前言
自动化好像是测试行业永恒不变的热点话题。貌似也是测试行业争议最大的话题。不知道现在还有多少言论说自动化没有用的,记得前段时间的时候网上还有不少人在争论自动化的价值和作用,但其实自动化不仅仅是存在测试行业。 现在的运维行业以及最近特别火的devops概念都是深深的依赖着自动化的。 好像我们也从没听说人家运维圈子在争论自动化有没有用。往近了说我们公司专门有运维开发来搞运维自动化, 往远了说google也有SRE团队大行其道。自动化是人家圈子里根正苗红的标配。为什么到了测试圈子里争议就这么大呢?我一直觉得这是个很奇怪的现象。大道理我就不讲了,理科男没那么多文绉绉的词汇,我只讲讲我觉得有价值的自动化是怎么个打开方式把。
注:测试圈子太大,每个领域有各自不同的情况,如有不同,欢迎探讨。
自动化的目的
节省资源。我实在想不出来有什么目的比这个还更重要的了。我一向觉得不以节省资源为目的的自动化都是耍流氓。
先说说UI自动化
误区一: UI自动化实现很简单
之所以有这么一个误区原因也很简单。UI自动化不论是selenium还是rf。平常用的API确实没多少,很好学。稍微有代码基础的人就能很快上手,并且觉得这真的很简单。 但是,实则不然。写个脚本跑起来很简单。但是按产品业务构建起一个由数百甚至数千个脚本组成的自动化测试项目就完全不是一回事了。脚本的稳定性,可维护性,可扩展性,业务上的拆分,执行的性能,报表的展示,日志的展示,异常捕获与处理,分布式运行,与数据库和各种底层存储介质的通信等等都是要考虑的。同时你还要考虑自动化最大的敌人--需求变化所带来的影响。你要从项目之初就设计好自动化项目的架构来针对这个多变性。 这要求测试人员有起码的代码设计能力。只可惜很多人用着python,用着java。可我看着都以为这是在写shell,写c。连起码的封装都做不好,我实在不觉得这是在用“面向对象的语言”。
误区二: UI自动化没用
造成这个误区的原因也很简单。技术和业务拆解能力不足就直接去搞自动化了。所以自然就没什么好效果。而且忙于在维护脚本中奔波。然后总结出了一个结论--UI自动化没有什么卵用。
正确的打开方式
- 首先,代码能力要好,代码能力要好,代码能力要好。重要的事情说三遍。好的UI自动化项目依赖于好的设计。好的代码能力不是说你会使用各种牛逼的技术,框架。而是你能设计好一个项目,该封装变化的封装变化,该抽象分层的分层,设计模式该用就用。把脚本层,数据层,基础框架层,业务层,page层等等剥离清楚。 按业务需求把各模块分割明白。 这时候要明白,我是写代码的。以一个开发的标准要求自己。
- 挑选最合适的开源框架。别装逼自己写,自己写的肯定没人家开源的做得好。除非你是大神否则别自己写。但也别一刀不动,要根据自己的需求对开源框架做二次开发。 推荐一个java系的工具链。UI工具用selenide,注意不是selenium。report框架allure,断言框架assert-core和assert-db。基础测试框架testng或junit。 UI相关的差不多就这些。别再用老旧过时的工具了,还在用原生webdriver是很痛苦的。连自旋等待机制都没有。
- 别迷恋关键字驱动,录制回放和各式测试平台。这些东西的发展就目前来说虽然逼格满满,但还无法做好自动化,它们善于降低学习成本,让没有技术能力的人能迅速做到60分,而我们这里说的是要做到90分以上。并且脚本数量一上来就是维护噩梦。公司体量没到一定程度的时候也别去自研测试平台,测试平台也不是保姆式的无脑降低学习成本,主要目的还在于标准化,自动化。
- 要与业务绑定,让技术人员只写脚本不管业务测试是大忌。先不说别的,架构都是根据业务拆分设计的,你看哪个架构师设计的时候不看业务需求直接动手的?退一步讲业务不熟练你用例都写不好。
- 标准化,我们并不是在一个人在战斗。最好要有统一的技术栈,运行环境,代码风格等等。标准化真的是好处多多。
- 理性看待UI自动化,合理运用UI自动化。它不是神,有很多东西不适合做UI自动化的别硬去做。也别因为有些东西UI自动化做的不好就否定它。
每个项目面对的情况不一样,我就不说太多了。介绍下我厂现在的情况。 6个浏览器并发一个小时基本跑完所有UI自动化。之前3个QA3天跑完所有case,现在是7个小时。现在的痛点仍然是运行速度问题。 希望今年能申请到更多的资源。
接口自动化
这个在业界比较火,各大厂测试圈子的宠儿。自从分层测试理念出现以后就开始崭露头角。成本低,速度快,效果好,运行也稳定。UI自动化中很多奇形怪状的坑在接口测试里是踩不到的。根据金字塔型的测试理念,测试人员大多都更关注这一层。 打开方式上其实与UI自动化并无太大的区别,上面说的那些该做的还是得做。还是那句话,得有代码设计能力和业务能力来支撑接口自动化。只不过接口自动化不仅仅是http接口自动化,还有各类底层协议通讯,例如一些RPC协议的接口。 广义上来说只要是对外提供服务的都是接口,不仅局限于需要网络通讯的。哪怕是个lib是个jar包,都是可以做接口测试的。 我们公司也叫模块级测试。这时候就是语言相关的东西了,不再是你想用什么语言就用什么语言,是要使用开发的语言去开发的repo里以单侧的形式编写测试代码。这时候偏底层的东西多,需要了解开发代码和架构,需要用mock。正确的打开方式参照UI吧,理念上差的不太多。工具还是推荐java的,rest-assured,其他的跟UI的工具一样
环境自动化
这部分也一直是有争议的。纠结于到底是QA来还是运维来负责这部分自动化。各家公司的观点都不一样,之前面试的时候问过很多候选人环境相关的问题,其中比较多的都是说交给运维来做的,他们最多自动化部署一个前端(app,browser)或某一个模块。很少见候选人是能独立把整个产品部署起来的,能画出产品架构图的就更少了。我比较偏向于公司内部的产品环境由QA维护,我厂也确实是这么做的。我的理由也很简单,我们的产品很偏底层,要测负载均衡,高可用,异常处理等等,经常要增减节点,kill掉各种底层服务。所以必须要对产品架构很了解。要清楚各层各模块是怎么通讯的,都负责什么任务。出了错怎么定位,去哪看日志,找哪个开发都要清楚,所以搭建环境的过程是十分有助于之后的测试工作的。同时QA负责环境自动化也是有一些好处的。
- 首先,QA更了解自己对于测试环境的需求,直接自己定制比跨部门协作效率高。
- 其次,QA是连接开发,运维,产品,售前,进场工程等职位的角色。可以说我们跟所有部门都紧密的合作着,我们是比较容易获取他们对于环境的需求。
- 最后,我现阶段倾向于QA作为一个接口输出方,交出去的就是直接可用没有坑的产品以及部署方案。把运维从这些琐碎的事情中解放出来。
到底该谁来做不争论了,各家有各家的情况。我来介绍一下我们的打开方式把。
基于docker的解决方案
现在业界要么用传统的虚拟机加shell。要不就用当前大火的docker。 我之前使用前者,现在热爱后者。下面是我厂的环境部署流程图。
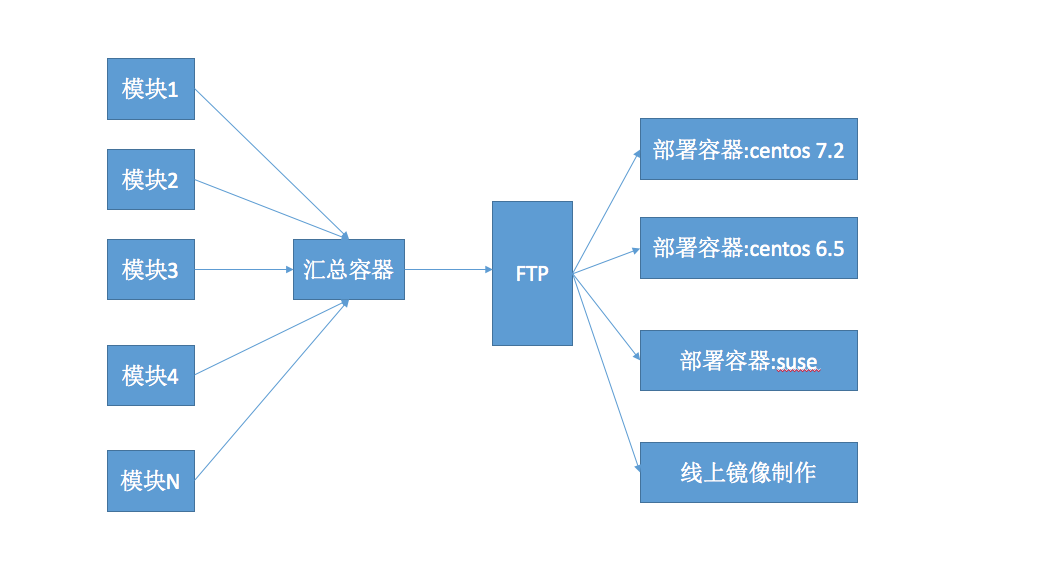
过程说明:
- 首先读取用户配置,启动N个编译容器并发编译所有模块。
- 统一发送到汇总容器,由汇总容器打成一个符合部署规范,可以直接发送给进场同学的大包。并传送到FTP服务器上。
- 根据配置挑选部署镜像(各版本的centos, ubantu, suse, redhat等),从FTP上拉取部署包进行部署。如果是线上镜像,不会部署,而是制作成一个可在线上部署的镜像。
解释一下
之所以弄成这样要解释一下,这个跟我们的业务形态耦合的很重。 由于我们是TO B的业务,而且大部分情况是进入到客户场地部署的。客户场地会出现各种限制。 例如没有网络,没有root权限,五花八门的操作系统等等。所以就衍生出了部署测试,我们也称后端兼容性测试。所以上图的右边我们的部署镜像有很多个系统版本的。这些是我们跟运维和进场工程师共同协定的标准镜像----基本就是一个官方的OS镜像加少量的工具。同时使用一个普通的没有任何额外权限的用户。目的就是测试产品对各种情况的兼容性。所以才造就了我们的部署包很大,因为依赖都打在了部署包里。 我们部署环境的时候可以选择一个镜像进行部署。
正确的打开方式
- 标准化,docker很适合做标准化。所有环境都是一样的,不会出现什么bug在这个地方能重现,那个地方复现不了的。也能让开发人员尽早发现部署上的bug,例如自己开发的时候不小心用了root权限,这样会很快发现这个bug,因为所有环境里都是没有root权限的。
- 并行化,我可以一个人起N个容器并发编译所有模块增加编译速度,也可以N个人同时起更多的容器并发的部署不同的环境。不会像以前的虚拟机一样一个人编译的时候另一个人就得等着。
- 定制化,标准化之外我们还可以定制化。为不同的角色定制化他们需要的环境。例如产品人员需求稳定可用的环境,我们给他们做蓝绿部署,服务高可用。运维人员需求一个标准镜像直接在线上部署,我们就给他做一个镜像。进场人员需求一个部署包,我们就在部署环境的过程中自动的打成一个大包(上图的汇总容器)放到FTP上,他下载直接带走。开发人员除了日常部署还需要能随时搭建一个老版本的产品(TO B业务的特性)来重现并修复一个bug,我们就对环境部署项目也做多分支策略,保留每个版本的镜像。总之我们可以针对不同的岗位为他们定制化不同的功能。
- 环境编排,当你的环境到达一定数量以后必然就会面临一个问题,一台服务器无法抗住这么多容器运行的压力。所以就会慢慢的变成2台,3台甚至更多。 这时候需要考虑很多东西,例如资源分配怎么搞,怎么确定哪些容器部署再哪个节点上。例如如果一台节点挂了怎么办?难道在它恢复正常之前这个节点上的服务就一直不可用么,是不是要加入recovery机制等等。所以这时候需要引入环境编排机制。一般无非就是在swarm,mesos,k8s,rancher上选了,一般公司没那个精力自研。只是用在测试环境上推荐docker 1.12内置的swarm mode, 之前还分别研究了mesos和k8s, 对于QA来说它们都过于复杂了,需要相当大的学习成本。以mesos来说需要各种其他插件才能正常服务,光是一个服务发现就需要安装一个mesos dns,高可用得维护ZK等等,就算你什么都没要求也得装个marathon,各种配置文件确实也让我这个非运维感觉比较棘手,想搞好它真的需要投入大量精力。而swarm mode所有的东西都已然内置,使用起来很简单方便,至于swarm mode的那些令人诟病的缺点,我们可以忽略了,这又不是生产环境。 当然了,劝告各位QA同僚。。。能不搞集群就别搞集群,能一台机器扛着就一台机器扛着。一但涉及到环境编排,那坑就多了。。。。。。 对swarm mode有兴趣的同学请看我之前发的swarm mode的科普贴
持续集成
以上介绍的所有自动化类型都是要加入到持续集成里的。 持续集成是个比较难的东西,它是对团队工程文化的一种考验,是细节的堆砌,你要把上面所说的所有自动化类型都做好,然后开发人员要写好单元测试,团队要设计好的分支模型。具体细节我就不逼逼叨了。
总结
跟大家推荐一个学习资料分享群:747981058,里面大牛已经为我们整理好了许多的学习资料,有自动化,接口,性能等等的学习资料!人生是一个逆水行舟的过程,不进则退,咱们一起加油吧!