文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
1.背景
在上一篇博客中我提到了格网编码的两个优点:
- 将两个整形(地理)字段的查询变成了一个整形字段的查询
- 通过合理的划分格网可以将多个条件查询(左上、右下构成的四个查询条件)优化成多数情况下的一个查询条件(等于一个格网编码)
但是,实际项目上,这种优化效果明显吗?
2.实际测试
2.1以不同大小的表测试
- 通过构造范围查询 SQL
select * from tc_geo_address a where a.coordinate_x>504625 and a.coordinate_x<504825 and a.coordinate_y>309858 and a.coordinate_y<310058- 通过地理编码查询 SQL
select * from tc_geo_address a where a.grid_code=3300000110其中coordinate_x和coordinate_y以及grid_code上都建立了索引 对比结果:
| 表大小 | 范围查询 | 单个编码查询 |
|---|---|---|
| 2K条 | 0.002S | 0.002S |
| 17W条 | 1.08S | 0.84S |
2.2总结
- 只有表足够大时,单编码查询才有优势
- 当多个地理编码组成组合查询时,效率可能会比范围查询低
3.缓存优化(当查询表内容固定,如兴趣点查询)
3.1为什么可以开启查询缓存?
- 格网编码的原理:将地图进行网格切分,在地图范围、切割大小一定的情况下,格网的个数是固定。
- 格网查询的原理:针对查询的XY和范围构造出其覆盖的所有格网编码,最后依然变成了以格网编码的查询。
- 结论:虽然XY坐标是无法做缓存的(不断变化),但是其解析对应的格网编码是固定的,每一次格网编码所对应的查询结果也是固定的。所以我们可以对格网编码查询后的结果进行缓存。
3.2方案实现
3.2.1网格查询结果缓存
为了提高缓存命中度,我们以单个格网编码为主键进行缓存:
/***
* 通过传入网格编码进行搜索,提供缓存功能
* @param gridcodefield
* @param gridcode
* @return
*/
@Cacheable(value="cacheOneHour",key="'getaddcode'+#gridcode+#gridcodefield")
public List<GeoAddress> getAddressBySingleCode(String gridcodefield,String gridcode){
try{
if(gridcodefield.equals("")){
gridcodefield="Grid_Code";
}
String sql=gisConfigManager.getSQL("GeoCode.GeoCodeReverseGridCode");
sql+=" where "+gridcodefield+"="+gridcode;
return jdbcTemplate.query(sql,new Object[]{},new DataRowMapper(GeoAddress.class));
}catch(Exception e){
return null;
}
}3.2.2查询范围分块格网请求
List<Long> searchResult=GridCodeUtils.GridCodeSearch(OperConst.MapBounds.get(0),
OperConst.MapBounds.get(1), x, y, gridsize, gridsize, radius);
if(searchResult==null){
LogUtils.error("查询地理编码结果为空!", logger,null);
return null;
}
//分开利用code查询是为了充分制造缓存命中
for(int i=0;i<searchResult.size();i++){
List<GeoAddress> temAddList=cacheManager.getAddressBySingleCode(gridHashField,searchResult.get(i).toString());
if(temAddList!=null&&temAddList.size()>0){
list.addAll(temAddList);
}
}4.如果附带属性查询条件?(当表内容固定)
以上仅仅是根据坐标去进行过滤查询。如果附带上对查询结果的进一步条件筛选呢? 这类情况分几种情况进行讨论。
4.1过滤条件十分固定——纳入缓存
比如:查询条件永远都是离目前范围500M的视频。
那么针对编码查询时一样可以纳入缓存机制中。
4.2过滤条件常态化变动
4.2.1格网(无属性过滤)对应的查询结果不多——先格网查询缓存、再过滤结果
比如:查询条件会不断变化,可能是500M内的视频,可能是500M内的井盖等等。可以先进行格网编码查询并缓存,再对查询结果依据查询条件进行过滤:
//因为address经常变化,不利于缓存,所以用代码进行过滤
if(address!=""){//查询条件过滤
List<GeoAddress> addlist=new ArrayList<GeoAddress>();
for(int i=0;i<list.size();i++){
GeoAddress addressObj=list.get(i);
if(addressObj.getAddress().contains(address)){
addlist.add(addressObj);
}
}
}4.2.1格网(无属性过滤)对应的查询结果十分多
- 查询表可以重构:将大表改成小表,使得格网查询结果变少,那么以上方案依然可用。
- 查询表无法重构:实时sql查询。
5.当查询表内容不断更新
此时缓存机制可能导致数据不是最新的,依然需sql进行查询。
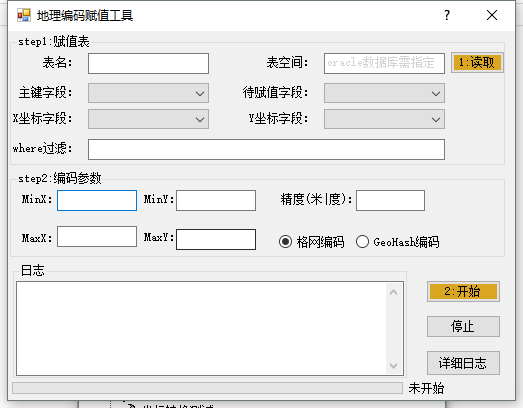
6.辅助编码工具
当我们想使用编码机制而存入的数据只有XY没有编码值时,这里我们针对性开发了一个地理编码赋值工具:
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^
