1:非空判断
错误例子:
if(user.getUserName().equals("hollis")){ }
这段代码极有可能在实际运行的时候跑出NullPointerException。无论是user本身为空,还是user.getUserName()为空,都会抛出异常。 所以,在调用一个参数时要确保他是非空的。
上面的代码可以改为:
if(user!=null&&"hollis".equals(user.getUserName())){ }
2:用StringBuffer代替String
在循环中构建一个String对象时从性能上讲使用StringBuffer来代替String对象 例如:
// This is bad String s = ""; for (int i = 0; i < field.length; ++i) { s = s + field[i]; }
应该改为StringBuffer,使用append方法:
StringBuffer buf = new StringBuffer(); for (int i = 0; i < field.length; ++i) { buf.append(field[i]); } String s = buf.toString();
3:尽量减少对变量的重复计算
明确一个概念,对方法的调用,即使方法中只有一句语句,也是有消耗的,包括创建栈帧、调用方法时保护现场、调用方法完毕时恢复现场等。所以例如下面的操作:
for (int i = 0; i < list.size(); i++){
...
}
建议替换为:
for (int i = 0, length = list.size(); i < length; i++){ ... }
这样,在list.size()很大的时候,就减少了很多的消耗
4:尽量采用懒加载的策略,即在需要的时候才创建
例如:
String str = "aaa"; if (i == 1) { list.add(str); }
建议替换为:
if (i == 1) { String str = "aaa"; list.add(str); }
5:慎用异常
异常对性能不利。抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用名为 fillInStackTrace()的本地同步方法,fillInStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常被抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。异常只能用于错误处理,不应该用来控制程序流程。
6:不要在循环中使用try…catch…,应该把其放在最外层
7:如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度
比如ArrayList、LinkedLlist、StringBuilder、StringBuffer、HashMap、HashSet等等,以StringBuilder为例:
StringBuilder() // 默认分配16个字符的空间
StringBuilder(int size) // 默认分配size个字符的空间
StringBuilder(String str) // 默认分配16个字符+str.length()个字符空间
8:当复制大量数据时,使用 System.arraycopy()命令
9:乘法和除法使用移位操作
例如:
for (val = 0; val < 100000; val += 5) { a = val * 8; b = val / 2; }
用移位操作可以极大地提高性能,因为在计算机底层,对位的操作是最方便、最快的,因此建议修改为:
for (val = 0; val < 100000; val += 5) { a = val << 3; b = val >> 1; }
移位操作虽然快,但是可能会使代码不太好理解,因此最好加上相应的注释。
10:循环内不要不断创建对象引用
例如:
for (int i = 1; i <= count; i++) { Object obj = new Object(); }
这种做法会导致内存中有count份Object对象引用存在,count很大的话,就耗费内存了,建议为改为:
Object obj = null; for (int i = 0; i <= count; i++) { obj = new Object(); }
这样的话,内存中只有一份Object对象引用,每次new Object()的时候,Object对象引用指向不同的Object罢了,但是内存中只有一份,这样就大大节省了内存空间了。
11:不要将数组声明为public static final
因为这毫无意义,这样只是定义了引用为static final,数组的内容还是可以随意改变的,将数组声明为public更是一个安全漏洞,这意味着这个数组可以被外部类所改变
12:尽量在合适的场合使用单例
使用单例可以减轻加载的负担、缩短加载的时间、提高加载的效率,但并不是所有地方都适用于单例,简单来说,单例主要适用于以下三个方面:
控制资源的使用,通过线程同步来控制资源的并发访问
控制实例的产生,以达到节约资源的目的
控制数据的共享,在不建立直接关联的条件下,让多个不相关的进程或线程之间实现通信
13:尽量避免随意使用静态变量
要知道,当某个对象被定义为static的变量所引用,那么gc通常是不会回收这个对象所占有的堆内存的,如:
public class A { private static B b = new B(); }
此时静态变量b的生命周期与A类相同,如果A类不被卸载,那么引用B指向的B对象会常驻内存,直到程序终止
14:使用同步代码块替代同步方法
分析:
//下列两个方法有什么区别 public synchronized void method1(){} public void method2(){ synchronized (obj){} }
synchronized用于解决同步问题,当有多条线程同时访问共享数据时,如果不进行同步,就会发生错误,java提供的解决方案是:只要将操作共享数据的语句在某一时段让一个线程执行完,在执行过程中,其他线程不能进来执行可以。解决这个问题。这里在用synchronized时会有两种方式,一种是上面的同步方法,即用synchronized来修饰方法,另一种是提供的同步代码块。
这里总感觉怪怪的,这两种方法有什么区别呢?让我们看下代码:
public class SynObj { public synchronized void methodA() { System.out.println("methodA....."); try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } public void methodB() { synchronized(this) { System.out.pritntln("methodB....."); } } public void methodC() { String str = "sss"; synchronized (str) { System.out.println("methodC....."); } } } public class TestSyn { public static void main(String[] args) { final SynObj obj = new SynObj(); Thread t1 = new Thread(new Runnable() { @Override public void run() { obj.methodA(); } }); t1.start(); Thread t2 = new Thread(new Runnable() { @Override public void run() { obj.methodB(); } }); t2.start(); Thread t3 = new Thread(new Runnable() { @Override public void run() { obj.methodC(); } }); t3.start(); } }
这段小代码片段打印结果如下:
methodA.....
methodC.....
//methodB会隔一段时间才会打印出来
methodB.....
这段代码的打印结果是,methodA…..methodC…..会很快打印出来,methodB…..会隔一段时间才打印出来,那么methodB为什么不能像methodC那样很快被调用呢?
在启动线程1调用方法A后,接着会让线程1休眠5秒钟,这时会调用方法C,注意到方法C这里用synchronized进行加锁,这里锁的对象是str这个字符串对象。但是方法B则不同,是用当前对象this进行加锁,注意到方法A直接在方法上加synchronized,这个加锁的对象是什么呢?显然,这两个方法用的是一把锁。
*由这样的结果,我们就知道这样同步方法是用什么加锁的了,由于线程1在休眠,这时锁还没释放,导致线程2只有在5秒之后才能调用方法B,由此,可知两种加锁机制用的是同一个锁对象,即当前对象。
另外,同步方法直接在方法上加synchronized实现加锁,同步代码块则在方法内部加锁,很明显,同步方法锁的范围比较大,而同步代码块范围要小点,一般同步的范围越大,性能就越差,一般需要加锁进行同步的时候,肯定是范围越小越好,这样性能更好*。
同步代码块可以用更细粒度的控制锁,比如:
public class Test{ private String name = "xiaoming"; private String id = "0753"; public void setName(String name) { synchornized(name) { this.name = name; } } public void setId(String id) { synchornized(id) { this.id = id; } } }
如果你有一个Test对象 你想在多线程下同时修改Name和id, 如果你两个set方法都声明为同步方法,那么在同一时间只能修改name或者id. 但是这两个是可以同时修改的,所以你需要同步代码块,将信号量分别设置成name和id.
15:将常量声明为static final,并以大写命名
这样在编译期间就可以把这些内容放入常量池中,避免运行期间计算生成常量的值。另外,将常量的名字以大写命名也可以方便区分出常量与变量
16:不要创建一些不使用的对象,不要导入一些不使用的类
这毫无意义,如果代码中出现”The value of the local variable i is not used”、”The import java.util is never used”,那么请删除这些无用的内容
17:程序运行过程中避免使用反射
反射是Java提供给用户一个很强大的功能,功能强大往往意味着效率不高。不建议在程序运行过程中使用尤其是频繁使用反射机制,特别是Method的invoke方法,如果确实有必要,一种建议性的做法是将那些需要通过反射加载的类在项目启动的时候通过反射实例化出一个对象并放入内存—-用户只关心和对端交互的时候获取最快的响应速度,并不关心对端的项目启动花多久时间。
18:使用带缓冲的输入输出流进行IO操作
带缓冲的输入输出流,即BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream,这可以极大地提升IO效率。
19:不要让public方法中有太多的形参
public方法即对外提供的方法,如果给这些方法太多形参的话主要有两点坏处:
违反了面向对象的编程思想,Java讲求一切都是对象,太多的形参,和面向对象的编程思想并不契合
参数太多势必导致方法调用的出错概率增加
至于这个”太多”指的是多少个,3、4个吧。比如我们用JDBC写一个insertStudentInfo方法,有10个学生信息字段要插如Student表中,可以把这10个参数封装在一个实体类中,作为insert方法的形参。
20:公用的集合类中不使用的数据一定要及时remove掉
如果一个集合类是公用的(也就是说不是方法里面的属性),那么这个集合里面的元素是不会自动释放的,因为始终有引用指向它们。所以,如果公用集合里面的某些数据不使用而不去remove掉它们,那么将会造成这个公用集合不断增大,使得系统有内存泄露的隐患。
21:把一个基本数据类型转为字符串
基本数据类型.toString()是最快的方式、String.valueOf(数据)次之、数据+”"最慢
把一个基本数据类型转为一般有三种方式,我有一个Integer型数据i,可以使用i.toString()、String.valueOf(i)、i+”"三种方式,三种方式的效率如何,看一个测试:
public static void main(String[] args) { int loopTime = 50000; Integer i = 0; long startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++) { String str = String.valueOf(i); } System.out.println("String.valueOf():" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++) { String str = i.toString(); } System.out.println("Integer.toString():" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); for (int j = 0; j < loopTime; j++) { String str = i + ""; } System.out.println("i + "":" + (System.currentTimeMillis() - startTime) + "ms"); }
运行结果为:
String.valueOf():11ms
Integer.toString():5ms
i + "" :25ms
所以以后遇到把一个基本数据类型转为String的时候,优先考虑使用toString()方法。至于为什么,很简单:
String.valueOf()方法底层调用了Integer.toString()方法,但是会在调用前做空判断
Integer.toString()方法就不说了,直接调用了
i + “”底层使用了StringBuilder实现,先用append方法拼接,再用toString()方法获取字符串
三者对比下来,明显是2最快、1次之、3最慢。
22:使用最有效率的方式去遍历Map
遍历Map的方式有很多,通常场景下我们需要的是遍历Map中的Key和Value,那么推荐使用的、效率最高的方式是:
public static void main(String[] args) { HashMap<String, String> hm = new HashMap<String, String>(); hm.put( "111" , "222" ); Set<Map.Entry<String, String>> entrySet = hm.entrySet(); Iterator<Map.Entry<String, String>> iter = entrySet.iterator(); while (iter.hasNext()) { Map.Entry<String, String> entry = iter.next(); System.out.println(entry.getKey() + " " + entry.getValue()); } }
如果你只是想遍历一下这个Map的key值,那用”Set<String> keySet = hm.keySet();”会比较合适一些。
23:对资源的close()建议分开操作
意思是,比如我有这么一段代码:
try { XXX.close(); YYY.close(); } catch (Exception e) { ... } //建议修改为: try { XXX.close(); } catch (Exception e) { ... } try { YYY.close(); } catch (Exception e) { ... }
虽然有些麻烦,却能避免资源泄露。我们想,如果没有修改过的代码,万一XXX.close()抛异常了,那么就进入了catch块中了,YYY.close()不会执行,YYY这块资源就不会回收了,一直占用着,这样的代码一多,是可能引起资源句柄泄露的。而改为下面的写法之后,就保证了无论如何XXX和YYY都会被close掉。
24: 切记以常量定义的方式替代魔鬼数字,魔鬼数字的存在将极大地降低代码可读性,字符串常量是否使用常量定义可以视情况而定
25: long或者Long初始赋值时,使用大写的L而不是小写的l,因为字母l极易与数字1混淆,这个点非常细节,值得注意
26:静态类、单例类、工厂类将它们的构造函数置为private
这是因为静态类、单例类、工厂类这种类本来我们就不需要外部将它们new出来,将构造函数置为private之后,保证了这些类不会产生实例对象。
27: 避免Random实例被多线程使用,虽然共享该实例是线程安全的,但会因竞争同一seed 导致的性能下降,JDK7之后,可以使用ThreadLocalRandom来获取随机数
解释一下竞争同一个seed导致性能下降的原因,比如,看一下Random类的nextInt()方法实现:
public int nextInt() { return next( 32 ); } //调用了next(int bits)方法,这是一个受保护的方法: protected int next( int bits) { long oldseed, nextseed; AtomicLong seed = this .seed; do { oldseed = seed.get(); nextseed = (oldseed * multiplier + addend) & mask; } while (!seed.compareAndSet(oldseed, nextseed)); return ( int )(nextseed >>> ( 48 - bits)); } //而这边的seed是一个全局变量: /** * The internal state associated with this pseudorandom number generator. * (The specs for the methods in this class describe the ongoing * computation of this value.) */ private final AtomicLong seed;
多个线程同时获取随机数的时候,会竞争同一个seed,导致了效率的降低。:
28:jvm对常量为-128~127的整数进行缓存。

打印结果为false,而下面结果为true为啥
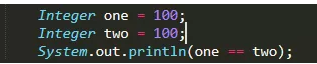
解答:Integer类型当正整数小于128时是在内存栈中创建值的,并将对象指向这个值,这样当比较两个栈引用时因为是同一地址引用两者则相等。当大于127时将会调用new Integer(),两个整数对象地址引用不相等了。这就是为什么当值为128时不相等,当值为100时相等了(java自己有个常量缓冲池 存着 -128~127的整数 )。
29:金额运算
@Test public void test4() { double num1 = 0.02d; double num2 = 0.03d; double num3 = num2 - num1; System.out.println(num3); }
console结果: 0.009999999999999998
为什么会这样呢? 因为float和double都是浮点数, 都有取值范围, 都有精度范围. 浮点数与通常使用的小数不同, 使用中, 往往难以确定. 常见的问题是定义了一个浮点数, 经过一系列的计算, 它本来应该等于某个确定值, 但实际上并不是! 金额必须是完全精确的计算, 故不能使用double或者float, 而应该采用java.math.BigDecimal.
使用BigDecimal的add, substract, multiply和divide做加减乘除, 用compareTo方法比较大小
@Test public void test4() { BigDecimal num1 = new BigDecimal("0.02"); BigDecimal num2 = new BigDecimal("0.03"); //加 System.out.println(num1.add(num2)); //减 System.out.println(num2.subtract(num1)); //乘 System.out.println(num1.multiply(num2)); //除 System.out.println(num1.divide(num2, RoundingMode.HALF_UP)); BigDecimal num3 = new BigDecimal("0.03"); if(num3.compareTo(BigDecimal.ZERO) == -1) { System.out.println("num3 小于0"); }else if(num3.compareTo(BigDecimal.ZERO) == 1) { System.out.println("num3大于0"); }else if(num3.compareTo(BigDecimal.ZERO) == 1) { System.out.println("num3等于0"); } BigDecimal num4 = new BigDecimal("0.1234567"); //其中setScale的第一个参数是小数位数, 这个示例是保留2位小数, 后面是四舍五入规则. System.out.println("num4:" + num4.setScale(2, BigDecimal.ROUND_UP)); }
console结果:
0.05
0.01
0.0006
0.67
num3大于0
num4:0.13
30:oracle获取时间的坑
执行:select to_char(sysdate, 'yyyymmddhhmmss'),to_char(sysdate, 'yyyyMMddHH24mmss'),to_char(sysdate, 'yyyyMMddHH24MISS') from dual;
输出:

oracle中的日期格式为:
yyyy-MM-dd HH24:mi:ss和 yyyy-MM-dd HH:mi:ss,分别代表oracle中的24小时制和12小时制
java中的的日期格式为:
yyyy-MM-dd HH:mm:ss:代表将时间转换为24小时制,例: 2018-06-27 15:24:21
yyyy-MM-dd hh:mm:ss:代表将时间转换为12小时制,例: 2018-06-27 03:24:21
之所以 oracle和java不同,是因为我们知道oracle是不区分大小写的,所以java中根据大小写来代表24小时和12小时的表达式在oracle中就会出问题,oracle中将24小时的小时和分钟做了特殊处理.如上所示,在hh后面加上了24,将mm改为了mi,而一旦不注意取到的时间就会出问题!
oracle中yyyyMMddHH24mmss其中yyyyMMddHH24mmss中的mm会返回月份,不能喝java的混淆
结论:oralce取当前时间用 to_char(sysdate, 'yyyyMMddHH24MISS')
31: 获取时间差
阿里巴巴手册建议:

计算两段代码时间差,很多同学公司的代码是采用以下这种方式。
long startTime = System.currentTimeMillis(); // 执行代码 long endTime = System.currentTimeMillis(); System.out.println(endTime - startTime);
这种方式并不是不行。按照“能跑就行”的原则,这段代码,肯定是能用的!但是这并不是最佳实践,为何? 我们先来看一下JDK中的注释
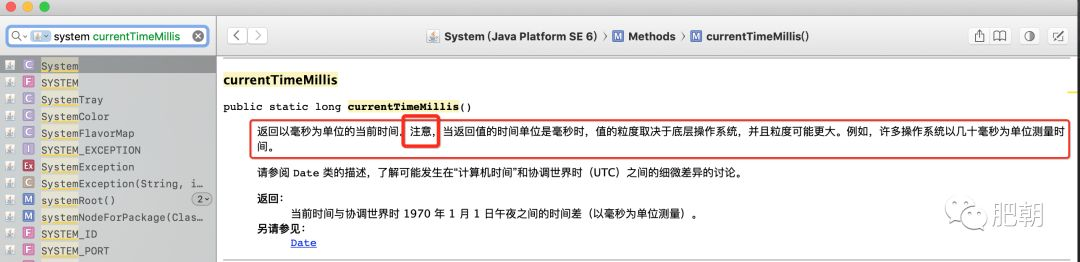
我们来看另外一种方式。
long startTime = System.nanoTime(); // 执行代码 long endTime = System.nanoTime(); System.out.println(endTime - startTime);
我们再来看看注释:

32: 需要 Map 的主键和取值时,应该迭代 entrySet()
当循环中只需要 Map 的主键时,迭代 keySet() 是正确的。但是,当需要主键和取值时,迭代 entrySet() 才是更高效的做法,比先迭代 keySet() 后再去 get 取值性能更佳。
反例:
Map<String, String> map = ...; for (String key : map.keySet()) { String value = map.get(key); ... }
正例:
Map<String, String> map = ...; for (Map.Entry<String, String> entry : map.entrySet()) { String key = entry.getKey(); String value = entry.getValue(); ... }
33: 应该使用Collection.isEmpty()检测空
使用 Collection.size() 来检测空逻辑上没有问题,但是使用 Collection.isEmpty()使得代码更易读,并且可以获得更好的性能。任何 Collection.isEmpty() 实现的时间复杂度都是 O(1) ,但是某些 Collection.size() 实现的时间复杂度可能是 O(n) 。
反例:
if (collection.size() == 0) { ... }
正例:
if (collection.isEmpty()) { ... }
如果需要还需要检测 null ,可采用 CollectionUtils.isEmpty(collection) 和 CollectionUtils.isNotEmpty(collection)。
34: List 的随机访问
大家都知道数组和链表的区别:数组的随机访问效率更高。当调用方法获取到 List 后,如果想随机访问其中的数据,并不知道该数组内部实现是链表还是数组,怎么办呢?可以判断它是否实现* RandomAccess *接口。
正例:
// 调用别人的服务获取到list List<Integer> list = otherService.getList(); if (list instanceof RandomAccess) { // 内部数组实现,可以随机访问 System.out.println(list.get(list.size() - 1)); } else { // 内部可能是链表实现,随机访问效率低 }
35: 频繁调用 Collection.contains 方法请使用 Set
在 java 集合类库中,List 的 contains 方法普遍时间复杂度是 O(n) ,如果在代码中需要频繁调用 contains 方法查找数据,可以先将 list 转换成 HashSet 实现,将 O(n) 的时间复杂度降为 O(1) 。
反例:
ArrayList<Integer> list = otherService.getList(); for (int i = 0; i <= Integer.MAX_VALUE; i++) { // 时间复杂度O(n) list.contains(i); }
正例:
ArrayList<Integer> list = otherService.getList(); Set<Integer> set = new HashSet(list); for (int i = 0; i <= Integer.MAX_VALUE; i++) { // 时间复杂度O(1) set.contains(i); }
36: 不要使用魔法值
当你编写一段代码时,使用魔法值可能看起来很明确,但在调试时它们却不显得那么明确了。这就是为什么需要把魔法值定义为可读取常量的原因。但是,-1、0 和 1不被视为魔法值。
反例:
for (int i = 0; i < 100; i++){ ... } if (a == 100) { ... }
正例:
private static final int MAX_COUNT = 100; for (int i = 0; i < MAX_COUNT; i++){ ... } if (count == MAX_COUNT) { ... }
37: 不要使用集合实现来赋值静态成员变量
对于集合类型的静态成员变量,不要使用集合实现来赋值,应该使用静态代码块赋值。
反例:
private static Map<String, Integer> map = new HashMap<String, Integer>() { { put("a", 1); put("b", 2); } }; private static List<String> list = new ArrayList<String>() { { add("a"); add("b"); } };
正例:
private static Map<String, Integer> map = new HashMap<>(); static { map.put("a", 1); map.put("b", 2); }; private static List<String> list = new ArrayList<>(); static { list.add("a"); list.add("b"); };
38: 工具类应该屏蔽构造函数
工具类是一堆静态字段和函数的集合,不应该被实例化。但是,Java 为每个没有明确定义构造函数的类添加了一个隐式公有构造函数。所以,为了避免 java "小白"使用有误,应该显式定义私有构造函数来屏蔽这个隐式公有构造函数。
反例:
public class MathUtils { public static final double PI = 3.1415926D; public static int sum(int a, int b) { return a + b; } }
正例:
public class MathUtils { public static final double PI = 3.1415926D; private MathUtils() {} public static int sum(int a, int b) { return a + b; } }
39: 使用String.valueOf(value)代替""+value
当要把其它对象或类型转化为字符串时,使用 String.valueOf(value) 比""+value 的效率更高。
反例:
int i = 1; String s = "" + i;
正例:
int i = 1; String s = String.valueOf(i);
40: 枚举的属性字段必须是私有不可变
枚举通常被当做常量使用,如果枚举中存在公共属性字段或设置字段方法,那么这些枚举常量的属性很容易被修改。理想情况下,枚举中的属性字段是私有的,并在私有构造函数中赋值,没有对应的 Setter 方法,最好加上 final 修饰符。
反例:
public enum UserStatus { DISABLED(0, "禁用"), ENABLED(1, "启用"); public int value; private String description; private UserStatus(int value, String description) { this.value = value; this.description = description; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } }
正例:
public enum UserStatus { DISABLED(0, "禁用"), ENABLED(1, "启用"); private final int value; private final String description; private UserStatus(int value, String description) { this.value = value; this.description = description; } public int getValue() { return value; } public String getDescription() { return description; } }
41: 小心String.split(String regex)
字符串 String 的 split 方法,传入的分隔字符串是正则表达式!部分关键字(比如.[]()| 等)需要转义
反例:
"a.ab.abc".split("."); // 结果为[]
"a|ab|abc".split("|"); // 结果为["a", "|", "a", "b", "|", "a", "b", "c"]
正例:
"a.ab.abc".split("\."); // 结果为["a", "ab", "abc"]
"a|ab|abc".split("\|"); // 结果为["a", "ab", "abc"]
42: 优先使用常量或确定值来调用 equals 方法
对象的 equals 方法容易抛空指针异常,应使用常量或确定有值的对象来调用 equals 方法。当然,使用 java.util.Objects.equals() 方法是最佳实践。
反例:
public void isFinished(OrderStatus status) { return status.equals(OrderStatus.FINISHED); // 可能抛空指针异常 }
正例:
public void isFinished(OrderStatus status) { return OrderStatus.FINISHED.equals(status); } public void isFinished(OrderStatus status) { return Objects.equals(status, OrderStatus.FINISHED); }