# 管道
from multiprocessing import Pipe,Process
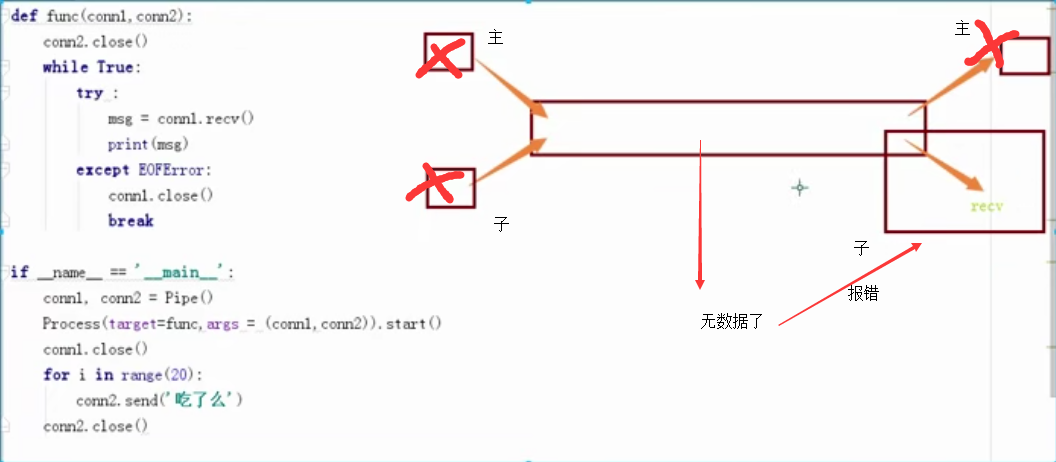
def func(conn1,conn2):
conn2.close() #子进程只关闭conn2时会抛出一个EOFError(没数据可取时recv),根据EOFError结束循环
while True:
try :
msg = conn1.recv()#不判断话会阻塞
print(msg)
except EOFError:
conn1.close()
break
if __name__ == '__main__':
conn1, conn2 = Pipe()
Process(target=func,args = (conn1,conn2)).start()
conn1.close()
for i in range(20):
conn2.send('吃了么')
conn2.close() #主进程Conn1和Conn2全部关闭,不会影响子进程的Conn1和Conn2
管道实现生产者消费者模型

# from multiprocessing import Lock,Pipe,Process
# def producer(con,pro,name,food):
# con.close()
# for i in range(100):
# f = '%s生产%s%s'%(name,food,i)
# print(f)
# pro.send(f)
# pro.send(None)
# pro.send(None)
# pro.send(None)
# pro.close()
#
# def consumer(con,pro,name,lock):
# pro.close()
# while True:
# lock.acquire()
# food = con.recv()
# lock.release()
# if food is None:
# con.close()
# break
# print('%s吃了%s' % (name, food))
# if __name__ == '__main__':
# con,pro = Pipe()
# lock= Lock()
# p = Process(target=producer,args=(con,pro,'egon','泔水'))
# c1 = Process(target=consumer, args=(con, pro, 'alex',lock))
# c2 = Process(target=consumer, args=(con, pro, 'bossjin',lock))
# c3 = Process(target=consumer, args=(con, pro, 'wusir',lock))
# c1.start()
# c2.start()
# c3.start()
# p.start()
# con.close()
# pro.close()
# from multiprocessing import Process,Pipe,Lock
#
# def consumer(produce, consume,name,lock):
# produce.close()
# while True:
# lock.acquire()
# baozi=consume.recv()
# lock.release()
# if baozi:
# print('%s 收到包子:%s' %(name,baozi))
# else:
# consume.close()
# break
#
# def producer(produce, consume,n):
# consume.close()
# for i in range(n):
# produce.send(i)
# produce.send(None)
# produce.send(None)
# produce.close()
#
# if __name__ == '__main__':
# produce,consume=Pipe()
# lock = Lock()
# c1=Process(target=consumer,args=(produce,consume,'c1',lock))
# c2=Process(target=consumer,args=(produce,consume,'c2',lock))
# p1=Process(target=producer,args=(produce,consume,30))
# c1.start()
# c2.start()
# p1.start()
# produce.close()
# consume.close()
# pipe 数据不安全性
# IPC
# 加锁来控制操作管道的行为 来避免(多人消费同时取一个数据)进程之间争抢数据造成的数据不安全现象
# 队列 进程之间数据安全的
# 管道 + 锁
# 进程之间的数据共享
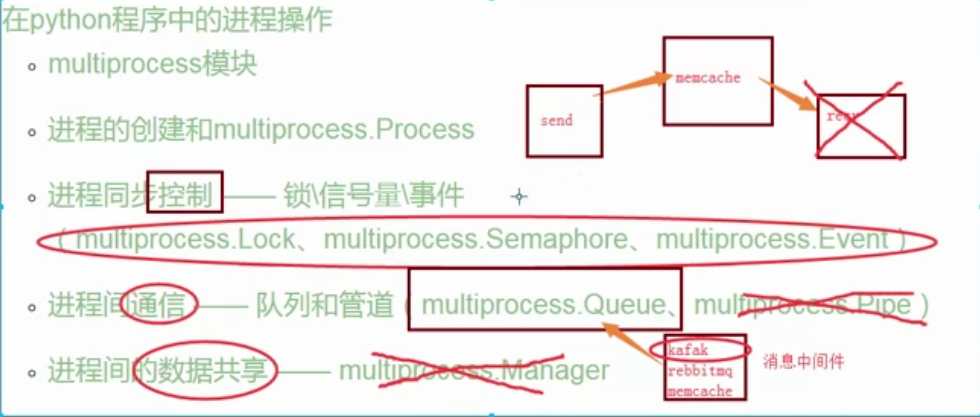
普通正常的进程之间数据是不共享的
# from multiprocessing import Manager,Process
# def main(dic):
# dic['count'] -= 1
# print(dic)
#
# if __name__ == '__main__':
# m = Manager()
# dic=m.dict({'count':100})
# p_lst = []
# p = Process(target=main, args=(dic,))
# p.start()
# p.join()
from multiprocessing import Manager,Process,Lock
def main(dic,lock):
lock.acquire()
dic['count'] -= 1 #这里会出现两个进程同时修改一个数据情况,最后会发现每次次执行count的值不一样,就是因为多进程同时操作一个数据导致的
lock.release() #,正常理想count值应该是50,为了达到这效果就加锁。虽然加锁在效率会降低,但安全
if __name__ == '__main__':
m = Manager()
l = Lock()
dic=m.dict({'count':100})
p_lst = []
for i in range(50):
p = Process(target=main,args=(dic,l))
p.start()
p_lst.append(p)
for i in p_lst: i.join()
print('主进程',dic)
# 进程池1(进程池中的进程是不会停,只有任务执行完成)
# 为什么会有进程池的概念(超过5个进程用进程池)
# 效率
# 每开启进程,开启属于这个进程的内存空间
# 寄存器 堆栈 文件
# 进程过多 操作系统的调度
# 进程池
# python中的 先创建一个属于进程的池子
# 这个池子指定能存放n个进程
# 先讲这些进程创建好
# 更高级的进程池(其他语言,自动识别任务减少池里进程或增加
# n,m
# 3 三个进程
# + 进程
# 20 20个
import time
from multiprocessing import Pool,Process
def func(n):
for i in range(10):
print(n+1)
def func2(n):
for i in range(10):
print(n+2)
if __name__ == '__main__':
start = time.time()
pool = Pool(5) # 5个进程
pool.map(func,range(100)) # 100个任务 map必须传可迭代对象参数(如range(100)、列表、字典等可for循环的类型)、自带join方法,执行完func后再执行func2(func/func2异步)
pool.map(func2,[('alex',1),'egon']) # 100个任务 (pool.map(函数名,参数))
t1 = time.time() - start
start = time.time()
p_lst = []
for i in range(100):
p = Process(target=func,args=(i,))
p_lst.append(p)
p.start()
for p in p_lst :p.join()
t2 = time.time() - start
print(t1,t2) # t1利用进程池一次跑5个20次交替100个任务 比t2利用多进程同时跑100个任务花费时间短

# 进程池2(最佳)
import os
import time
from multiprocessing import Pool
def func(n):
print('start func%s'%n,os.getpid())
time.sleep(1)
print('end func%s' % n,os.getpid())
if __name__ == '__main__':
p = Pool(5)
for i in range(10):
p.apply_async(func,args=(i,)) # p.apply(func,args=(i,)同步提交、p.apply_async(func,args=(i,))异步提交,凡出现async都是异步
p.close() # 结束进程池接收任务 不加下面两行代码话会出现主进程不等子进程执行完就结束了
p.join() # 感知进程池中的任务执行结束 必须在前面加p.close()才能感知任务执行的结束
利用异步的提交方式apply_async就可以随心所欲的掉函数名和传任何参数了
# 进程池的socket_server
server端
import socket
from multiprocessing import Pool
def func(conn):
conn.send(b'hello')
print(conn.recv(1024).decode('utf-8'))
conn.close()
if __name__ == '__main__':
p = Pool(5) #最多和5个人聊天
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.listen()
while True:
conn, addr = sk.accept()
p.apply_async(func,args=(conn,))
sk.close()
client端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8080))
ret = sk.recv(1024).decode('utf-8')
print(ret)
msg = input('>>>').encode('utf-8')
sk.send(msg)
sk.close()
# pycharm右键run开启多个client端来连接server
# 进程池的返回值
# p = Pool()
# p.map(funcname,iterable) 默认异步的执行任务,且自带close和join
# p.apply 同步调用的
# p.apply_async 异步调用 和主进程完全异步 需要手动close 和 join
# from multiprocessing import Pool
# def func(i):
# return i*i
#
# if __name__ == '__main__':
# p = Pool(5)
# for i in range(10):
# res = p.apply(func,args=(i,)) # apply的结果就是func的返回值
# print(res)
# import time
# from multiprocessing import Pool
# def func(i):
# time.sleep(0.5)
# return i*i
#
# if __name__ == '__main__':
# p = Pool(5)
# res_l = []
# for i in range(10):
# res = p.apply_async(func,args=(i,)) # apply的结果就是func的返回值,5个5个返回结果
# res_l.append(res) #如果这里直接打印res会出现同步现象,解决办法就是增加res_l,然后append再2循环打印res_l,异步任务中获取结果
# for res in res_l:print(res.get())# 等着 func的计算结果
# import time
# from multiprocessing import Pool
# def func(i):
# time.sleep(0.5)
# return i*i
#
# if __name__ == '__main__':
# p = Pool(5)
# ret = p.map(func,range(100)) 一次性返回结果
# print(ret) 打印结果列表
# 进程池的回调函数

# 回调函数(都回调到主进程)
import os
from multiprocessing import Pool
def func1(n):
print('in func1',os.getpid())
return n*n
def func2(nn):
print('in func2',os.getpid())
print(nn)
if __name__ == '__main__':
print('主进程 :',os.getpid())
p = Pool(5)
for i in range(10):
p.apply_async(func1,args=(10,),callback=func2)
p.close()
p.join()

总结
# 管道
# 数据的共享 Manager dict list
# 进程池
# cpu个数+1(进程池设置的进程)
# ret = map(func,iterable)
# 异步 自带close和join
# 所有结果的[]
# apply
# 同步的:只有当func执行完之后,才会继续向下执行其他代码
# ret = apply(func,args=())
# 返回值就是func的return
# apply_async
# 异步的:当func被注册进入一个进程之后,程序就继续向下执行
# apply_async(func,args=())
# 返回值 : apply_async返回的对象obj
# 为了用户能从中获取func的返回值obj.get()
# get会阻塞直到对应的func执行完毕拿到结果
# 使用apply_async给进程池分配任务,
# 需要先close后join来保持多进程和主进程代码的同步性
# 回调函数(多用于爬虫)
# 回调函数是在主进程中执行的
from multiprocessing import Pool
def func1(n):
return n+1
def func2(m):
print(m)
if __name__ == '__main__':
p = Pool(5)
for i in range(10,20):
p.apply_async(func1,args=(i,),callback=func2)
p.close()
p.join()
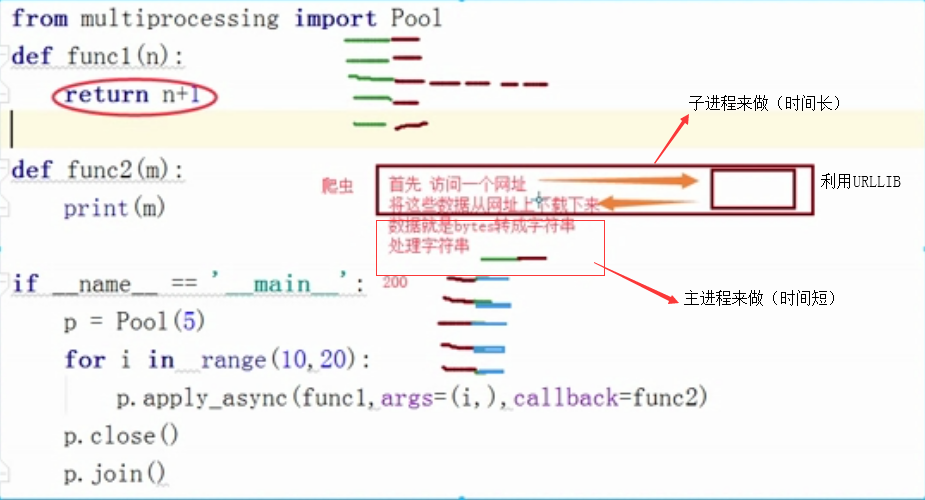
爬取数据的例子
import requests
from urllib.request import urlopen
from multiprocessing import Pool
# 200 网页正常的返回
# 404 网页找不到
# 502 504
def get(url):
response = requests.get(url)
if response.status_code == 200:
return url,response.content.decode('utf-8')
def get_urllib(url):
ret = urlopen(url)
return ret.read().decode('utf-8')
def call_back(args):
url,content = args
print(url,len(content))
if __name__ == '__main__':
url_lst = [
'https://www.cnblogs.com/',
'http://www.baidu.com',
'https://www.sogou.com/',
'http://www.sohu.com/',
]
p = Pool(5)
for url in url_lst:
p.apply_async(get,args=(url,),callback=call_back)
p.close()
p.join()
爬虫
import re
from urllib.request import urlopen
from multiprocessing import Pool
def get_page(url,pattern):
response=urlopen(url).read().decode('utf-8')
return pattern,response # 正则表达式编译结果 网页内容
def parse_page(info):
pattern,page_content=info
res=re.findall(pattern,page_content)
for item in res:
dic={
'index':item[0].strip(),
'title':item[1].strip(),
'actor':item[2].strip(),
'time':item[3].strip(),
}
print(dic)
if __name__ == '__main__':
regex = r'<dd>.*?<.*?class="board-index.*?>(d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
pattern1=re.compile(regex,re.S)
url_dic={'http://maoyan.com/board/7':pattern1}
p=Pool()
res_l=[]
for url,pattern in url_dic.items():
res=p.apply_async(get_page,args=(url,pattern),callback=parse_page)
res_l.append(res)
for i in res_l:
i.get()