1 性能分析
1.1 前提
性能分析的前提除了需要丰富的性能测试监控(如PTS自身的客户侧监控、基础类监控-阿里云监控、应用类监控-ARMS监控等),还需要具备相关的技术知识(包括但不限于:操作系统、中间件、数据库、开发等)。
1.2 流程
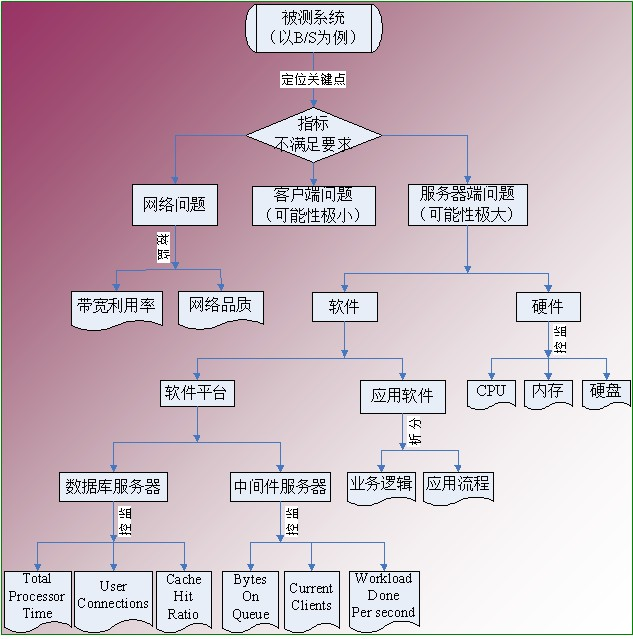
1、很多情况下压测流量并没有完全进入到后端(服务端),在网络接入层(云化的架构比如:SLB/WAF/高防IP,甚至是CDN/全站加速等)可能就会出现由于各种规格(带宽、最大连接数、新建连接数等)限制或者因为压测的某些特征符合CC和DDoS的行为而触发了防护策略导致压测结果达不到预期。
2、接着看关键指标是否满足要求,如果不满足,需要确定是哪个地方有问题,一般情况下,服务器端问题可能性比较大,也有可能是客户端问题(这种情况非常小)。
3、对于服务器端问题,需要定位的是硬件相关指标,例如CPU,Memory, Disk I/O, Network I/O, 如果是某个硬件指标有问题,需要深入的进行分析。
4、如果硬件指标都没有问题,需要查看中间件相关指标,例如:线程池、连接池、GC等,如果是这些指标问题,需要深入的 分析。
5、如果中间件相关指标没问题,需要查看数据库相关指标,例如:慢查SQL,命中率,锁、参数设置。
6、如果以上指标都正常,应用程序的算法、缓冲、缓存、同步或异步可能有问题,需要具体深入的分析。
具体如下图所示:
1.3 可能瓶颈点
1.3.1 硬件/规格上的瓶颈一般指的是CPU、内存、磁盘I/O 方面的问题,分为服务器硬件瓶颈、网络瓶颈(对局域网可以不考虑)。
1.3.2 中间件上的性能瓶颈
一般指的是应用服务器、web 服务器等应用软件,还包括数据库系统。例如:中间件weblogic 平台上配置的JDBC连接池的参数设置不合理,造成的瓶颈。
1.3.3 应用程序上的性能瓶颈
一般指的是开发人员开发出来的应用程序。例如,JVM参数不合理,容器配置不合理,慢SQL(可使用阿里云APM类产品如ARMS协助定位),数据库设计不合理,程序架构规划不合理,程序本身设计有问题(串行处理、请求的处理线程不够、无缓冲、无缓存、生产者和消费者不协调等)
,造成系统在大量用户方位时性能低下而造成的瓶颈。
,造成系统在大量用户方位时性能低下而造成的瓶颈。
1.3.4 操作系统上的性能瓶颈
一般指的是windows、UNIX、Linux等操作系统。例如,在进行性能测试,出现物理内存不足时,虚拟内存设置也不合理,虚拟内存的交换效率就会大大降低,从而导致行为的响应时间大大增加,这时认为操作系统上出现性能瓶颈。
1.3.5 网络设备上的性能瓶颈
一般指的是防火墙、动态负载均衡器、交换机等设备。当前更多的云化服务架构使用的网络接入产品:包括但不限于SLB/WAF/高防IP/CDN/全站加速等等。例如,在动态负载均衡器上设置了动态分发负载的机制,当发现某个应用服务器上的硬件资源已经到达极限时,动态负载均衡器将后续的交易请求发送到其他负载较轻的应用服务器上。在测试时发现,动态负载均衡器没有起到相应的作用,这时可以认为网络瓶颈。
1.4 方法
1.4.1 CPU
CPU资源利用率很高的话,需要看CPU消耗User,Sys,Wait那种状态下。
如果CPU User非常高,需要查看消耗在哪个进程,可以用top(linux)命令看出,接着用top –H –p
<pid>看哪个线程消耗资源高,如果是java应用,就可以用jstack看出此线程正在执行的堆栈,看资源消耗在哪个方法上,查看源代码就知道问题所在;如果是c++应用,可以用gprof性能工具进行分析。
如果CPU Sys非常高,可以用strace(linux)看系统调用的资源消耗及时间。
如果CPU Wait非常高,考虑磁盘读写了,可以通过减少日志输出、异步或换速度快的硬盘。
1.4.2 Memory
操作系统未了最大化利用内存,一般都设置大量的cache,因此,内存利用率高达99%并不是问题,内存的问题主要看某个进程占用的内存是否非常大以及是否有大量的swap(虚拟内存交换)。
1.4.3 磁盘I/O
磁盘I/O一个最显著的指标是繁忙率,可以通过减少日志输出、异步或换速度快的硬盘。
1.4.4 网络I/O
网络I/O主要考虑传输内容大小,不能超过硬件网络传输的最大值70%,可以通过压缩、减少内容大小、在本地设置缓存以及分多次传输等。
1.4.5 内核参数
内核参数一般都有默认值,这些内核参数默认值对于一般系统没问题,但是对于压力测试来说,可能运行的参数将会超过内核参数,导致系统出现问题,可以用sysctl来查看及修改。
1.4.6 JVM
jvm主要分析GC/FULL
GC是否频繁,以及垃圾回收的时间,可以用jstat命令来查看,对于每个代大小以及GC频繁,通过jmap将内存dump,再借助工具HeapAnalyzer 来分析哪地方占用的内存较高以及是否有内存泄漏可能。简单点可以使用APM工具,比如阿里云ARMS,下同。
1.4.7 线程池
如果线程不够用,可以通过参数调整,增加线程;对于线程池中的线程设置比较大的情况,还是不够用可能的原因是:某个线程被阻塞来不及释放
,可能在等锁、方法耗时较长、数据库等待时间很长等原因导致,需要进一步分析才能定位。
1.4.8 JDBC连接池
连接池不够用的情况下,可以通过参数进行调整增加;但是对于数据库本身处理很慢的情况下,调整没有多大的效果,需要查看数据库方面以及因代码导致连接未释放的原因。
1.4.9 SQL
SQL效率低下也是导致性能差的一个非常重要的原因,可以通过查看执行计划看SQL慢在哪里,一般情况,SQL效率低下原因主要有:
|
类别 |
子类 |
表达式或描述 |
原因 |
|
索引 |
未建索引 |
|
产生全表扫描 |
|
未利用索引 |
substring(card_no,1,4)=′5378′ |
产生全表扫描 |
|
|
amount/30< 1000 |
产生全表扫描 |
||
|
convert(char(10),date,112)=′19991201′ |
产生全表扫描 |
||
|
where salary<>3000 |
产生全表扫描 |
||
|
name like ‘%张’ |
产生全表扫描 |
||
|
first_name + last_name =’beill cliton’ |
产生全表扫描 |
||
|
id_no in(′0′,′1′) |
产生全表扫描 |
||
|
select id from t where num=@num |
有参数也会产生全表扫描 |
||
|
使用效能低的索引 |
oder by 非聚族索引 |
索引性能低 |
|
|
username=’张三’ and age>20 |
字符串索引低于整形索引 |
||
|
表中列与空NULL值 |
索引性能低 |
||
|
尽量不要使用IS NULL或IS NOT NULL |
索引性能低 |
||
|
数据量 |
所有数据量 |
select * |
很多列产生大量数据 |
|
select id,name |
表中有几百万行,产生大量数据 |
||
|
嵌套查询 |
先不过滤数据,后过滤数据 |
产生大量无用的数据 |
|
|
关联查询 |
多表进行关联查询,先过滤掉小部分数据,在过滤大部分数据 |
大量关联操作 |
|
|
大数据量插入 |
一次次插入 |
产生大量日志,消耗资源 |
|
|
锁 |
锁等待 |
update account set banlance=100 where id=10 |
产生表级锁,将会锁住整个表 |
|
死锁 |
A:update a;update b;B:update b;update a; |
将会产生死锁 |
|
|
游标 |
Cursor Open cursor,fetch;close cursor |
性能很低 |
|
|
临时表 |
create tmp table 创建临时表 |
产生大量日志 |
|
|
drop table |
删除临时表 |
需要显示删除,避免系统表长时间锁定 |
|
|
其他 |
exist 代替 IN |
select num from a where num in(select num from b) |
in会逐个判断,exist有一条就结束 |
|
exist 代替select count(*) |
判断记录是否存在 |
count(*)将累加计算,exist有就结束 |
|
|
between 代替 IN |
ID in(1,2,3) |
IN逐个判断,between是范围判断 |
|
|
left outer join 代替Not IN |
select ID from a where ID not in(select b.Mainid from b) |
NOT IN逐个判断,效率非常低 |
|
|
union all 代替union |
select ID from a union select id from b union |
删除重复的行,可能会在磁盘进行排序而union all只是简单的将结果并在一起 |
|
|
常用SQL尽量用绑定变量方法 |
insert into A(ID) values(1) |
直接写SQL每次都要编译,用绑定变量的方法只编译一次, |
2 调优
2.1 调优步骤
2.1.1 确定问题
应用程序代码:在通常情况下,很多程序的性能问题都是写出来的,因此对于发现瓶颈的模块,应该首先检查一下代码。数据库配置:经常引起整个系统运行缓慢,一些诸如大型数据库都是需要DBA进行正确的参数调整才能投产的。操作系统配置:不合理就可能引起系统瓶颈。硬件设置:硬盘速度、内存大小等都是容易引起瓶颈的原因,因此这些都是分析的重点。网络:网络负载过重导致网络冲突和网络延迟。
2.1.2 分析问题
当确定了问题之后,我们要明确这个问题影响的是响应时间吞吐量,还是其他问题?是多数用户还是少数用户遇到了问题?如果是少数用户,这几个用户与其它用户的操作有什么不用?系统资源监控的结果是否正常?CPU的使用是否到达极限?I/O 情况如何?问题是否集中在某一类模块中?是客户端还是服务器出现问题? 系统硬件配置是否够用?实际负载是否超过了系统的负载能力?是否未对系统进行优化?通过这些分析及一些与系统相关的问题,可以对系统瓶颈有更深入的了解,进而分析出真正的原因。
2.1.3 确定调整目标和解决方案高系统吞吐量,缩短响应时间,更好地支持并发。
2.1.4 测试解决方案
对通过解决方案调优后的系统进行基准测试。(基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试)。
2.1.5 分析调优结果
系统调优是否达到或者超出了预定目标?系统是整体性能得到了改善,还是以系统某部分性能来解决其他问题。调优是否可以结束了。最后,如果达到了预期目标,调优工作可以先告一段落。
2.2 调优注意事项
在应用系统的设计开发过程中,应始终把性能放在考虑的范围内,将性能测试常态化,日常化的内网的性能测试+定期的真实环境的业务性能测试,PTS都可以支持。
确定清晰明确的性能目标是关键,进而将目标转化为PTS中的压测场景并设置好需要的目标量级,然后视情况选择并发/TPS模式,自动递增/手工调速的组合进行流量控制。必须保证调优后的程序运行正确。
系统的性能更大程度上取决于良好的设计,调优技巧只是一个辅助手段。
调优过程是迭代渐进的过程,每一次调优的结果都要反馈到后续的代码开发中去。
性能调优不能以牺牲代码的可读性和可维护性为代价