在Java数组,变量和对象中存储数据是暂时的,为保证永久地保存数据,就需要将其保存在硬盘文件中,Java的I/O技术就可以将数据保存为硬盘的文本文件。在了解“流”之前,我们需要先来看什么是计算机的内存和硬盘。
内存是电脑的数据存储设备之一,用来存放正在运行的程序和数据,可直接与运算器及控制器交换信息。内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来。硬盘是计算机重要的外部存储设备,计算机的操作系统、应用软件、文档、数据等,都可以存放在硬盘上。
知道了内存和硬盘的区别,来看“流”的概念。
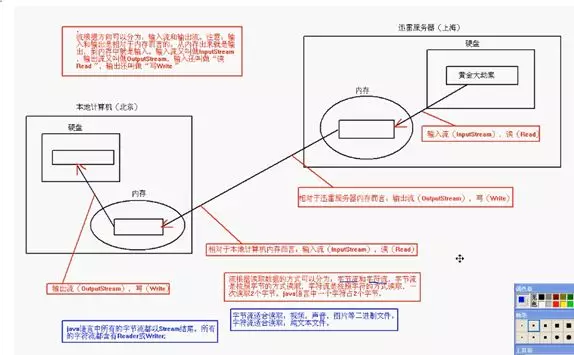
上面这幅图展示了我们平常下载东西的过程。相对于内存而言,“流”根据方向可以分为输入流和输出流,输入流是进入内存的方向,输出流是离开内存的方向。根据读取数据的格式,可以将内存分为字节流和字符流,字节流是按字节方式读取数据的,通常用来读取图片,声音,视频等二进制文件,而字符流是按字符格式进行读取数据的,可以用来读取纯文本文件,比如我们电脑上的txt文件,像doc文档是有格式的,是非纯文本文件,就需要使用字节流来进行读取。
Java中处理这些输入输出的类都放在java.io包中,所有的输入类都是字节输入类(InputStream)和字符输入类(Reader)的子类,而所有的输出类都是字节输出类(OutputStream)和字符输出类(Writer)的子类。
我们需要重点掌握的主要有以下16个类:
文件读写字节流字符流
FileInputStream
FileOutputStream
FileReader
FileWriter
带缓存的读写字节流字符流
BufferedReader
BufferedWriter
BufferedInputStream
BufferedOutputStream
专门处理数据的字节流字符流
DataInputStream
DataOutputStream
读取对象的字节流字符流
ObjectInputStream
ObjectOutputStream
转换流(字节流转换成字符流)
InputStreamReader
OutputStreamWriter
PrintWriter
PrintStream(标准的输出流,默认输出到控制台)
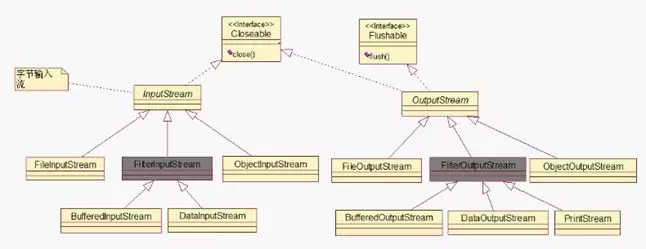
Java输入输出流主要有InputStream,OutputStream, Reader和Writer四大类,下面通过这两张图来了解这四类中的子类的继承关系。

接下来看InputStream类的基本读取方法。看以下代码:
import java.io.*;
public class FileInputStreamTest01{
public static void main(String[] args){
FileInputStream fis=null;
try{
//要读取一个文件,先要给这个文件创建一个输入流
//文件路径
String filepath="abc.txt"; // 绝对路径
//String filepath="F:\bianchenglianxi\java\abc.txt"; // 相对路径
fis=new FileInputStream(filepath);
//读取文件
int i1=fis.read();
int i2=fis.read();
int i3=fis.read();
int i4=fis.read();
int i5=fis.read();
int i6=fis.read();
int i7=fis.read();
System.out.println(i1);
System.out.println(i2);
System.out.println(i3);
System.out.println(i4);
System.out.println(i5);
System.out.println(i6);
System.out.println(i7);
}catch(FileNotFoundException e){
e.printStackTrace();
s}
catch(IOException e){
e.printStackTrace();
}finally{
if(fis!=null){
try{
fis.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
}编译运行后输出:
/*
97
98
99
100
101
102
103
*/1.先导入包java.io.*;
2.要读取一个文件,先要给这个文件创建一个输入流,即FileInputStream fis=new FileInputStream(filepath); 其中filepath是要读入的文件所在的路径,可以是绝对路径,也可以是相对路径。
3.使用read()方法读取文件。
4.处理异常时要注意,IOException的范围比FileNotFoundException的范围大,所以前者要写在后面,或者直接catch IOException即可。
5.最后使用close()方法关闭文件。
以上就是基本的读取文件的方法。看第二个程序,直接使用throws抛出异常。
import java.io.*;
public class FileInputStreamTest02{
public static void main(String[] args) throws Exception{
FileInputStream fis=new FileInputStream("abc.txt");
while(true){
int temp=fis.read();
if(temp==-1)break;
System.out.println(temp);
}
fis.read();
}
}以上程序使用while循环读取文件,因为是一个字节一个字节进行读取,所以存在缺点,频繁地访问磁盘,伤害磁盘,并且访问效率低。接下来看使用数组读取文件的方法,看以下代码:
import java.io.*;
public class FileInputStreamTest03{
public static void main(String[] args)throws Exception{
FileInputStream fis=new FileInputStream("abc.txt");
byte[] bytes=new byte[3];//每一次最多读取三个字节
//int read(byte[] bytes); 该方法返回的int类型的值代表的是这次读取了多少个字节
int i1=fis.read(bytes);
//将bytes数组转换成字符串
System.out.println(new String(bytes)); //abc
int i2=fis.read(bytes);
System.out.println(new String(bytes)); //def
int i3=fis.read(bytes);
System.out.println(new String(bytes,0,i3)); //gef
System.out.println(i1); //3
System.out.println(i2); //3
System.out.println(i3); //1
fis.close();
}
}编译运行后输出:
/*
abc
def
g
3
3
1
*/1.数组读取的方法为int read(byte[] bytes),读取之前在内存中准备一个数组,每次读取多个字节存储到byte数组中。
2.byte[] bytes=new byte[3]; 设置数组的大小,每次最多读取三个字节。
3.int i1=fis.read(bytes); System.out.println(new String(bytes)); 将文件中的内容按字节读取到数组中后,再将bytes数组转换成字符串。
最后升级一下,看循环读取文件内容,代码如下:
/*
循环读取
*/
import java.io.*;
public class FileInputStreamTest04{
public static void main(String[] args)throws Exception{
FileInputStream fis=new FileInputStream("abc.txt");
byte[] bytes=new byte[1024];
while(true){
int temp=fis.read(bytes);
if(temp==-1)break;
System.out.print(new String(bytes,0,temp));
}
fis.close();
}
}编译运行后输出:
//abcdefg