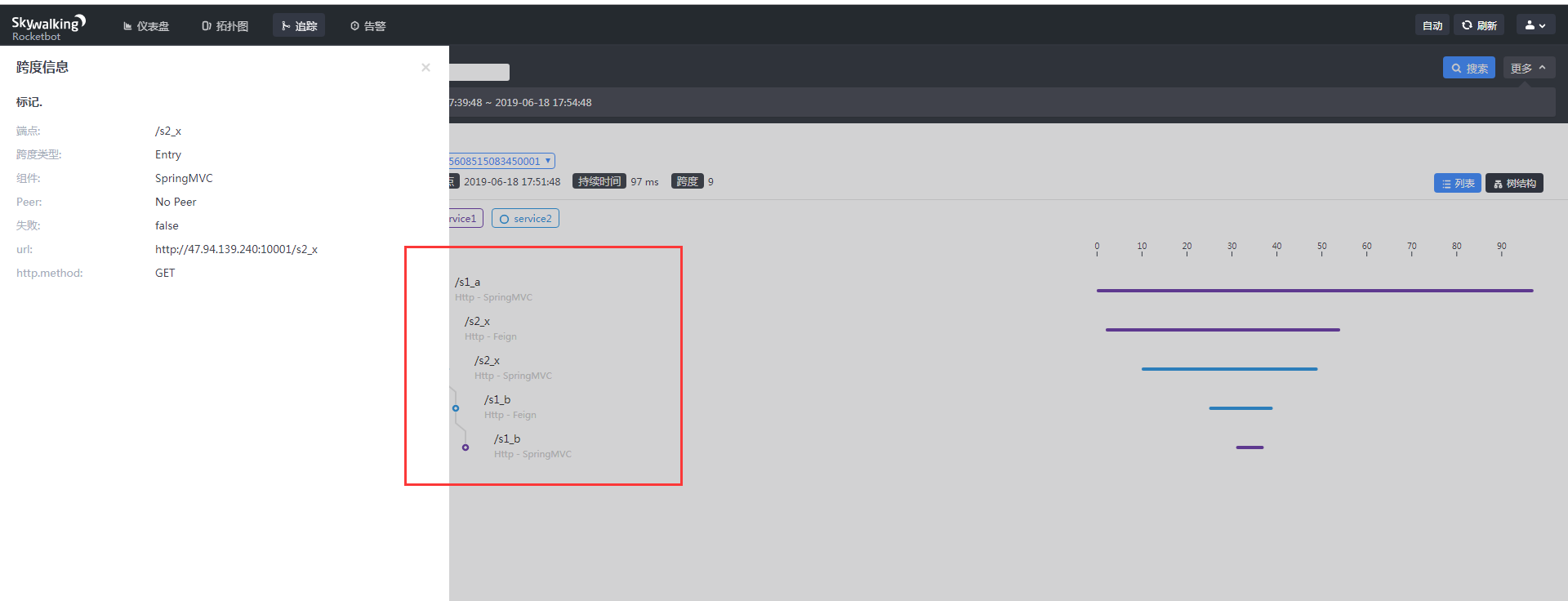
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。
Skywalking是一个可观测性分析平台和应用性能管理系统。
提供分布式跟踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。
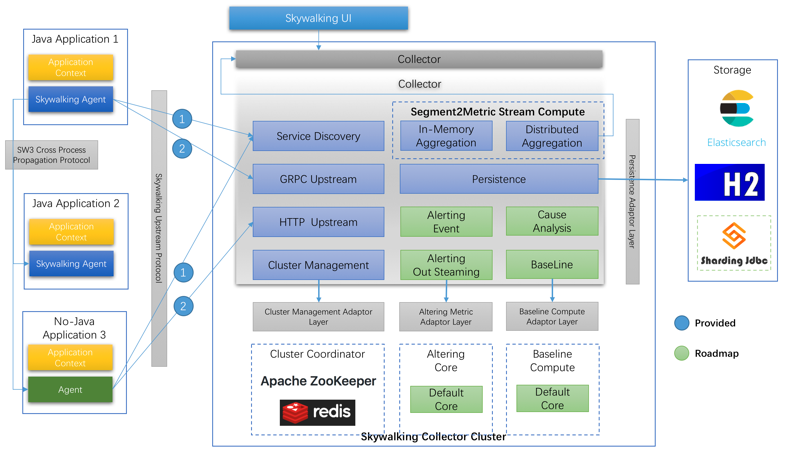
原理图
说几个碰到的坑:
- mysql 支持,github下载下来的包默认没有驱动,如果你要用mysql来存储数据,需要把mysql-connector-java-5.1.46.jar 放到oap-libs目录下
- 数据自动清除,默认删除90分钟前的数据
- 使用 端点面板 中 全局最慢端点追踪 中复制的id 去搜索是搜不到的,必须要加1
- 时区必须保持一致:Ubuntu18.04 设置时区.必须要用
不能使用域名,只能使用IP(碰到连接异常或者agent注册不上可以试试)
timedatectl set-timezone "Asia/Shanghai"
docker 中设置时区可以用
environment:
- TZ=Asia/Shanghai
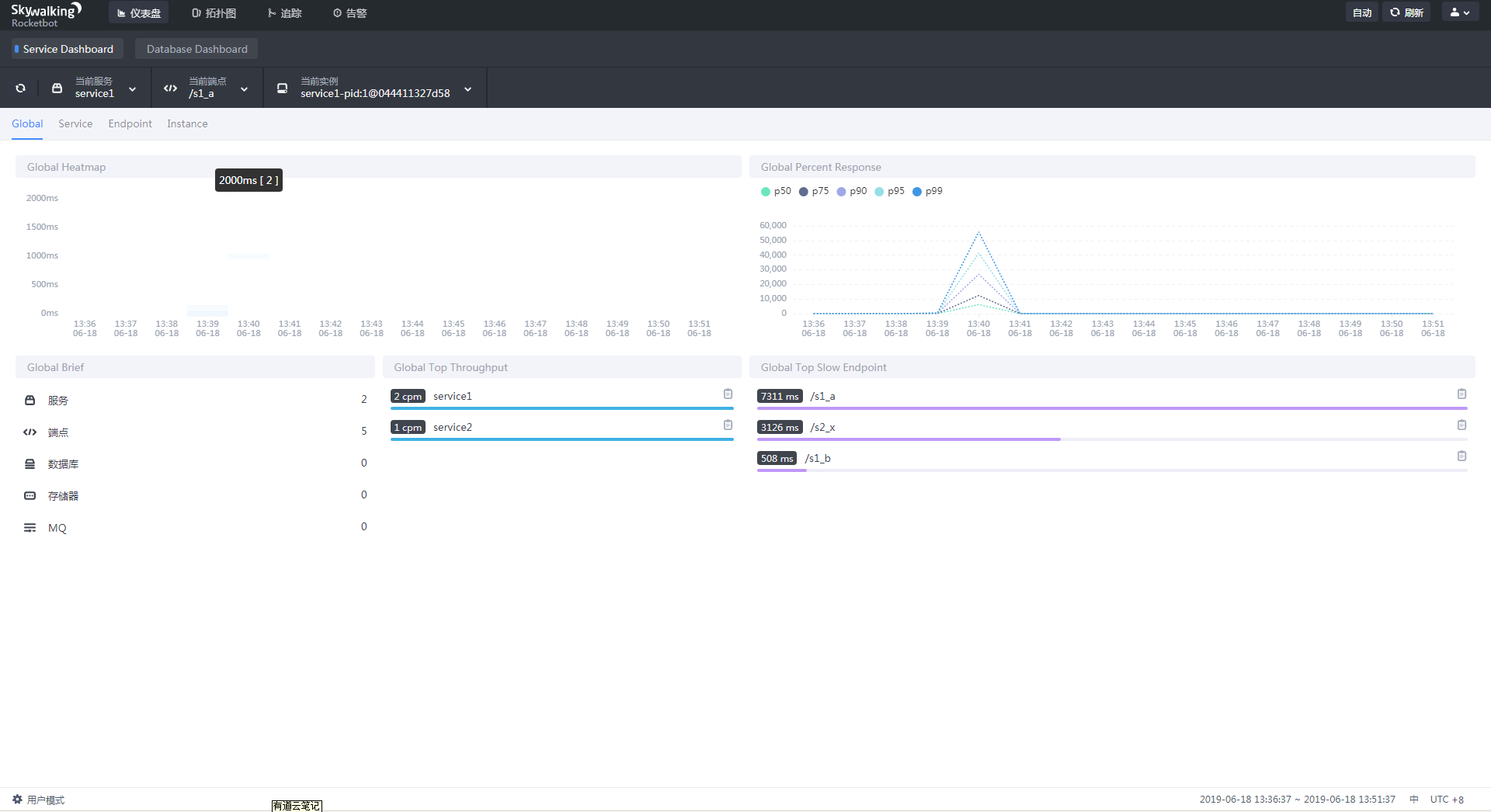
主界面

提供全局视图,主要展示了所有被监控服务的总体信息
具体有:
全局热图
提供每分钟响应时间的统计数据
全局响应百分比
(大于) 过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。例如,p99 1.403 表示过去 10 秒内最慢的 1% 请求的平均延迟为 1.403 秒。
(ps:这句话很拗口)

全局概况
全局最大吞吐量
每个服务每分钟调用次数
全局最慢端点
服务面板

主要提供当前选中服务的基础信息
全局概况
服务平均响应时间
服务平均吞吐量
该服务每分钟调用次数
服务平均可用性
通过请求成功与失败次数来计算(来源:http://blog.itpub.net/31562043/viewspace-2305574/)
全局响应百分比
过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。例如,p99 1.403 表示过去 10 秒内最慢的 1% 请求的平均延迟为 1.403 秒。
服务响应百分比
过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。例如,p99 1.403 表示过去 10 秒内最慢的 1% 请求的平均延迟为 1.403 秒。
服务最慢端点
该服务下响应最慢的端点
运行中的实例
端点面板
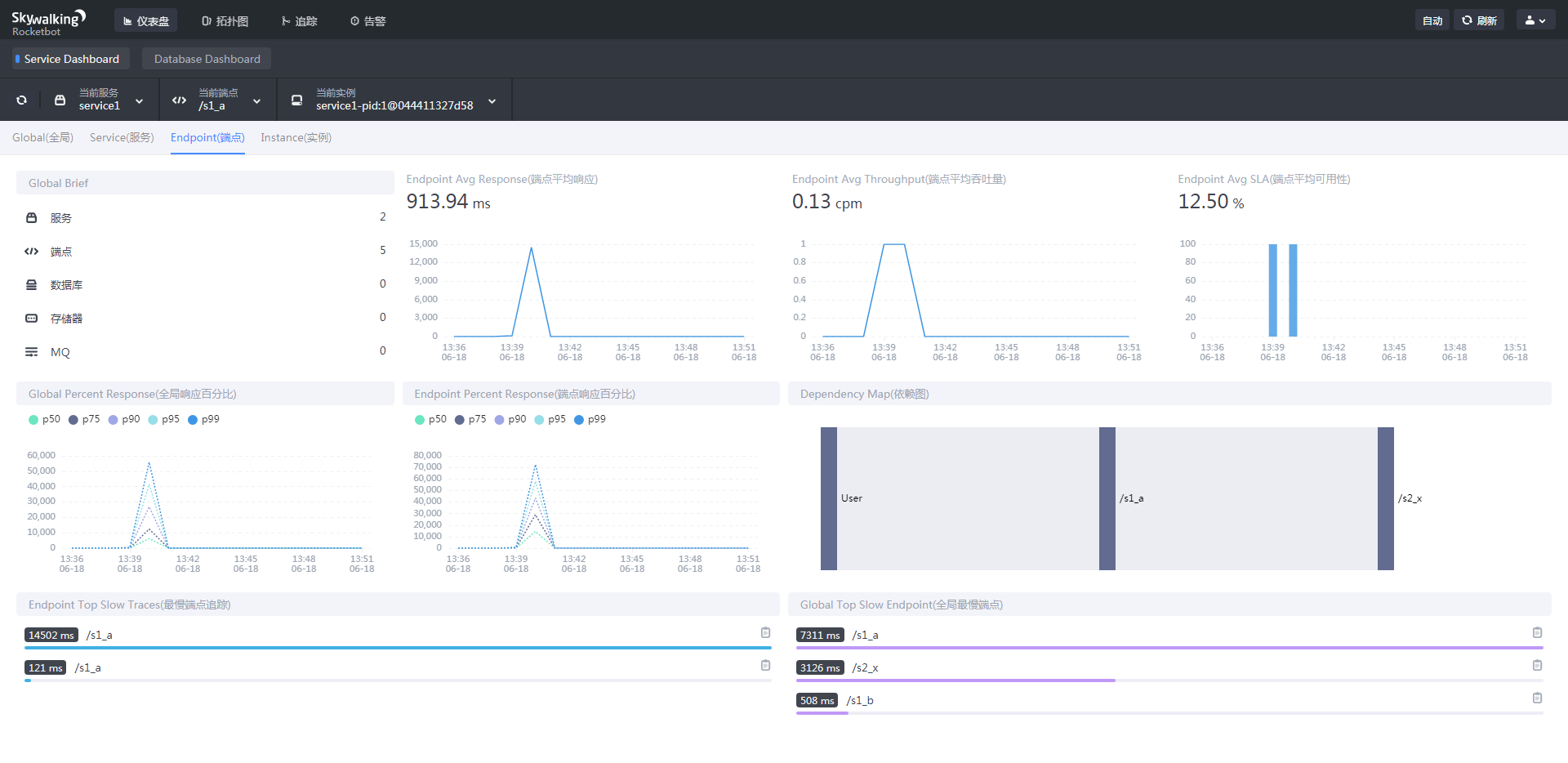
主要提供当前选中端点的基础信息
全局概况
端点平均响应时间
端点平均吞吐量
该端点每分钟调用次数
端点平均可用性
通过请求成功与失败次数来计算(来源:http://blog.itpub.net/31562043/viewspace-2305574/)
全局响应百分比
过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。例如,p99 1.403 表示过去 10 秒内最慢的 1% 请求的平均延迟为 1.403 秒。
端点响应百分比
过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。例如,p99 1.403 表示过去 10 秒内最慢的 1% 请求的平均延迟为 1.403 秒。
依赖关系图
最慢端点追踪
默认显示该服务下的最慢的十条记录,可以点击右侧的图标复制追踪ID进行查询详细信息
全局最慢端点
默认显示全局的最慢的十条记录,可以点击右侧的图标复制追踪ID进行查询详细信息
实例面板
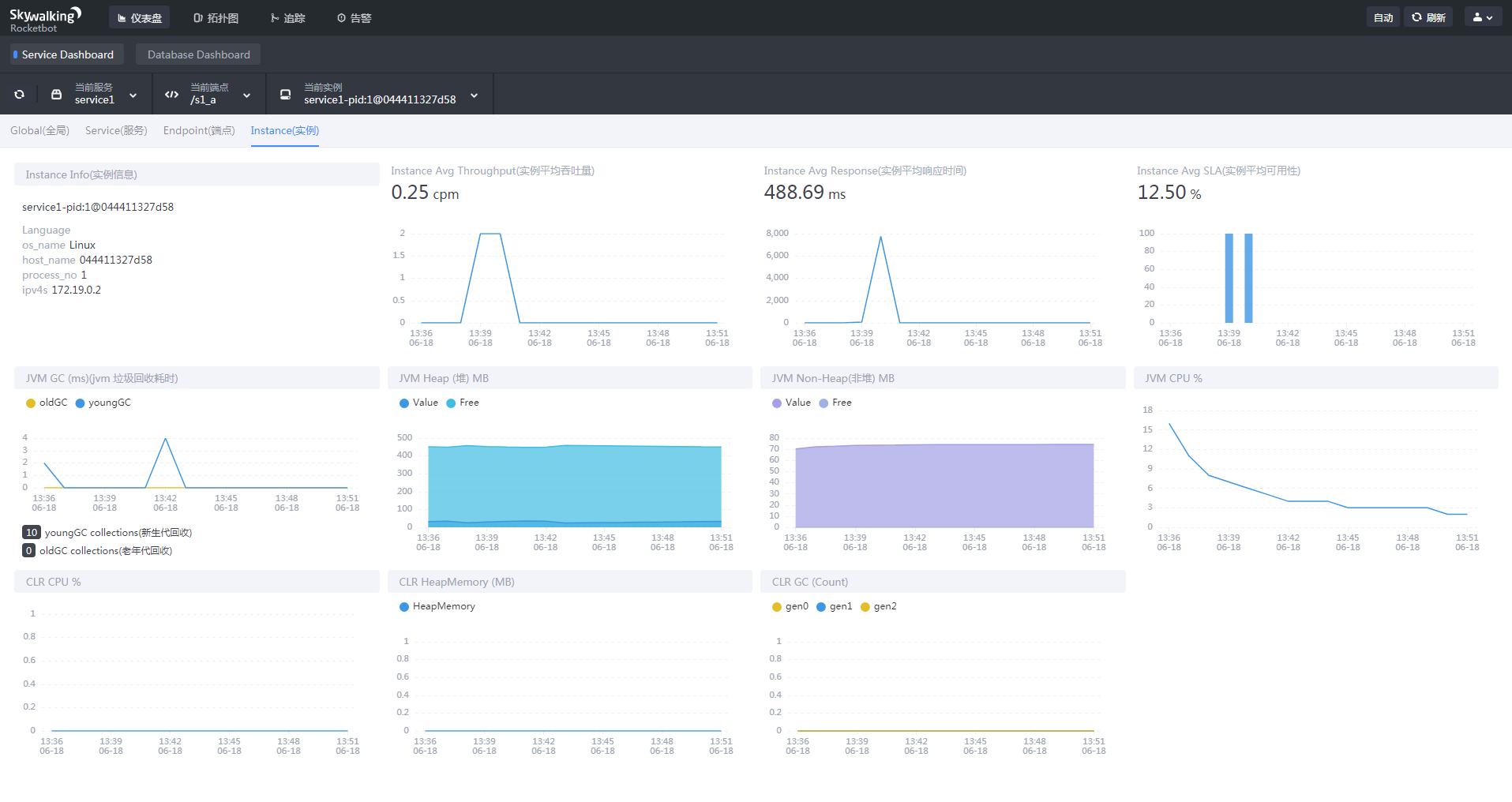
实例信息
该选中实例基础信息(语言,系统,主机名,流程号,ip)
实例平均吞吐量
该实例每分钟调用次数
实例平均响应时间
该实例平均响应时间
实例平均可用性
通过请求成功与失败次数来计算(来源:http://blog.itpub.net/31562043/viewspace-2305574/)
jvm 垃圾回收耗时
新生代,老年代
jvm 堆内存
jvm 非堆内存
jvm cpu
clr cpu
clr 堆内存
clr gc
拓扑图面板
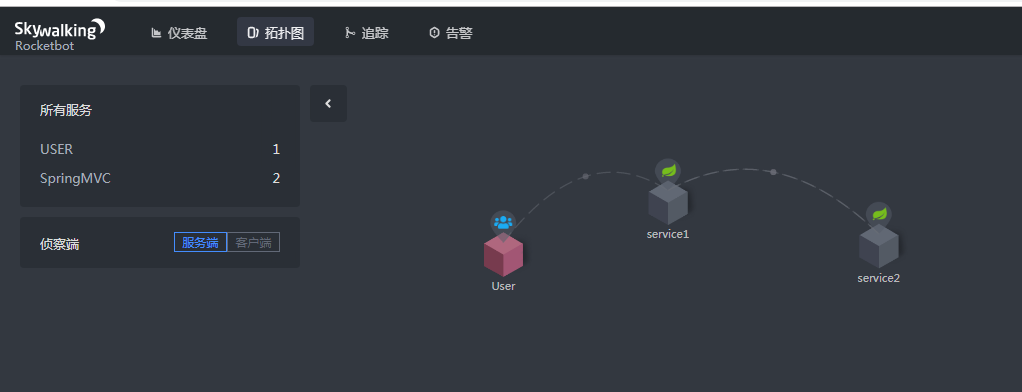
接口请求的拓扑图
追踪面板
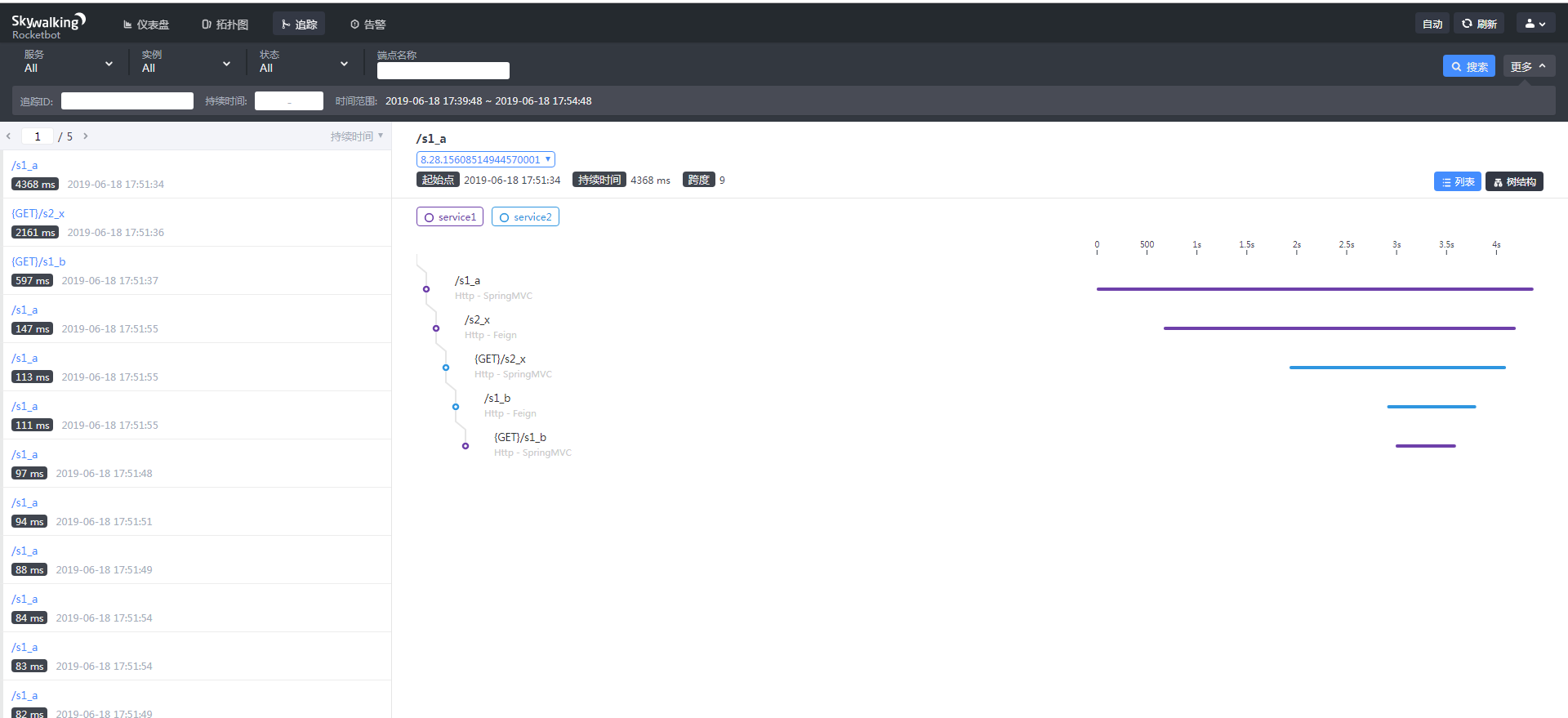
左上角可以输入追踪ID进行搜索
点击任意节点进行查询详情