Hadoop分布式HA的安装部署
前言
单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个namenode节点,一个为active状态,一个为standby状态。如下图: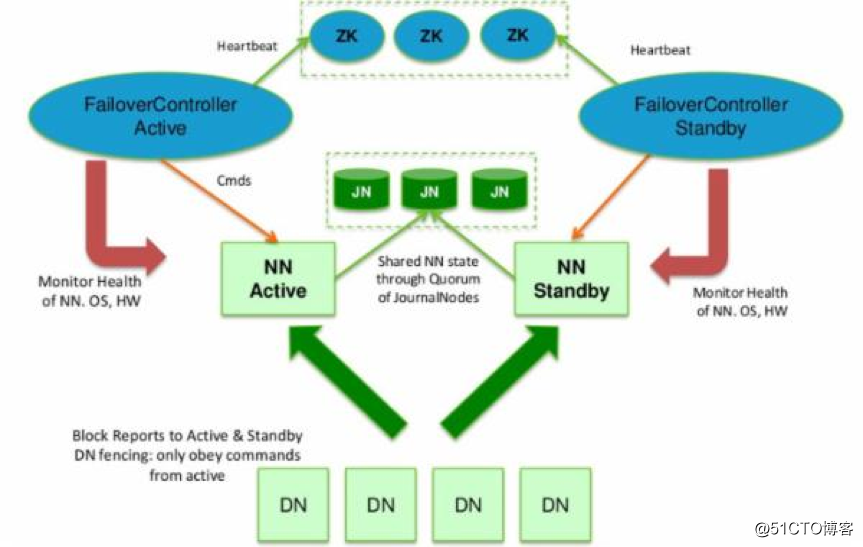
说明如下:
HDFS的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来同步FsEdits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的FsEdits信息,并更新自己内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的FsEdits,然后切换成Active状态。
使用HA的时候,不能启动
SecondaryNameNode,会出错。
集群的规划
ip 基本的软件 运行的进程
uplooking01 jdk、zk、hadoop NameNode、zkfc、zk、journalNode
uplooking02 jdk、zk、hadoop NameNode、zkfc、zk、journalNode、datanode、ResourceManager、NodeManager
uplooking03 jdk、zk、hadoop zk、journalNode、datanode、ResourceManager、NodeManagerzookeeper集群搭建
1、解压:
[uplooking@uplooking01 ~]$ tar -zxvf soft/zookeeper-3.4.6.tar.gz -C app/
2、重命名
[uplooking@uplooking01 ~]$ mv app/zookeeper-3.4.6 app/zookeeper
3、配置文件重命名
[uplooking@uplooking01 zookeeper]$ cp conf/zoo_sample.cfg conf/zoo.cfg
4、修改配置文件$ZOOKEEPER_HOME/conf/zoo.cfg
dataDir=/home/uplooking/app/zookeeper/data
dataLogDir=/home/uplooking/logs/zookeeper
server.101=uplooking01:2888:3888
server.102=uplooking02:2888:3888
server.103=uplooking03:2888:3888
启动server表示当前节点就是zookeeper集群中的一个server节点
server后面的.数字(不能重复)是当前server节点在该zk集群中的唯一标识
=后面则是对当前server的说明,用":"分隔开,
第一段是当前server所在机器的主机名
第二段和第三段以及2818端口
2181--->zookeeper服务器开放给client连接的端口
2888--->zookeeper服务器之间进行通信的端口
3888--->zookeeper和外部进程进行通信的端口
5、在dataDir=/home/uplooking/app/zookeeper/data下面创建一个文件myid
uplooking01机器对应的server.后面的101
uplooking02机器对应的server.后面的102
uplooking03机器对应的server.后面的103
6、需要将在uplooking01上面的zookeeper拷贝之uplooking02和uplooking03,这里使用scp远程拷贝
scp -r app/zookeeper uplooking@uplooking02:/home/uplooking/app
scp -r app/zookeeper uplooking@uplooking03:/home/uplooking/app
在拷贝的过程中需要设置ssh免密码登录
在uplooking02和uplooking03上面生成ssh密钥
ssh-keygen -t rsa
将密钥拷贝授权文件中
uplooking02:
ssh-keygen -t rsa
ssh-copy-id -i uplooking@uplooking02
uplooking03:
ssh-keygen -t rsa
ssh-copy-id -i uplooking@uplooking03
uplooking01:
ssh-copy-id -i uplooking@uplooking03
7、修改myid文件
[uplooking@uplooking02 ~]$ echo 102 > app/zookeeper/data/myid
[uplooking@uplooking03 ~]$ echo 103 > app/zookeeper/data/myid
8、同步环境变量文件
[uplooking@uplooking01 ~]$ scp .bash_profile uplooking@uplooking02:/home/uplooking/
[uplooking@uplooking01 ~]$ scp .bash_profile uplooking@uplooking03:/home/uplooking/
9、启动
在1、2、3分别执行zkServer.sh startHadoop分布式HA的部署
1、解压
[uplooking@uplooking01 ~]$ tar -zvxf soft/hadoop-2.6.4.tar.gz -C app/
2、重命名
[uplooking@uplooking01 ~]$ mv app/hadoop-2.6.4/ app/hadoop
3、修改配置文件
hadoop-env.sh、yarn-env.sh、hdfs-site.xml、core-site.xml、mapred-site.xml、yarn-site.xml、slaves
1°、hadoop-env.sh
export JAVA_HOME=/opt/jdk
2°、yarn-env.sh
export JAVA_HOME=/opt/jdk
3°、slaves
uplooking02
uplooking03
4°、hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>uplooking01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>uplooking01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>uplooking02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>uplooking02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://uplooking01:8485;uplooking02:8485;uplooking03:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/uplooking/data/hadoop/journal</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/uplooking/data/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/uplooking/data/hadoop/data</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/uplooking/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
5°、core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/uplooking/data/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</