前言
explian/desc可以帮助我们分析sql语句,写出高效sql语句,让mysql查询优化器可以更好的工作。
mysql查询优化器会尽可能的使用索引,优化器排除的数据行越多,mysql找到匹配数据行就越快。
用法
explain/desc + sql
explain select * from tbl_chain_bill where billid = 6

| key | value | means |
|---|---|---|
| id | 1 | 查询序列号 |
| select_type | SIMPLE | 查询类型 |
| table | tbl_chain_bill | 表或派生表名 |
| type | const | 扫描类型 |
| possible_keys | PRIMARY | 可能用的索引,有多个 |
| key | PRIMARY | 实际使用索引 |
| key_len | 8 | 使用的索引长度,在不损失精度下,长度越短越好 |
| ref | const | 显示索引的哪一列被使用了 |
| rows | 1 | 该语句扫描了多少行记录 |
| Extra | (Null) | sql语句额外信息,如排序分组等 |
分析
id:表示执行select子句顺序的标识。id相同,顺序由上至下;id越大,越先执行。
select_type
- SIMPLE:简单SELECT,不使用UNION或子查询等;
- PRIMARY:查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY;
- UNION:UNION中的第二个或后面的SELECT语句;
- UNION RESULT:UNION的结果;
- SUBQUERY:子查询中的第一个SELECT;
- DERIVED:派生表的SELECT,FROM子句的子查询;
- UNCACHEABLE SUBQUERY:结果集不能缓存的子查询。
table:表示数据来源于哪张表或派生表。

type:从上到下,性能由差到好
- ALL:从头到尾全表扫描;
- Index:全索引树扫描,只遍历索引树;
- Range:只检索给定的范围,需要使用一个索引来选择行,key代表使用的索引;
- Ref:用于连接匹配的索引列不唯一时,如where bill.billNo = billDetail.billNo;
- Eq ref:用于连接匹配的索引列是unique或者primary key时,如where bill.id = billDetail.billID;
- const:用常数来比较primary key时吗,比如where primary key = 123;
- system:被查询表只有一行记录,用常数来比较primary key时。
extra:extra 中出现以下 2 项意味着 MYSQL 根本不能使用索引,效率会受到重大影响,应尽可能对此进行优化。
Using filesort 表示 MySQL会对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容。可能在内存或者磁盘上进行排序。
Using temporary 表示 MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
测试说明
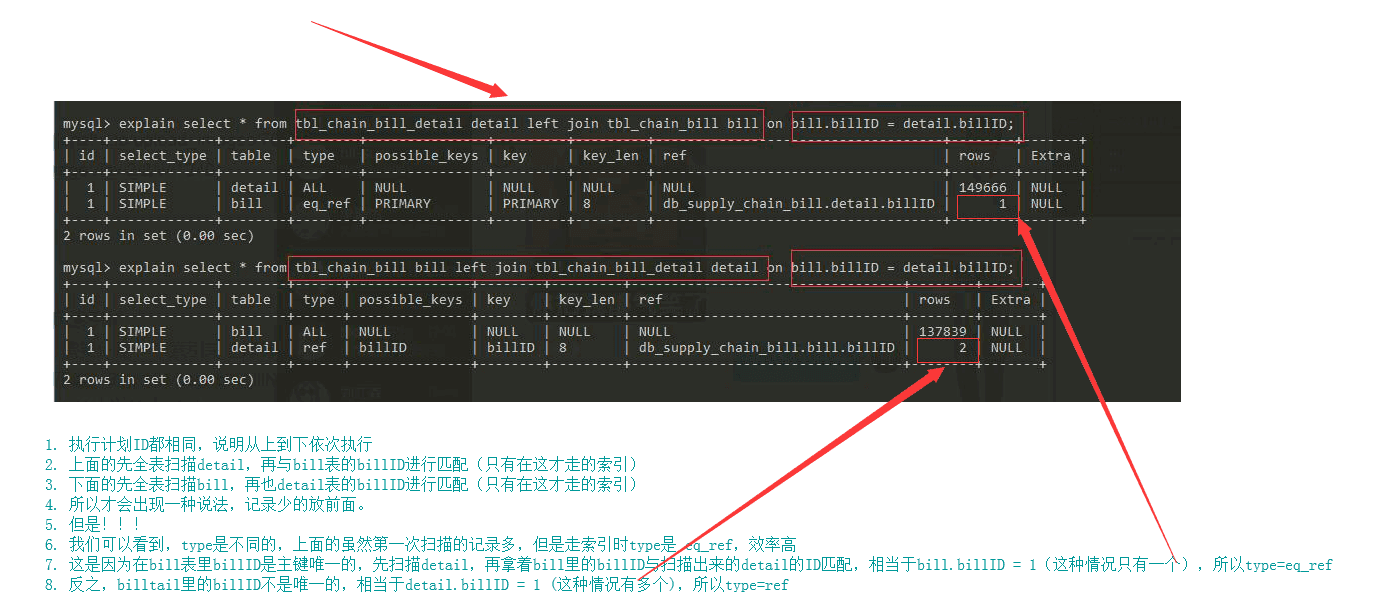
需要指出的是,上面例子关于type=ref或者eq_ref是因为唯一索引的存在,如果连接条件没有唯一性约束,那么还是记录少的放在连接查询的左边。