参考文献:
《深入浅出DPDK》
DPDK官网
https://software.intel.com/en-us/articles/introduction-to-the-data-plane-development-kit-dpdk-packet-framework
...........................................................................................................
这一部分属于DPDK核心部分了, 对于一个报文的整个生命周期,如何从对接运营商的外部接口进入路由器,再连接计算机的网卡,发送的过程,或许这就是我们所疑惑的,也是此次学习的重点部分,只有弄清楚每个步骤每个环节,或许才能彻底弄懂网络报文处理,然后解决其中出现的问题
一. DPDK网络处理模块划分
网络报文的处理转发主要分为硬件部分和软件处理部分,由一下几个模块构成:
- packet input
- pre-processing:对报文进行粗粒度处理
- input classification:对报文进行细粒度分流
- ingress queuing:提供基于描述符的队列FIFO
- delivery/scheduling:根据队列优先级和CPU状态进行调度
- accelerator:提供加解密和压缩/解压缩等硬件功能
- egress queuing:在出口根据QoS等级进行调度
- post processing:后期报文处理释放缓存
- packet output:从硬件发送出去

图1
如图一所示,浅色和阴影部分都是对应模块和硬件相关的,所以提升这部分性能最佳的选择是尽量多的选择网卡上的或设备芯片提供的网络特定功能相关的卸载的特性,深色软件部分可以通过提高算法的效率和结合CPU相关的并行指令来提升网络性能,了解网络处理模块的基本组成部分后,我们再来看看不同的转发框架如何让这些模块协同工作完成网络包的处理的
二. 转发框架介绍
传统的Network Process (专用网络处理器)转发的模型可以分为run to comletion(运行至终结, RTC)模型和pipeline (流水线)模型
2.1 流水线模型(pipeline)
pipeline 借鉴与工业上的流水线模型,将整个功能拆分成多个独立的阶段,不同阶段通过队列传递产品。这样对于一些CPU密集和I/O密集的应用,将I/O密集的操作放在另一个微处理器引擎上执行。通过过滤器可以分为不同的操作分配不同的线程,通过队列匹配两个速度,达到最好的并发,
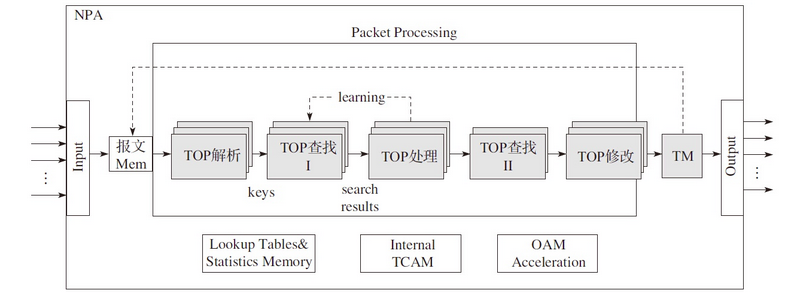
我们可以看到图中,TOP(Task Optimized Processor)单元,每个TOP单元都是对特定的事物进行优化处理的特殊微单元
2.2 run to completion 模型
这个模型是DPDK针对一般的程序的运行方法,一个程序分为几个不同的逻辑功能,几个逻辑功能会在一个CPU的核上运行,我们下面看下模型的视图
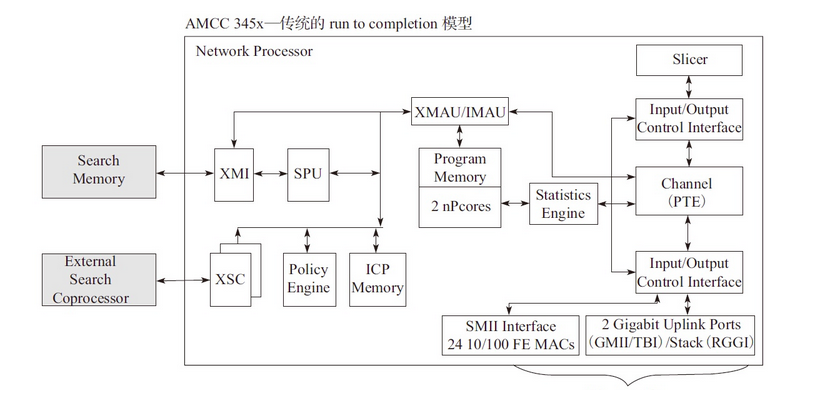
这个模型没有对报文特殊处理的的运算单元,只有两个NP核, 两个NP核利用已烧录的微码进行报文处理
2.3 转发模型对比
从run to completion的模型中,我们可以清楚地看出,每个IA的物理核都负责处理整个报文的生命周期从RX到TX,这点非常类似前面所提到的AMCC的nP核的作用。在pipeline模型中可以看出,报文的处理被划分成不同的逻辑功能单元A、B、C,一个报文需分别经历A、B、C三个阶段,这三个阶段的功能单元可以不止一个并且可以分布在不同的物理核上,不同的功能单元可以分布在相同的核上(也可以分布在不同的核上),从这一点可以看出,其对于模块的分类和调用比EZchip的硬件方案更加灵活。

两个的优缺点:

三. 转发算法
除了良好的转发框架之外,转发中很重要的一部分内容就是对于报文字段的匹配和识别,在DPDK中主要用到了精确匹配(Exact Match)算法和最长前缀匹配(Longest Prefix Matching,LPM)算法来进行报文的匹配从而获得相应的信息。精确匹配主要需要解决两个问题:进行数据的签名(哈希),解决哈希的冲突问题,DPDK中主要支持CRC32和J hash。
最长前缀匹配(Longest Prefix Matching,LPM)算法是指在IP协议中被路由器用于在路由表中进行选择的一个算法。当前DPDK使用的LPM算法就利用内存的消耗来换取LPM查找的性能提升。当查找表条目的前缀长度小于24位时,只需要一次访存就能找到下一条,根据概率统计,这是占较大概率的,当前缀大于24位时,则需要两次访存,但是这种情况是小概率事件。
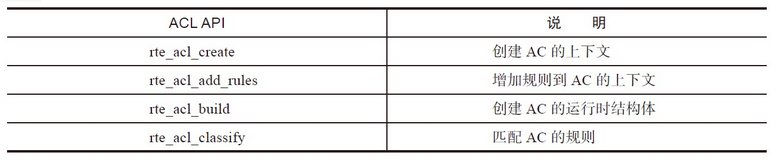
ACL库利用N元组的匹配规则去进行类型匹配,提供以下基本操作:
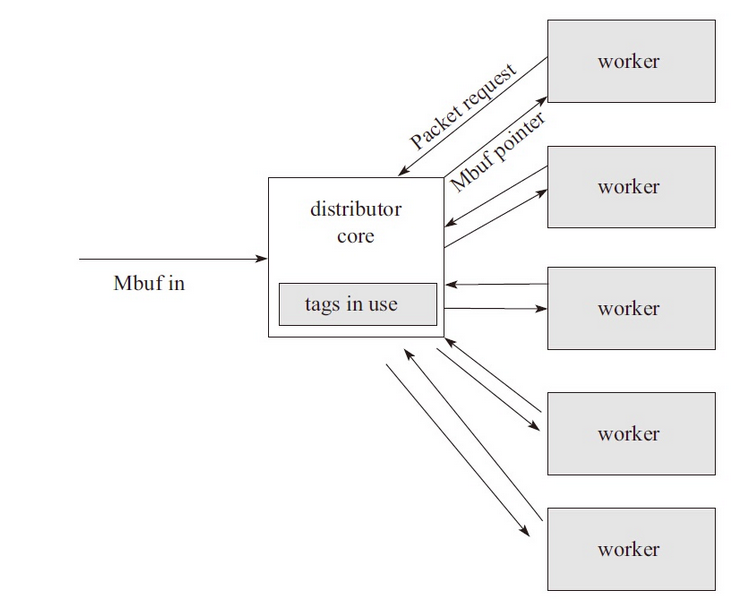
Packet distributor(报文分发)是DPDK提供给用户的一个用于包分发的API库,用于进行包分发。主要功能可以用下图进行描述:
四. 示例(参考英特尔网站:https://software.intel.com/en-us/articles/introduction-to-the-data-plane-development-kit-dpdk-packet-framework)
ip_pipline应用通过提供几个示例应用和配置文件,展示了流水线模块的使用方法
下图展示了三层转发配置应用
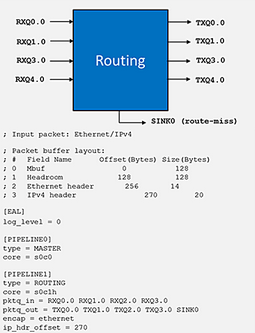
在这一示例中,它设置了简单的路由。
“core” 条目线程ID(socket ID,物理CPU ID和超线程ID)确定了用来运行流水线的CPU核。
“pktq_in” 和 “pktq_out”参数定义了数据包传输的接口,这里指接受和传送数据包。
可以将“encap”参数设置为“ethernet”, “qinq”或“mpls”,用来为所有出站包封装合适的包头。
最后一个参数”ip_hdr_offset”可用于设置DPDK数据包结构(mbuf)中ip-header的起始位置所需偏移字节
下图是ip_pipeline的脚本文件,该文件中的内容将作为路由表项加入到路由流水线的最长匹配表中:
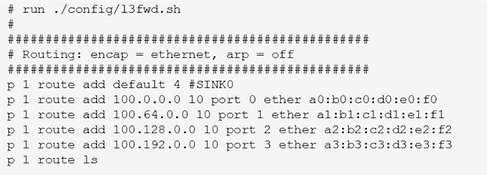
p <pipeline_id> route add <ip_addr> <depth> port <port_id> ether <next hop mac_addr>
可使用以下命令来运行L3转发应用:
$./build/ip_pipeline -f l3fwd.cfg -p 0xf -s l3fwd.sh
有时,应用程序在不同的功能模块之间进行互联时具有复杂的拓扑结构, 一旦应用程序配置文件准备就绪,请运行以下命令生成拓扑图
$./diagram-generator.py -f <configuration file>
ip_pipeline示例程序生成的拓扑图:

各种使用此标准流水线模型构建的网络功能(流水线)都可作为DPDK ip_pipeline示例应用程序的一部分.
DPDK支持pipeline 的有以下几种:
1)Packet I/O
2)Flow classification
3)Firewall
4)Routing
5)Metering
6)Traffic Mgmt
下面以官l2转发实例来看下整体代码如何运行的:
源码下载:http://core.dpdk.org/download/
代码路径:dpdk/examples/l2fwd
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <stdint.h> 5 #include <inttypes.h> 6 #include <sys/types.h> 7 #include <sys/queue.h> 8 #include <netinet/in.h> 9 #include <setjmp.h> 10 #include <stdarg.h> 11 #include <ctype.h> 12 #include <errno.h> 13 #include <getopt.h> 14 #include <signal.h> 15 #include <stdbool.h> 16 17 #include <rte_common.h> 18 #include <rte_log.h> 19 #include <rte_malloc.h> 20 #include <rte_memory.h> 21 #include <rte_memcpy.h> 22 #include <rte_memzone.h> 23 #include <rte_eal.h> 24 #include <rte_per_lcore.h> 25 #include <rte_launch.h> 26 #include <rte_atomic.h> 27 #include <rte_cycles.h> 28 #include <rte_prefetch.h> 29 #include <rte_lcore.h> 30 #include <rte_per_lcore.h> 31 #include <rte_branch_prediction.h> 32 #include <rte_interrupts.h> 33 #include <rte_pci.h> 34 #include <rte_random.h> 35 #include <rte_debug.h> 36 #include <rte_ether.h> 37 #include <rte_ethdev.h> 38 #include <rte_mempool.h> 39 #include <rte_mbuf.h> 40 41 static volatile bool force_quit; 42 43 /* MAC updating enabled by default */ 44 static int mac_updating = 1; 45 46 #define RTE_LOGTYPE_L2FWD RTE_LOGTYPE_USER1 47 48 #define NB_MBUF 8192 49 50 #define MAX_PKT_BURST 32 51 #define BURST_TX_DRAIN_US 100 /* TX drain every ~100us */ 52 #define MEMPOOL_CACHE_SIZE 256 53 54 /* 55 * Configurable number of RX/TX ring descriptors 56 */ 57 #define RTE_TEST_RX_DESC_DEFAULT 128 58 #define RTE_TEST_TX_DESC_DEFAULT 512 59 static uint16_t nb_rxd = RTE_TEST_RX_DESC_DEFAULT; 60 static uint16_t nb_txd = RTE_TEST_TX_DESC_DEFAULT; 61 62 /* ethernet addresses of ports */ 63 //端口的以太网地址 64 static struct ether_addr l2fwd_ports_eth_addr[RTE_MAX_ETHPORTS]; 65 66 /* mask of enabled ports */ 67 //启用端口的mask 68 static uint32_t l2fwd_enabled_port_mask = 0; 69 70 /* list of enabled ports */ 71 //启用端口列表 72 static uint32_t l2fwd_dst_ports[RTE_MAX_ETHPORTS]; 73 74 static unsigned int l2fwd_rx_queue_per_lcore = 1; 75 76 #define MAX_RX_QUEUE_PER_LCORE 16 77 #define MAX_TX_QUEUE_PER_PORT 16 78 struct lcore_queue_conf { 79 unsigned n_rx_port; 80 unsigned rx_port_list[MAX_RX_QUEUE_PER_LCORE]; 81 } __rte_cache_aligned; 82 struct lcore_queue_conf lcore_queue_conf[RTE_MAX_LCORE]; 83 84 static struct rte_eth_dev_tx_buffer *tx_buffer[RTE_MAX_ETHPORTS]; 85 86 static const struct rte_eth_conf port_conf = { 87 .rxmode = { 88 .split_hdr_size = 0, 89 .header_split = 0, /**< Header Split disabled */ //报头分离 90 .hw_ip_checksum = 0, /**< IP checksum offload disabled */ //IP校验和卸载 91 .hw_vlan_filter = 0, /**< VLAN filtering disabled */ //vlan过滤 92 .jumbo_frame = 0, /**< Jumbo Frame Support disabled */ //巨星帧的支持 93 .hw_strip_crc = 0, /**< CRC stripped by hardware */ //使用硬件清除CRC 94 }, 95 .txmode = { 96 .mq_mode = ETH_MQ_TX_NONE, 97 }, 98 }; 99 100 struct rte_mempool * l2fwd_pktmbuf_pool = NULL; 101 102 /* Per-port statistics struct */ 103 struct l2fwd_port_statistics { 104 uint64_t tx; 105 uint64_t rx; 106 uint64_t dropped; 107 } __rte_cache_aligned; 108 struct l2fwd_port_statistics port_statistics[RTE_MAX_ETHPORTS]; 109 110 #define MAX_TIMER_PERIOD 86400 /* 1 day max */ 111 /* A tsc-based timer responsible for triggering statistics printout */ 112 static uint64_t timer_period = 10; /* default period is 10 seconds */ 113 114 /* Print out statistics on packets dropped */ 115 //打印的属性跳过。。 116 static void 117 print_stats(void) 118 { 119 uint64_t total_packets_dropped, total_packets_tx, total_packets_rx; 120 unsigned portid; 121 122 total_packets_dropped = 0; 123 total_packets_tx = 0; 124 total_packets_rx = 0; 125 126 const char clr[] = { 27, '[', '2', 'J', '�' }; 127 const char topLeft[] = { 27, '[', '1', ';', '1', 'H','�' }; 128 129 /* Clear screen and move to top left */ 130 printf("%s%s", clr, topLeft); 131 132 printf(" Port statistics ===================================="); 133 134 for (portid = 0; portid < RTE_MAX_ETHPORTS; portid++) { 135 /* skip disabled ports */ 136 if ((l2fwd_enabled_port_mask & (1 << portid)) == 0) 137 continue; 138 printf(" Statistics for port %u ------------------------------" 139 " Packets sent: %24"PRIu64 140 " Packets received: %20"PRIu64 141 " Packets dropped: %21"PRIu64, 142 portid, 143 port_statistics[portid].tx, 144 port_statistics[portid].rx, 145 port_statistics[portid].dropped); 146 147 total_packets_dropped += port_statistics[portid].dropped; 148 total_packets_tx += port_statistics[portid].tx; 149 total_packets_rx += port_statistics[portid].rx; 150 } 151 printf(" Aggregate statistics ===============================" 152 " Total packets sent: %18"PRIu64 153 " Total packets received: %14"PRIu64 154 " Total packets dropped: %15"PRIu64, 155 total_packets_tx, 156 total_packets_rx, 157 total_packets_dropped); 158 printf(" ==================================================== "); 159 } 160 161 static void 162 l2fwd_mac_updating(struct rte_mbuf *m, unsigned dest_portid) 163 { 164 struct ether_hdr *eth; 165 void *tmp; 166 167 eth = rte_pktmbuf_mtod(m, struct ether_hdr *); 168 169 /* 02:00:00:00:00:xx */ 170 tmp = ð->d_addr.addr_bytes[0]; 171 *((uint64_t *)tmp) = 0x000000000002 + ((uint64_t)dest_portid << 40); 172 173 /* src addr */ 174 ether_addr_copy(&l2fwd_ports_eth_addr[dest_portid], ð->s_addr); 175 } 176 177 //处理收到的数据包 178 static void 179 l2fwd_simple_forward(struct rte_mbuf *m, unsigned portid) 180 { 181 unsigned dst_port; 182 int sent; 183 struct rte_eth_dev_tx_buffer *buffer; 184 185 //获取目的端口ID 186 dst_port = l2fwd_dst_ports[portid]; 187 188 //更新MAC地址 189 if (mac_updating) 190 l2fwd_mac_updating(m, dst_port); 191 192 //获取目的端口的 tx 缓存 193 buffer = tx_buffer[dst_port]; 194 //发送数据包,到目的端口的tx缓存 195 sent = rte_eth_tx_buffer(dst_port, 0, buffer, m); 196 197 if (sent) 198 port_statistics[dst_port].tx += sent; //如果发包成功,发包计数+1 199 } 200 201 /* main processing loop */ 202 static void 203 l2fwd_main_loop(void) 204 { 205 struct rte_mbuf *pkts_burst[MAX_PKT_BURST]; 206 struct rte_mbuf *m; 207 int sent; 208 unsigned lcore_id; 209 uint64_t prev_tsc, diff_tsc, cur_tsc, timer_tsc; 210 unsigned i, j, portid, nb_rx; 211 struct lcore_queue_conf *qconf; 212 const uint64_t drain_tsc = (rte_get_tsc_hz() + US_PER_S - 1) / US_PER_S * 213 BURST_TX_DRAIN_US; 214 struct rte_eth_dev_tx_buffer *buffer; 215 216 prev_tsc = 0; 217 timer_tsc = 0; 218 219 //获取当前核心的ID 220 lcore_id = rte_lcore_id(); 221 //获取当前核心的配置 222 qconf = &lcore_queue_conf[lcore_id]; 223 224 //如果 rx_port的个数为0,则 记录日志。(其实是出错了) 225 if (qconf->n_rx_port == 0) { 226 RTE_LOG(INFO, L2FWD, "lcore %u has nothing to do ", lcore_id); 227 return; 228 } 229 230 //记录日志, 231 RTE_LOG(INFO, L2FWD, "entering main loop on lcore %u ", lcore_id); 232 233 //遍历所有的port 234 for (i = 0; i < qconf->n_rx_port; i++) { 235 //获取到portID 236 portid = qconf->rx_port_list[i]; 237 //记录日志 238 RTE_LOG(INFO, L2FWD, " -- lcoreid=%u portid=%u ", lcore_id, 239 portid); 240 241 } 242 243 //如果没超时(最开始设置的那个二层转发的运行时间) 244 while (!force_quit) { 245 246 //获取时间戳 247 cur_tsc = rte_rdtsc(); 248 249 /* 250 * TX burst queue drain 251 */ 252 //对比时间戳 253 diff_tsc = cur_tsc - prev_tsc; 254 if (unlikely(diff_tsc > drain_tsc)) { 255 256 for (i = 0; i < qconf->n_rx_port; i++) { 257 //获得portid和buffer 258 portid = l2fwd_dst_ports[qconf->rx_port_list[i]]; 259 buffer = tx_buffer[portid]; 260 261 //把buffer中的数据发送到portid对应的port 262 sent = rte_eth_tx_buffer_flush(portid, 0, buffer); 263 if (sent) 264 port_statistics[portid].tx += sent; //如果发包成功,发包计数+1 265 266 } 267 268 /* if timer is enabled */ 269 //如果计时器开启 270 if (timer_period > 0) { 271 272 /* advance the timer */ 273 //调整计时器 274 timer_tsc += diff_tsc; 275 276 /* if timer has reached its timeout */ 277 //如果计时器超时 278 if (unlikely(timer_tsc >= timer_period)) { 279 280 /* do this only on master core */ 281 //主线程打印一些属性,仅有主线程会执行print_stats 282 if (lcore_id == rte_get_master_lcore()) { 283 print_stats(); //打印属性, 284 /* reset the timer */ 285 timer_tsc = 0; //设置计时器为0 286 } 287 } 288 } 289 290 prev_tsc = cur_tsc; 291 } 292 293 /* 294 * Read packet from RX queues //收包模块 295 */ 296 for (i = 0; i < qconf->n_rx_port; i++) { 297 //获取portID 298 portid = qconf->rx_port_list[i]; 299 //从portID对应的Port收到nb_rx个包 300 nb_rx = rte_eth_rx_burst((uint8_t) portid, 0, 301 pkts_burst, MAX_PKT_BURST); 302 303 port_statistics[portid].rx += nb_rx; //收包计数+=nb_rx 304 305 for (j = 0; j < nb_rx; j++) { //遍历收到的包 306 m = pkts_burst[j]; 307 rte_prefetch0(rte_pktmbuf_mtod(m, void *)); //预取到pktmbuf 308 l2fwd_simple_forward(m, portid); //调用函数,处理收到的包 309 } 310 } 311 } 312 } 313 314 //__attribute__((unused))表示可能没有这个参数,编译器不会报错 315 static int 316 l2fwd_launch_one_lcore(__attribute__((unused)) void *dummy) 317 { 318 l2fwd_main_loop(); //二层转发主要循环 319 return 0; 320 } 321 322 /* display usage */ 323 static void 324 l2fwd_usage(const char *prgname) 325 { 326 printf("%s [EAL options] -- -p PORTMASK [-q NQ] " 327 " -p PORTMASK: hexadecimal bitmask of ports to configure " 328 " -q NQ: number of queue (=ports) per lcore (default is 1) " 329 " -T PERIOD: statistics will be refreshed each PERIOD seconds (0 to disable, 10 default, 86400 maximum) " 330 " --[no-]mac-updating: Enable or disable MAC addresses updating (enabled by default) " 331 " When enabled: " 332 " - The source MAC address is replaced by the TX port MAC address " 333 " - The destination MAC address is replaced by 02:00:00:00:00:TX_PORT_ID ", 334 prgname); 335 } 336 337 static int 338 l2fwd_parse_portmask(const char *portmask) 339 { 340 char *end = NULL; 341 unsigned long pm; 342 343 /* parse hexadecimal string */ 344 //解析十六进制字符串,将十六进制字符串转换为unsigned long 345 pm = strtoul(portmask, &end, 16); 346 if ((portmask[0] == '�') || (end == NULL) || (*end != '�')) 347 return -1; 348 349 if (pm == 0) 350 return -1; 351 352 return pm; 353 } 354 355 static unsigned int 356 l2fwd_parse_nqueue(const char *q_arg) 357 { 358 char *end = NULL; 359 unsigned long n; 360 361 /* parse hexadecimal string */ 362 n = strtoul(q_arg, &end, 10); 363 if ((q_arg[0] == '�') || (end == NULL) || (*end != '�')) 364 return 0; 365 if (n == 0) 366 return 0; 367 if (n >= MAX_RX_QUEUE_PER_LCORE) 368 return 0; 369 370 return n; 371 } 372 373 static int 374 l2fwd_parse_timer_period(const char *q_arg) 375 { 376 char *end = NULL; 377 int n; 378 379 /* parse number string */ 380 n = strtol(q_arg, &end, 10); 381 if ((q_arg[0] == '�') || (end == NULL) || (*end != '�')) 382 return -1; 383 if (n >= MAX_TIMER_PERIOD) 384 return -1; 385 386 return n; 387 } 388 389 //解析命令行参数 390 /* Parse the argument given in the command line of the application */ 391 static int 392 l2fwd_parse_args(int argc, char **argv) 393 { 394 int opt, ret, timer_secs; 395 char **argvopt; 396 int option_index; 397 char *prgname = argv[0]; 398 static struct option lgopts[] = { 399 { "mac-updating", no_argument, &mac_updating, 1}, 400 { "no-mac-updating", no_argument, &mac_updating, 0}, 401 {NULL, 0, 0, 0} 402 }; 403 404 argvopt = argv; //复制argv指针 405 406 //解析命令行,getopt_long()可以解析命令行参数 407 while ((opt = getopt_long(argc, argvopt, "p:q:T:", 408 lgopts, &option_index)) != EOF) { 409 410 //命令行有三个参数, p:portmask,n:nqueue,T:timer period 411 switch (opt) { 412 /* portmask */ 413 //port的个数,以十六进制表示的,如0x0f表示15 414 case 'p': 415 //l2fwd_parse_portmask()函数为自定义函数 416 //把十六进制的mask字符串转换成unsigned long。 417 //端口使能情况 418 l2fwd_enabled_port_mask = l2fwd_parse_portmask(optarg); 419 if (l2fwd_enabled_port_mask == 0) { //mask为0表示出错 420 printf("invalid portmask "); 421 l2fwd_usage(prgname); //打印用户选项,类似于 --help 422 return -1; //参数传递错误,会返回-1,其结果是退出程序 423 } 424 break; 425 426 /* nqueue */ 427 //队列的个数,同样也是用十六进制字符串表示的。 428 case 'q': 429 //每个核心配置几个 rx 队列。 430 l2fwd_rx_queue_per_lcore = l2fwd_parse_nqueue(optarg); 431 if (l2fwd_rx_queue_per_lcore == 0) { //lcore 0表示出错 432 printf("invalid queue number "); 433 l2fwd_usage(prgname); 434 return -1; //返回-1,其结果是退出程序。 435 } 436 break; 437 438 /* timer period */ //定时器周期 439 440 case 'T': 441 //配置定时器周期,单位为秒 442 //即l2fwd运行多少秒,使用十六进制表示的。 443 timer_secs = l2fwd_parse_timer_period(optarg); 444 if (timer_secs < 0) { 445 printf("invalid timer period "); 446 l2fwd_usage(prgname); 447 return -1; 448 } 449 //timer_period表示二层转发测试时间,默认为10秒,可通过-T来调节时间 450 timer_period = timer_secs; 451 break; 452 453 /* long options */ 454 //--打头的选项不处理 455 case 0: 456 break; 457 458 default: 459 //参数传递错误,打印--help 460 l2fwd_usage(prgname); 461 return -1; 462 } 463 } 464 465 if (optind >= 0) 466 argv[optind-1] = prgname; 467 468 ret = optind-1; 469 optind = 0; /* reset getopt lib */ 470 return ret; 471 } 472 473 /* Check the link status of all ports in up to 9s, and print them finally */ 474 static void 475 check_all_ports_link_status(uint8_t port_num, uint32_t port_mask) 476 { 477 #define CHECK_INTERVAL 100 /* 100ms */ 478 #define MAX_CHECK_TIME 90 /* 9s (90 * 100ms) in total */ 479 uint8_t portid, count, all_ports_up, print_flag = 0; 480 struct rte_eth_link link; 481 482 printf(" Checking link status"); 483 fflush(stdout); 484 for (count = 0; count <= MAX_CHECK_TIME; count++) { 485 if (force_quit) 486 return; 487 all_ports_up = 1; 488 for (portid = 0; portid < port_num; portid++) { 489 if (force_quit) 490 return; 491 if ((port_mask & (1 << portid)) == 0) 492 continue; 493 memset(&link, 0, sizeof(link)); 494 rte_eth_link_get_nowait(portid, &link); 495 /* print link status if flag set */ 496 if (print_flag == 1) { 497 if (link.link_status) 498 printf("Port %d Link Up - speed %u " 499 "Mbps - %s ", (uint8_t)portid, 500 (unsigned)link.link_speed, 501 (link.link_duplex == ETH_LINK_FULL_DUPLEX) ? 502 ("full-duplex") : ("half-duplex ")); 503 else 504 printf("Port %d Link Down ", 505 (uint8_t)portid); 506 continue; 507 } 508 /* clear all_ports_up flag if any link down */ 509 if (link.link_status == ETH_LINK_DOWN) { 510 all_ports_up = 0; 511 break; 512 } 513 } 514 /* after finally printing all link status, get out */ 515 if (print_flag == 1) 516 break; 517 518 if (all_ports_up == 0) { 519 printf("."); 520 fflush(stdout); 521 rte_delay_ms(CHECK_INTERVAL); 522 } 523 524 /* set the print_flag if all ports up or timeout */ 525 if (all_ports_up == 1 || count == (MAX_CHECK_TIME - 1)) { 526 print_flag = 1; 527 printf("done "); 528 } 529 } 530 } 531 532 static void 533 signal_handler(int signum) 534 { 535 if (signum == SIGINT || signum == SIGTERM) { 536 printf(" Signal %d received, preparing to exit... ", 537 signum); 538 force_quit = true; //强制退出按钮为真 539 } 540 } 541 542 int 543 main(int argc, char **argv) 544 { 545 /* 546 //程序前面自定义的结构 547 // __rte_cache_aligned 是一个宏,表示内存对其 548 struct lcore_queue_conf { 549 unsigned n_rx_port; //rx_port个数 550 unsigned rx_port_list[MAX_RX_QUEUE_PER_LCORE]; //rx_port列表 551 } __rte_cache_aligned; 552 struct lcore_queue_conf lcore_queue_conf[RTE_MAX_LCORE]; 553 //一个计算机,包含多个核心,一个核心处理多个rx_port 554 */ 555 struct lcore_queue_conf *qconf; 556 557 558 struct rte_eth_dev_info dev_info; //设备信息 559 int ret; //返回值 560 uint8_t nb_ports; //总port个数 561 uint8_t nb_ports_available; //可用port个数 562 uint8_t portid, last_port; //当前portid,前一个portid。 563 unsigned lcore_id, rx_lcore_id; //核心id,rx_lcore_id 564 unsigned nb_ports_in_mask = 0; //?? 565 566 /* init EAL */ 567 //初始化环境 568 ret = rte_eal_init(argc, argv); 569 if (ret < 0) 570 rte_exit(EXIT_FAILURE, "Invalid EAL arguments "); 571 argc -= ret; //??未知,貌似没用,不明所以 572 argv += ret; //??未知,貌似没用,不明所以 573 574 force_quit = false; //强制推出按钮为假 575 //当捕获到SIGINT或SIGTERM信号时,强制推出按钮为真,详见signal_handler 576 //signal_handler为自定义函数 577 signal(SIGINT, signal_handler); //信号捕获处理1 578 signal(SIGTERM, signal_handler); //信号捕获处理2 579 580 /* parse application arguments (after the EAL ones) */ 581 //解析传参(必须在eal_init之后),此为自定义函数,详见函数定义 582 ret = l2fwd_parse_args(argc, argv); 583 if (ret < 0) 584 rte_exit(EXIT_FAILURE, "Invalid L2FWD arguments "); 585 586 printf("MAC updating %s ", mac_updating ? "enabled" : "disabled"); 587 588 /* convert to number of cycles */ 589 //获取定时器的时钟周期 590 timer_period *= rte_get_timer_hz(); 591 592 /* create the mbuf pool */ 593 //创建缓存池,用于存储数据包。 594 l2fwd_pktmbuf_pool = rte_pktmbuf_pool_create("mbuf_pool", NB_MBUF, 595 MEMPOOL_CACHE_SIZE, 0, RTE_MBUF_DEFAULT_BUF_SIZE, 596 rte_socket_id()); 597 if (l2fwd_pktmbuf_pool == NULL) 598 rte_exit(EXIT_FAILURE, "Cannot init mbuf pool "); 599 600 //获取Eth口的个数 601 nb_ports = rte_eth_dev_count(); 602 if (nb_ports == 0) 603 rte_exit(EXIT_FAILURE, "No Ethernet ports - bye "); 604 605 /* reset l2fwd_dst_ports */ 606 //复位(清0)目的端口,此代码块作用是初始化l2fwd_dst_ports 607 //个人认为写的比较low 608 for (portid = 0; portid < RTE_MAX_ETHPORTS; portid++) 609 l2fwd_dst_ports[portid] = 0; 610 last_port = 0; 611 612 /* 613 * Each logical core is assigned a dedicated TX queue on each port. 614 */ 615 //设置每个 port 接收的数据包要 转发 到的目的port。 616 for (portid = 0; portid < nb_ports; portid++) { 617 /* skip ports that are not enabled */ 618 //跳过没使能的端口 619 if ((l2fwd_enabled_port_mask & (1 << portid)) == 0) 620 continue; 621 622 //每两个port为一对,互相作二层转发 623 //单数发到单数+1,双数发到双数-1 624 if (nb_ports_in_mask % 2) { 625 l2fwd_dst_ports[portid] = last_port; 626 l2fwd_dst_ports[last_port] = portid; 627 } 628 else 629 last_port = portid; //对last_port赋值。 630 631 nb_ports_in_mask++; //对标记 ++ 632 633 rte_eth_dev_info_get(portid, &dev_info); //获取对应portid的dev信息 634 } 635 //如果剩下一个网口,则该网口自己转发给自己 636 if (nb_ports_in_mask % 2) { 637 printf("Notice: odd number of ports in portmask. "); 638 l2fwd_dst_ports[last_port] = last_port; 639 } 640 641 rx_lcore_id = 0; 642 qconf = NULL; 643 644 //初始化每个核心的队列配置 645 /* Initialize the port/queue configuration of each logical core */ 646 //遍历所有port 647 for (portid = 0; portid < nb_ports; portid++) { 648 /* skip ports that are not enabled */ 649 //跳过没使能的端口 650 if ((l2fwd_enabled_port_mask & (1 << portid)) == 0) 651 continue; 652 653 /* get the lcore_id for this port */ 654 //port分配一个 lcore_id。 655 //rte_lcore_is_enabled(rx_lcore_id) 测试core是否使能 656 //lcore_queue_conf是一个自定义的结构,包含port个数和portid 657 //意思是一个核心,对多个port的rx队列 658 //在这里,一个核心只能匹配一个port 659 while (rte_lcore_is_enabled(rx_lcore_id) == 0 || 660 lcore_queue_conf[rx_lcore_id].n_rx_port == 661 l2fwd_rx_queue_per_lcore) { 662 rx_lcore_id++; 663 if (rx_lcore_id >= RTE_MAX_LCORE) 664 rte_exit(EXIT_FAILURE, "Not enough cores "); 665 } 666 667 //赋值qconf,qconf最开始为NULL 668 if (qconf != &lcore_queue_conf[rx_lcore_id]) 669 /* Assigned a new logical core in the loop above. */ 670 qconf = &lcore_queue_conf[rx_lcore_id]; 671 672 //当前lcore添加一个port 673 //当前lcore管理的rx_port总数+1 674 qconf->rx_port_list[qconf->n_rx_port] = portid; 675 qconf->n_rx_port++; 676 printf("Lcore %u: RX port %u ", rx_lcore_id, (unsigned) portid); 677 } 678 679 //使能的port总数 680 nb_ports_available = nb_ports; 681 682 /* Initialise each port */ 683 //获取可用的port个数 684 for (portid = 0; portid < nb_ports; portid++) { 685 /* skip ports that are not enabled */ 686 //不可用的会剪掉。 687 if ((l2fwd_enabled_port_mask & (1 << portid)) == 0) { 688 printf("Skipping disabled port %u ", (unsigned) portid); 689 nb_ports_available--; 690 continue; 691 } 692 /* init port */ 693 //初始化port 694 printf("Initializing port %u... ", (unsigned) portid); 695 fflush(stdout); 696 //配置port,其中port_conf是一个结构,包含关于port的配置 697 //vlan分离,crc硬件校验,认为这两个有用。 698 ret = rte_eth_dev_configure(portid, 1, 1, &port_conf); 699 if (ret < 0) 700 rte_exit(EXIT_FAILURE, "Cannot configure device: err=%d, port=%u ", 701 ret, (unsigned) portid); 702 703 //获取port的mac地址 704 //l2fwd_ports_eth_addr[] 的 类型为一个结构,是全局数组 705 rte_eth_macaddr_get(portid,&l2fwd_ports_eth_addr[portid]); 706 707 /* init one RX queue */ 708 //初始化RX队列 709 fflush(stdout); 710 //rx队列会绑定到当前port上,l2fwd_pktmbuf_pool为内存池 711 ret = rte_eth_rx_queue_setup(portid, 0, nb_rxd, 712 rte_eth_dev_socket_id(portid), 713 NULL, 714 l2fwd_pktmbuf_pool); 715 if (ret < 0) 716 rte_exit(EXIT_FAILURE, "rte_eth_rx_queue_setup:err=%d, port=%u ", 717 ret, (unsigned) portid); 718 719 /* init one TX queue on each port */ 720 //初始化tx队列 721 fflush(stdout); 722 //tx队列会绑定到port上 723 ret = rte_eth_tx_queue_setup(portid, 0, nb_txd, 724 rte_eth_dev_socket_id(portid), 725 NULL); 726 if (ret < 0) 727 rte_exit(EXIT_FAILURE, "rte_eth_tx_queue_setup:err=%d, port=%u ", 728 ret, (unsigned) portid); 729 730 /* Initialize TX buffers */ 731 //malloc tx缓存,tx_buffer为指针数组,每个port对应一个tx缓存 732 tx_buffer[portid] = rte_zmalloc_socket("tx_buffer", 733 RTE_ETH_TX_BUFFER_SIZE(MAX_PKT_BURST), 0, 734 rte_eth_dev_socket_id(portid)); 735 if (tx_buffer[portid] == NULL) 736 rte_exit(EXIT_FAILURE, "Cannot allocate buffer for tx on port %u ", 737 (unsigned) portid); 738 739 //初始化tx缓存 740 rte_eth_tx_buffer_init(tx_buffer[portid], MAX_PKT_BURST); 741 742 //tx缓存满了的时候,设置回调函数 743 ret = rte_eth_tx_buffer_set_err_callback(tx_buffer[portid], 744 rte_eth_tx_buffer_count_callback, 745 &port_statistics[portid].dropped); 746 if (ret < 0) 747 rte_exit(EXIT_FAILURE, "Cannot set error callback for " 748 "tx buffer on port %u ", (unsigned) portid); 749 750 /* Start device */ 751 //启动设备 752 ret = rte_eth_dev_start(portid); 753 if (ret < 0) 754 rte_exit(EXIT_FAILURE, "rte_eth_dev_start:err=%d, port=%u ", 755 ret, (unsigned) portid); 756 757 printf("done: "); 758 759 //设置网卡为混杂模式 760 rte_eth_promiscuous_enable(portid); 761 762 //打印port的MAC地址 763 printf("Port %u, MAC address: %02X:%02X:%02X:%02X:%02X:%02X ", 764 (unsigned) portid, 765 l2fwd_ports_eth_addr[portid].addr_bytes[0], 766 l2fwd_ports_eth_addr[portid].addr_bytes[1], 767 l2fwd_ports_eth_addr[portid].addr_bytes[2], 768 l2fwd_ports_eth_addr[portid].addr_bytes[3], 769 l2fwd_ports_eth_addr[portid].addr_bytes[4], 770 l2fwd_ports_eth_addr[portid].addr_bytes[5]); 771 772 /* initialize port stats */ 773 //初始化port属性 774 memset(&port_statistics, 0, sizeof(port_statistics)); 775 } 776 777 //如果可以使能的网卡为0个,则报错。 778 if (!nb_ports_available) { 779 rte_exit(EXIT_FAILURE, 780 "All available ports are disabled. Please set portmask. "); 781 } 782 783 //检查所有port的link属性 784 check_all_ports_link_status(nb_ports, l2fwd_enabled_port_mask); 785 786 ret = 0; 787 /* launch per-lcore init on every lcore */ 788 //启动所有的lcore,回调l2fwd_launch_one_lcore函数,参数为NULL 789 rte_eal_mp_remote_launch(l2fwd_launch_one_lcore, NULL, CALL_MASTER); 790 //遍历所有lcore_id 791 RTE_LCORE_FOREACH_SLAVE(lcore_id) { 792 //等所有线程结束 793 if (rte_eal_wait_lcore(lcore_id) < 0) { 794 ret = -1; 795 break; 796 } 797 } 798 799 //停止并且关闭所有的port 800 for (portid = 0; portid < nb_ports; portid++) { 801 if ((l2fwd_enabled_port_mask & (1 << portid)) == 0) 802 continue; 803 printf("Closing port %d...", portid); 804 rte_eth_dev_stop(portid); 805 rte_eth_dev_close(portid); 806 printf(" Done "); 807 } 808 printf("Bye... "); 809 810 return ret; 811 }