@
一、Oracle索引简介
在看《收获,不止SQL优化》一书,并根据书中例子进行实践,整理成笔记
1.1 索引分类
Oracle索引分为BTree索引、位图索引、反向索引、函数索引、全文索引等等。
1.2 索引数据结构
Oracle索引中最常用的是BTree索引,所以就以BTree索引为例,讲一下BTree索引,BTree索引数据结构是一种二叉树的结构,索引由根块(Root)、茎块(Branch)、叶子块(Leaf)组成,其中叶子块主要存储索引列具体值(Key Column Value)以及能定位到数据块具体位置的Rowid,茎块和根块主要保存对应下级对应索引
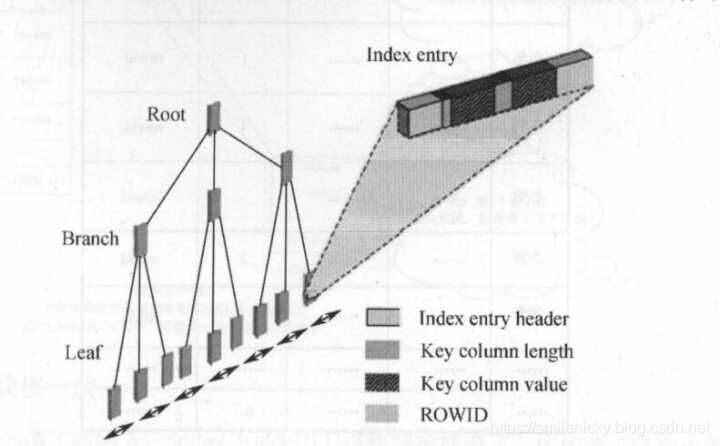
1.3 索引特性
索引特性:
- 索引本身是有序的
- 索引本身能存储列值
1.4 索引使用注意要点
- (1)、仅等值无范围查询时,组合的顺序不影晌性能
drop table t purge;
create table t as select * from dba objects;
update t set object_id=rownum ;
commit;
create index idx_id_type on t(object_id, object_type) ;
create index idx_type_id on t(object_type , object_id) ;
set autotrace off;
alter session set statistics_level=all ;
select /*+index(t idx_id_type)*/ * from t where object_id=20 and object_type='TABLE';
select * from table(dbms_xplan.display cursor(null , null , 'allstats last'));
select /*+index(t,idx_type id)*/ * from t where object_id=20 and object_type= 'TABLE';
select * from table(dbms_xplan.display cursor(null , null , 'allstats last'));
- (2)、范围查询时,组合索引最佳顺序一般是将等值查询的列置前
select /*+index (t, idx_id_type)*/ * from t where object_id>=20 and object_id<2000 and
object_type='TABLE';
select /*+index (t , idx_type_id) */ * from t where object_id>=20 and object_id<2000
and object type='TABLE';
- (3)、Oracle不能同时在索引根的两段寻找最大值和最小值
set autotrace on
select max(object_id) , min(object_id) from t;
笛卡尔乘积写法:
set autotrace on
select max, min
from (select max(object_id) max from t ) a ,
(select min(object_id) min from t ) b;
- (4)、索引最新的数据块一般是在最右边
1.5、索引的缺点
- 热快竞争:索引最新的数据块一般在最右边,而访问也一般是访问比较新的数据,所以容易造成热快竞争
- 更新新增问题:索引本身是有序的,所以查询时候很快,但是更新时候就麻烦了,新增更新索引都需要保证排序
1.6、索引失效
索引失效分为逻辑失效和物理失效
- 逻辑失效
逻辑失效是因为一些sql语法导致索引失效,比如加了一些函数,而索引列不是函数索引 - 物理失效
物理失效是真的失效,比如被设置unusable属性,分区表的不规范操作也会导致索引失效等等情况
alter index index_name unusable;
二、索引分类介绍
索引分类:BTree索引、位图索引、函数索引、反向索引、全文索引
2.1、位图索引
位图索引:位图索引储存的就是比特值
环境准备,位图索引性质适用于count时,效率最高
drop table t purge;
create table t as select * from dba_objects;
update t set object_id = rownum;
commit;
不用索引的情况:
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
72016
执行计划
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 288 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 86565 | 288 (1)| 00:00:04 |
-------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
1111 consistent gets
0 physical reads
0 redo size
432 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
创建位图索引:
create bitmap index idx_bitm_t_status on t(status);
再次查询,走位图索引查询:
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
72016
执行计划
----------------------------------------------------------
Plan hash value: 4272013625
--------------------------------------------------------------------------------
-----------
| Id | Operation | Name | Rows | Cost (%CPU)|
Time |
--------------------------------------------------------------------------------
-----------
| 0 | SELECT STATEMENT | | 1 | 5 (0)|
00:00:01 |
| 1 | SORT AGGREGATE | | 1 | |
|
| 2 | BITMAP CONVERSION COUNT | | 86565 | 5 (0)|
00:00:01 |
| 3 | BITMAP INDEX FAST FULL SCAN| IDX_BITM_T_STATUS | | |
|
--------------------------------------------------------------------------------
-----------
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
432 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
注意要点:
位图索引更新列容易造成死锁,所以查询比较多列才适合建位图索引,更新比较多的列就尽量不要建索引
1.2、函数索引
函数索引:就是将一个函数计算的结果存储在行的列中
环境准备:
drop table t purge;
create table t (id int, status varchar2(2));
insert into t select 1,'N' from dual;
insert into t select rownum ,'Y' from dual connect by rownum <1000;
commit;
不走索引的查询:
SQL> set autotrace on
SQL> select * from t where (case when status='N' then 'No' end)='No';
ID STAT
---------- ----
1 N
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 1 | 16 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(CASE "STATUS" WHEN 'N' THEN 'No' END ='No')
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
486 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
创建函数索引:
create index idx_status on t (case when status ='N' then 'No' end);
走函数索引的查询:
SQL> select * from t where (case when status='N' then 'No' end)='No';
ID STAT
---------- ----
1 N
执行计划
----------------------------------------------------------
Plan hash value: 3908194542
--------------------------------------------------------------------------------
----------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
Time |
--------------------------------------------------------------------------------
----------
| 0 | SELECT STATEMENT | | 10 | 200 | 2 (0)|
00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 10 | 200 | 2 (0)|
00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_STATUS | 4 | | 1 (0)|
00:00:01 |
--------------------------------------------------------------------------------
----------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(CASE "STATUS" WHEN 'N' THEN 'No' END ='No')
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
486 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
注意要点:
自定义函数时要加上deterministic 关键字,不然不能建立函数索引
建立一个自定义函数:
create or replace function f_addusl(i int) return int is
begin
return(i + 1);
end;
尝试建立函数索引:
create index idx_ljb_test on t(f_addusl(id));
提示:ORA-30553:函数不能确定
用deterministic 关键字,就可以建立函数索引
create or replace function f_addusl(i int) return int deterministic is
begin
return(i + 1);
end;
在自定义函数代码更新时,对应的函数索引也要重建,否则不能用到原来的函数索引
1.3、反向索引
反向索引:反向索引其实也是BTree索引的一种特例,不过在列中字节会反转的(反向索引是为了避免热快竞争,比如索引列中存储的列值是递增的,比如250101,250102,按照BTree索引的特性,一般是按照顺序存储在索引右边的,所以容易形成热快竞争,而反向索引可以避免这种情况,因为反向索引是这样存储的,比如101052,201052,这样列值就距离很远了,避免了热快竞争)
反向索引不能用到范围查询
SQL> set autotrace on
SQL> select * from t where created=sysdate;
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 913247507
--------------------------------------------------------------------------------
---------------
| Id | Operation | Name | Rows | Bytes | Cost (%C
PU)| Time |
--------------------------------------------------------------------------------
---------------
| 0 | SELECT STATEMENT | | 12 | 2484 | 286
(0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 12 | 2484 | 286
(0)| 00:00:04 |
|* 2 | INDEX RANGE SCAN | IDX_REV_CREATED | 346 | | 1
(0)| 00:00:01 |
--------------------------------------------------------------------------------
---------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CREATED"=SYSDATE@!)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
1191 bytes sent via SQL*Net to client
408 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL>
范围查询,发现不走反向索引查询
SQL> select * from t where created>= sysdate-10 and created <= sysdate-1;
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
SYS
ICOL$
20
2 TABLE 15-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
1
SYS
I_USER1
46
46 INDEX 14-6月 -19
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
02-4月 -10 2010-04-02:13:18:38 VALID N N N
4
SYS
CON$
28
28 TABLE 13-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
1
SYS
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
UNDO$
15
15 TABLE 12-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
1
SYS
C_COBJ#
29
29 CLUSTER 11-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
5
SYS
I_OBJ#
3
3 INDEX 10-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
4
SYS
PROXY_ROLE_DATA$
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
25
25 TABLE 09-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
1
SYS
I_IND1
41
41 INDEX 08-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
4
OWNER
------------------------------------------------------------
OBJECT_NAME
--------------------------------------------------------------------------------
SUBOBJECT_NAME OBJECT_ID
------------------------------------------------------------ ----------
DATA_OBJECT_ID OBJECT_TYPE CREATED
-------------- -------------------------------------- --------------
LAST_DDL_TIME TIMESTAMP STATUS TE GE SE
-------------- -------------------------------------- -------------- -- -- --
NAMESPACE EDITION_NAME
---------- ------------------------------------------------------------
SYS
I_CDEF2
54
54 INDEX 07-6月 -19
02-4月 -10 2010-04-02:13:18:38 VALID N N N
4
已选择9行。
执行计划
----------------------------------------------------------
Plan hash value: 1322348184
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 2484 | 292 (2)| 00:00:04 |
|* 1 | FILTER | | | | | |
|* 2 | TABLE ACCESS FULL| T | 12 | 2484 | 292 (2)| 00:00:04 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(SYSDATE@!-10<=SYSDATE@!-1)
2 - filter("CREATED">=SYSDATE@!-10 AND "CREATED"<=SYSDATE@!-1)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
1112 consistent gets
0 physical reads
0 redo size
1770 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
9 rows processed
SQL>
1.4、全文索引
全文索引:所谓Oracle全文索引是通过Oracle词法分析器(lexer)将所有的表意单元term存储dr$开头的表里并存储term出现的位置、次数、hash值等等信息,Oracle提供了basic_lexer(针对英语)、chinese_vgram_lexer(汉语分析器)、chinese_lexer(新的汉语分析器)。
- basic_lexer:是一种适用于英文的分析器,根据空格或者标点符号将词元分离,不管对于中文来说是没有空格的,所以这种分析器不适合中文
- chinese_vgram_lexer:这是一种原先专门的中文分析器,支持所有的汉字字符集,比如zhs16gbk单点。这种分析器,分析过程是按字为单元进行分析的,举个例子,“索引本身是有序的”,按照这种分析器,会分成词元“索”、“索引”、“引本”、“本身”、“身是”、“是有”、“有序”、“序的”、“的”这些词元,然后你发现像“序的”这些词在中文中基本是不成立的,不过这种Oracle分析器本身就不认识中文,所以只能全部分析,很明显效率是不好的
- chinese_lexer:这是一种新的中文分析器,前面提到chinese_vgram_lexer这种分析器虽然支持所有的中文字符集,但是效率不高,所以chinese_lexer是对其的改进版本,这种分析器认识很多中文词汇,能够比较快查询,提高效率,不过这种分析器只能支持utf-8字符集
Oracle的全文索引具体可以采用通配符查找、模糊匹配、相关分类、近似查找、条件加权和词意扩充等方法
环境准备
drop table t purge;
create table t as select * from dba_objects where object_name is not null;
update t set object_name ='高兴' where rownum<=2;
commit;
select * from t where object_name like '%高兴%';
设置词法分析器
//设置词法分析器
BEGIN
ctx_ddl.create_preference ('lexer1', 'chinese_vgram_lexer');
END;
解锁ctxsys用户,同时给你的测试账号(我这里用scott)授权使用ctx_ddl
//解锁ctxsys用户同时授权
grant ctxapp to scott;
alter user ctxsys account unlock;
alter user ctxsys identified by ctxsys;
connect ctxsys/ctxsys;
grant execute on ctx_ddl to scott;
connect scott/11;
建立全文索引
//删除全文索引
drop index idx_content;
//查看数据文件信息
select * from v$datafile;
//建立全文索引
CREATE INDEX idx_content ON t(object_name) indextype is ctxsys.context parameters('lexer lexer1');
注意要点:更新数据时候记得执行全文索引同步命令,否则将看不到更新数据
exec ctx_ddl.sync_index('idx_content','20M');