk, PIDTYPE_PID, NULL); } static inline pid_t task_tgid_nr(struct task_struct *tsk) { return tsk->tgid; } /** * pid_alive - check that a task structure is not stale * @p: Task structure to be checked. * * Test if a process is not yet dead (at most zombie state) * If pid_alive fails, then pointers within the task structure * can be stale and must not be dereferenced. * * Return: 1 if the process is alive. 0 otherwise. */ static inline int pid_alive(const struct task_struct *p) { return p->thread_pid != NULL; } static inline pid_t task_pgrp_nr_ns(struct task_struct *tsk, struct pid_namespace *ns) { return __task_pid_nr_ns(tsk, PIDTYPE_PGID, ns); } static inline pid_t task_pgrp_vnr(struct task_struct *tsk) { return __task_pid_nr_ns(tsk, PIDTYPE_PGID, NULL); } static inline pid_t task_session_nr_ns(struct task_struct *tsk, struct pid_namespace *ns) { return __task_pid_nr_ns(tsk, PIDTYPE_SID, ns); } static inline pid_t task_session_vnr(struct task_struct *tsk) { return __task_pid_nr_ns(tsk, PIDTYPE_SID, NULL); } static inline pid_t task_tgid_nr_ns(struct task_struct *tsk, struct pid_namespace *ns) { return __task_pid_nr_ns(tsk, PIDTYPE_TGID, ns); } static inline pid_t task_tgid_vnr(struct task_struct *tsk) { return __task_pid_nr_ns(tsk, PIDTYPE_TGID, NULL); } static inline pid_t task_ppid_nr_ns(const struct task_struct *tsk, struct pid_namespace *ns) { pid_t pid = 0; rcu_read_lock(); if (pid_alive(tsk)) pid = task_tgid_nr_ns(rcu_dereference(tsk->real_parent), ns); rcu_read_unlock(); return pid; } static inline pid_t task_ppid_nr(const struct task_struct *tsk) { return task_ppid_nr_ns(tsk, &init_pid_ns); } /* Obsolete, do not use: */ static inline pid_t task_pgrp_nr(struct task_struct *tsk) { return task_pgrp_nr_ns(tsk, &init_pid_ns); } #define TASK_REPORT_IDLE (TASK_REPORT + 1) #define TASK_REPORT_MAX (TASK_REPORT_IDLE << 1) static inline unsigned int task_state_index(struct task_struct *tsk) { unsigned int tsk_state = READ_ONCE(tsk->state); unsigned int state = (tsk_state | tsk->exit_state) & TASK_REPORT; BUILD_BUG_ON_NOT_POWER_OF_2(TASK_REPORT_MAX); if (tsk_state == TASK_IDLE) state = TASK_REPORT_IDLE; return fls(state); } static inline char task_index_to_char(unsigned int state) { static const char state_char[] = "RSDTtXZPI"; BUILD_BUG_ON(1 + ilog2(TASK_REPORT_MAX) != sizeof(state_char) - 1); return state_char[state]; } static inline char task_state_to_char(struct task_struct *tsk) { return task_index_to_char(task_state_index(tsk)); } /** * is_global_init - check if a task structure is init. Since init * is free to have sub-threads we need to check tgid. * @tsk: Task structure to be checked. * * Check if a task structure is the first user space task the kernel created. * * Return: 1 if the task structure is init. 0 otherwise. */ static inline int is_global_init(struct task_struct *tsk) { return task_tgid_nr(tsk) == 1; } extern struct pid *cad_pid; /* * Per process flags */ #define PF_IDLE 0x00000002 /* I am an IDLE thread */ #define PF_EXITING 0x00000004 /* Getting shut down */ #define PF_VCPU 0x00000010 /* I'm a virtual CPU */ #define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */ #define PF_FORKNOEXEC 0x00000040 /* Forked but didn't exec */ #define PF_MCE_PROCESS 0x00000080 /* Process policy on mce errors */ #define PF_SUPERPRIV 0x00000100 /* Used super-user privileges */ #define PF_DUMPCORE 0x00000200 /* Dumped core */ #define PF_SIGNALED 0x00000400 /* Killed by a signal */ #define PF_MEMALLOC 0x00000800 /* Allocating memory */ #define PF_NPROC_EXCEEDED 0x00001000 /* set_user() noticed that RLIMIT_NPROC was exceeded */ #define PF_USED_MATH 0x00002000 /* If unset the fpu must be initialized before use */ #define PF_USED_ASYNC 0x00004000 /* Used async_schedule*(), used by module init */ #define PF_NOFREEZE 0x00008000 /* This thread should not be frozen */ #define PF_FROZEN 0x00010000 /* Frozen for system suspend */ #define PF_KSWAPD 0x00020000 /* I am kswapd */ #define PF_MEMALLOC_NOFS 0x00040000 /* All allocation requests will inherit GFP_NOFS */ #define PF_MEMALLOC_NOIO 0x00080000 /* All allocation requests will inherit GFP_NOIO */ #define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */ #define PF_KTHREAD 0x00200000 /* I am a kernel thread */ #define PF_RANDOMIZE 0x00400000 /* Randomize virtual address space */ #define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */ #define PF_MEMSTALL 0x01000000 /* Stalled due to lack of memory */ #define PF_UMH 0x02000000 /* I'm an Usermodehelper process */ #define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_mask */ #define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */ #define PF_MEMALLOC_NOCMA 0x10000000 /* All allocation request will have _GFP_MOVABLE cleared */ #define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */ #define PF_SUSPEND_TASK 0x80000000 /* This thread called freeze_processes() and should not be frozen */ /* * Only the _current_ task can read/write to tsk->flags, but other * tasks can access tsk->flags in readonly mode for example * with tsk_used_math (like during threaded core dumping). * There is however an exception to this rule during ptrace * or during fork: the ptracer task is allowed to write to the * child->flags of its traced child (same goes for fork, the parent * can write to the child->flags), because we're guaranteed the * child is not running and in turn not changing child->flags * at the same time the parent does it. */ #define clear_stopped_child_used_math(child) do { (child)->flags &= ~PF_USED_MATH; } while (0) #define set_stopped_child_used_math(child) do { (child)->flags |= PF_USED_MATH; } while (0) #define clear_used_math() clear_stopped_child_used_math(current) #define set_used_math() set_stopped_child_used_math(current) #define conditional_stopped_child_used_math(condition, child) do { (child)->flags &= ~PF_USED_MATH, (child)->flags |= (condition) ? PF_USED_MATH : 0; } while (0) #define conditional_used_math(condition) conditional_stopped_child_used_math(condition, current) #define copy_to_stopped_child_used_math(child) do { (child)->flags &= ~PF_USED_MATH, (child)->flags |= current->flags & PF_USED_MATH; } while (0) /* NOTE: this will return 0 or PF_USED_MATH, it will never return 1 */ #define tsk_used_math(p) ((p)->flags & PF_USED_MATH) #define used_math() tsk_used_math(current) static inline bool is_percpu_thread(void) { #ifdef CONFIG_SMP return (current->flags & PF_NO_SETAFFINITY) && (current->nr_cpus_allowed == 1); #else return true; #endif } /* Per-process atomic flags. */ #define PFA_NO_NEW_PRIVS 0 /* May not gain new privileges. */ #define PFA_SPREAD_PAGE 1 /* Spread page cache over cpuset */ #define PFA_SPREAD_SLAB 2 /* Spread some slab caches over cpuset */ #define PFA_SPEC_SSB_DISABLE 3 /* Speculative Store Bypass disabled */ #define PFA_SPEC_SSB_FORCE_DISABLE 4 /* Speculative Store Bypass force disabled*/ #define PFA_SPEC_IB_DISABLE 5 /* Indirect branch speculation restricted */ #define PFA_SPEC_IB_FORCE_DISABLE 6 /* Indirect branch speculation permanently restricted */ #define PFA_SPEC_SSB_NOEXEC 7 /* Speculative Store Bypass clear on execve() */ #define TASK_PFA_TEST(name, func) static inline bool task_##func(struct task_struct *p) { return test_bit(PFA_##name, &p->atomic_flags); } #define TASK_PFA_SET(name, func) static inline void task_set_##func(struct task_struct *p) { set_bit(PFA_##name, &p->atomic_flags); } #define TASK_PFA_CLEAR(name, func) static inline void task_clear_##func(struct task_struct *p) { clear_bit(PFA_##name, &p->atomic_flags); } TASK_PFA_TEST(NO_NEW_PRIVS, no_new_privs) TASK_PFA_SET(NO_NEW_PRIVS, no_new_privs) TASK_PFA_TEST(SPREAD_PAGE, spread_page) TASK_PFA_SET(SPREAD_PAGE, spread_page) TASK_PFA_CLEAR(SPREAD_PAGE, spread_page) TASK_PFA_TEST(SPREAD_SLAB, spread_slab) TASK_PFA_SET(SPREAD_SLAB, spread_slab) TASK_PFA_CLEAR(SPREAD_SLAB, spread_slab) TASK_PFA_TEST(SPEC_SSB_DISABLE, spec_ssb_disable) TASK_PFA_SET(SPEC_SSB_DISABLE, spec_ssb_disable) TASK_PFA_CLEAR(SPEC_SSB_DISABLE, spec_ssb_disable) TASK_PFA_TEST(SPEC_SSB_NOEXEC, spec_ssb_noexec) TASK_PFA_SET(SPEC_SSB_NOEXEC, spec_ssb_noexec) TASK_PFA_CLEAR(SPEC_SSB_NOEXEC, spec_ssb_noexec) TASK_PFA_TEST(SPEC_SSB_FORCE_DISABLE, spec_ssb_force_disable) TASK_PFA_SET(SPEC_SSB_FORCE_DISABLE, spec_ssb_force_disable) TASK_PFA_TEST(SPEC_IB_DISABLE, spec_ib_disable) TASK_PFA_SET(SPEC_IB_DISABLE, spec_ib_disable) TASK_PFA_CLEAR(SPEC_IB_DISABLE, spec_ib_disable) TASK_PFA_TEST(SPEC_IB_FORCE_DISABLE, spec_ib_force_disable) TASK_PFA_SET(SPEC_IB_FORCE_DISABLE, spec_ib_force_disable) static inline void current_restore_flags(unsigned long orig_flags, unsigned long flags) { current->flags &= ~flags; current->flags |= orig_flags & flags; } extern int cpuset_cpumask_can_shrink(const struct cpumask *cur, const struct cpumask *trial); extern int task_can_attach(struct task_struct *p, const struct cpumask *cs_cpus_allowed); #ifdef CONFIG_SMP extern void do_set_cpus_allowed(struct task_struct *p, const struct cpumask *new_mask); extern int set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask); #else static inline void do_set_cpus_allowed(struct task_struct *p, const struct cpumask *new_mask) { } static inline int set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask) { if (!cpumask_test_cpu(0, new_mask)) return -EINVAL; return 0; } #endif extern int yield_to(struct task_struct *p, bool preempt); extern void set_user_nice(struct task_struct *p, long nice); extern int task_prio(const struct task_struct *p); /** * task_nice - return the nice value of a given task. * @p: the task in question. * * Return: The nice value [ -20 ... 0 ... 19 ]. */ static inline int task_nice(const struct task_struct *p) { return PRIO_TO_NICE((p)->static_prio); } extern int can_nice(const struct task_struct *p, const int nice); extern int task_curr(const struct task_struct *p); extern int idle_cpu(int cpu); extern int available_idle_cpu(int cpu); extern int sched_setscheduler(struct task_struct *, int, const struct sched_param *); extern int sched_setscheduler_nocheck(struct task_struct *, int, const struct sched_param *); extern int sched_setattr(struct task_struct *, const struct sched_attr *); extern int sched_setattr_nocheck(struct task_struct *, const struct sched_attr *); extern struct task_struct *idle_task(int cpu); /** * is_idle_task - is the specified task an idle task? * @p: the task in question. * * Return: 1 if @p is an idle task. 0 otherwise. */ static inline bool is_idle_task(const struct task_struct *p) { return !!(p->flags & PF_IDLE); } extern struct task_struct *curr_task(int cpu); extern void ia64_set_curr_task(int cpu, struct task_struct *p); void yield(void); union thread_union { #ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK struct task_struct task; #endif #ifndef CONFIG_THREAD_INFO_IN_TASK struct thread_info thread_info; #endif unsigned long stack[THREAD_SIZE/sizeof(long)]; }; #ifndef CONFIG_THREAD_INFO_IN_TASK extern struct thread_info init_thread_info; #endif extern unsigned long init_stack[THREAD_SIZE / sizeof(unsigned long)]; #ifdef CONFIG_THREAD_INFO_IN_TASK static inline struct thread_info *task_thread_info(struct task_struct *task) { return &task->thread_info; } #elif !defined(__HAVE_THREAD_FUNCTIONS) # define task_thread_info(task) ((struct thread_info *)(task)->stack) #endif /* * find a task by one of its numerical ids * * find_task_by_pid_ns(): * finds a task by its pid in the specified namespace * find_task_by_vpid(): * finds a task by its virtual pid * * see also find_vpid() etc in include/linux/pid.h */ extern struct task_struct *find_task_by_vpid(pid_t nr); extern struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns); /* * find a task by its virtual pid and get the task struct */ extern struct task_struct *find_get_task_by_vpid(pid_t nr); extern int wake_up_state(struct task_struct *tsk, unsigned int state); extern int wake_up_process(struct task_struct *tsk); extern void wake_up_new_task(struct task_struct *tsk); #ifdef CONFIG_SMP extern void kick_process(struct task_struct *tsk); #else static inline void kick_process(struct task_struct *tsk) { } #endif extern void __set_task_comm(struct task_struct *tsk, const char *from, bool exec); static inline void set_task_comm(struct task_struct *tsk, const char *from) { __set_task_comm(tsk, from, false); } extern char *__get_task_comm(char *to, size_t len, struct task_struct *tsk); #define get_task_comm(buf, tsk) ({ BUILD_BUG_ON(sizeof(buf) != TASK_COMM_LEN); __get_task_comm(buf, sizeof(buf), tsk); }) #ifdef CONFIG_SMP void scheduler_ipi(void); extern unsigned long wait_task_inactive(struct task_struct *, long match_state); #else static inline void scheduler_ipi(void) { } static inline unsigned long wait_task_inactive(struct task_struct *p, long match_state) { return 1; } #endif /* * Set thread flags in other task's structures. * See asm/thread_info.h for TIF_xxxx flags available: */ static inline void set_tsk_thread_flag(struct task_struct *tsk, int flag) { set_ti_thread_flag(task_thread_info(tsk), flag); } static inline void clear_tsk_thread_flag(struct task_struct *tsk, int flag) { clear_ti_thread_flag(task_thread_info(tsk), flag); } static inline void update_tsk_thread_flag(struct task_struct *tsk, int flag, bool value) { update_ti_thread_flag(task_thread_info(tsk), flag, value); } static inline int test_and_set_tsk_thread_flag(struct task_struct *tsk, int flag) { return test_and_set_ti_thread_flag(task_thread_info(tsk), flag); } static inline int test_and_clear_tsk_thread_flag(struct task_struct *tsk, int flag) { return test_and_clear_ti_thread_flag(task_thread_info(tsk), flag); } static inline int test_tsk_thread_flag(struct task_struct *tsk, int flag) { return test_ti_thread_flag(task_thread_info(tsk), flag); } static inline void set_tsk_need_resched(struct task_struct *tsk) { set_tsk_thread_flag(tsk,TIF_NEED_RESCHED); } static inline void clear_tsk_need_resched(struct task_struct *tsk) { clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED); } static inline int test_tsk_need_resched(struct task_struct *tsk) { return unlikely(test_tsk_thread_flag(tsk,TIF_NEED_RESCHED)); } /* * cond_resched() and cond_resched_lock(): latency reduction via * explicit rescheduling in places that are safe. The return * value indicates whether a reschedule was done in fact. * cond_resched_lock() will drop the spinlock before scheduling, */ #ifndef CONFIG_PREEMPTION extern int _cond_resched(void); #else static inline int _cond_resched(void) { return 0; } #endif #define cond_resched() ({ ___might_sleep(__FILE__, __LINE__, 0); _cond_resched(); }) extern int __cond_resched_lock(spinlock_t *lock); #define cond_resched_lock(lock) ({ ___might_sleep(__FILE__, __LINE__, PREEMPT_LOCK_OFFSET); __cond_resched_lock(lock); }) static inline void cond_resched_rcu(void) { #if defined(CONFIG_DEBUG_ATOMIC_SLEEP) || !defined(CONFIG_PREEMPT_RCU) rcu_read_unlock(); cond_resched(); rcu_read_lock(); #endif } /* * Does a critical section need to be broken due to another * task waiting?: (technically does not depend on CONFIG_PREEMPTION, * but a general need for low latency) */ static inline int spin_needbreak(spinlock_t *lock) { #ifdef CONFIG_PREEMPTION return spin_is_contended(lock); #else return 0; #endif } static __always_inline bool need_resched(void) { return unlikely(tif_need_resched()); } /* * Wrappers for p->thread_info->cpu access. No-op on UP. */ #ifdef CONFIG_SMP static inline unsigned int task_cpu(const struct task_struct *p) { #ifdef CONFIG_THREAD_INFO_IN_TASK return READ_ONCE(p->cpu); #else return READ_ONCE(task_thread_info(p)->cpu); #endif } extern void set_task_cpu(struct task_struct *p, unsigned int cpu); #else static inline unsigned int task_cpu(const struct task_struct *p) { return 0; } static inline void set_task_cpu(struct task_struct *p, unsigned int cpu) { } #endif /* CONFIG_SMP */ /* * In order to reduce various lock holder preemption latencies provide an * interface to see if a vCPU is currently running or not. * * This allows us to terminate optimistic spin loops and block, analogous to * the native optimistic spin heuristic of testing if the lock owner task is * running or not. */ #ifndef vcpu_is_preempted static inline bool vcpu_is_preempted(int cpu) { return false; } #endif extern long sched_setaffinity(pid_t pid, const struct cpumask *new_mask); extern long sched_getaffinity(pid_t pid, struct cpumask *mask); #ifndef TASK_SIZE_OF #define TASK_SIZE_OF(tsk) TASK_SIZE #endif #ifdef CONFIG_RSEQ /* * Map the event mask on the user-space ABI enum rseq_cs_flags * for direct mask checks. */ enum rseq_event_mask_bits { RSEQ_EVENT_PREEMPT_BIT = RSEQ_CS_FLAG_NO_RESTART_ON_PREEMPT_BIT, RSEQ_EVENT_SIGNAL_BIT = RSEQ_CS_FLAG_NO_RESTART_ON_SIGNAL_BIT, RSEQ_EVENT_MIGRATE_BIT = RSEQ_CS_FLAG_NO_RESTART_ON_MIGRATE_BIT, }; enum rseq_event_mask { RSEQ_EVENT_PREEMPT = (1U << RSEQ_EVENT_PREEMPT_BIT), RSEQ_EVENT_SIGNAL = (1U << RSEQ_EVENT_SIGNAL_BIT), RSEQ_EVENT_MIGRATE = (1U << RSEQ_EVENT_MIGRATE_BIT), }; static inline void rseq_set_notify_resume(struct task_struct *t) { if (t->rseq) set_tsk_thread_flag(t, TIF_NOTIFY_RESUME); } void __rseq_handle_notify_resume(struct ksignal *sig, struct pt_regs *regs); static inline void rseq_handle_notify_resume(struct ksignal *ksig, struct pt_regs *regs) { if (current->rseq) __rseq_handle_notify_resume(ksig, regs); } static inline void rseq_signal_deliver(struct ksignal *ksig, struct pt_regs *regs) { preempt_disable(); __set_bit(RSEQ_EVENT_SIGNAL_BIT, ¤t->rseq_event_mask); preempt_enable(); rseq_handle_notify_resume(ksig, regs); } /* rseq_preempt() requires preemption to be disabled. */ static inline void rseq_preempt(struct task_struct *t) { __set_bit(RSEQ_EVENT_PREEMPT_BIT, &t->rseq_event_mask); rseq_set_notify_resume(t); } /* rseq_migrate() requires preemption to be disabled. */ static inline void rseq_migrate(struct task_struct *t) { __set_bit(RSEQ_EVENT_MIGRATE_BIT, &t->rseq_event_mask); rseq_set_notify_resume(t); } /* * If parent process has a registered restartable sequences area, the * child inherits. Unregister rseq for a clone with CLONE_VM set. */ static inline void rseq_fork(struct task_struct *t, unsigned long clone_flags) { if (clone_flags & CLONE_VM) { t->rseq = NULL; t->rseq_sig = 0; t->rseq_event_mask = 0; } else { t->rseq = current->rseq; t->rseq_sig = current->rseq_sig; t->rseq_event_mask = current->rseq_event_mask; } } static inline void rseq_execve(struct task_struct *t) { t->rseq = NULL; t->rseq_sig = 0; t->rseq_event_mask = 0; } #else static inline void rseq_set_notify_resume(struct task_struct *t) { } static inline void rseq_handle_notify_resume(struct ksignal *ksig, struct pt_regs *regs) { } static inline void rseq_signal_deliver(struct ksignal *ksig, struct pt_regs *regs) { } static inline void rseq_preempt(struct task_struct *t) { } static inline void rseq_migrate(struct task_struct *t) { } static inline void rseq_fork(struct task_struct *t, unsigned long clone_flags) { } static inline void rseq_execve(struct task_struct *t) { } #endif void __exit_umh(struct task_struct *tsk); static inline void exit_umh(struct task_struct *tsk) { if (unlikely(tsk->flags & PF_UMH)) __exit_umh(tsk); } #ifdef CONFIG_DEBUG_RSEQ void rseq_syscall(struct pt_regs *regs); #else static inline void rseq_syscall(struct pt_regs *regs) { } #endif const struct sched_avg *sched_trace_cfs_rq_avg(struct cfs_rq *cfs_rq); char *sched_trace_cfs_rq_path(struct cfs_rq *cfs_rq, char *str, int len); int sched_trace_cfs_rq_cpu(struct cfs_rq *cfs_rq); const struct sched_avg *sched_trace_rq_avg_rt(struct rq *rq); const struct sched_avg *sched_trace_rq_avg_dl(struct rq *rq); const struct sched_avg *sched_trace_rq_avg_irq(struct rq *rq); int sched_trace_rq_cpu(struct rq *rq); const struct cpumask *sched_trace_rd_span(struct root_domain *rd); #endif