数据库的操作越来越成为整个应用的性能瓶颈,这对于Web应用尤其明显。关于数据库的性能,这并不只是DBA需要关心的,而更是后端开发需要去关注的事情。
|-- 服务器硬件的优化
|-- MySQL数据库配置优化
|-- CentOS系统针对mysql的参数优化
|-- 内核相关参数(/etc/sysctl.conf)
|-- 增加资源限制(/etc/security/limit.conf)
|-- 磁盘调度策略
|-- MySQL的参数配置
|-- MySQL表结构与SQL优化
|-- 索引优化规则
|-- 1.使用最左前缀规则
|-- 2.模糊查询不能利用索引(like '%XX'或者like '%XX%')
|-- 3.不要过多创建索引
|-- 4.索引长度尽量短
|-- 5.索引更新不能频繁
|-- 6.索引列不能参与计算
|-- 查询时的优化
|-- 小表驱动大表
|-- 避免全表扫描
|-- 避免mysql放弃索引查询
|-- 使用覆盖索引,少使用select*
|-- order by的索引生效
|-- 不正确的使用导致索引失效
|-- for update锁表
|-- 其他优化
|-- 开启慢查询
|-- 实时获取有性能问题的SQL
|-- 垂直分割
|-- 拆分执行时间长的DELETE或INSERT语句
|-- 好书推荐
|-- 高性能MySQL
|-- 阿里巴巴Java开发手册
一、服务器硬件的优化
提升硬件设备,例如尽量选择高频率的内存(频率不能高于主板的支持)、提升网络带宽、使用SSD高速磁盘、提升CPU性能等。
CPU的选择:
- 对于数据库并发比较高的场景,CPU的数量比频率重要。
- 对于CPU密集型场景和频繁执行复杂SQL的场景,CPU的频率越高越好。
二、MySQL数据库配置优化
-
表示缓冲池字节大小。
推荐值为物理内存的50%~80%。
innodb_buffer_pool_size -
用来控制redo log刷新到磁盘的策略。
innodb_flush_log_at_trx_commit=1 -
每提交1次事务同步写到磁盘中,可以设置为n。
sync_binlog=1 -
脏页占innodb_buffer_pool_size的比例时,触发刷脏页到磁盘。 推荐值为25%~50%。
innodb_max_dirty_pages_pct=30 -
后台进程最大IO性能指标。
默认200,如果SSD,调整为5000~20000
innodb_io_capacity=200 -
指定innodb共享表空间文件的大小。
innodb_data_file_path -
慢查询日志的阈值设置,单位秒。
long_qurey_time=0.3 -
mysql复制的形式,row为MySQL8.0的默认形式。
binlog_format=row -
调高该参数则应降低interactive_timeout、wait_timeout的值。
max_connections=200 -
过大,实例恢复时间长;过小,造成日志切换频繁。
innodb_log_file_size -
全量日志建议关闭。
默认关闭。
general_log=0
上述参数可以使用以下命令查看:
SHOW VARIABLES LIKE '%innodb_buffer_pool_size%';
三、CentOS系统针对mysql的参数优化
内核相关参数(/etc/sysctl.conf)
以下参数可以直接放到sysctl.conf文件的末尾。
#增加监听队列上限
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.ipv4.tcp_max_syn_backlog = 65535
#加快TCP连接的回收
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
#TCP连接接收和发送缓冲区大小的默认值和最大值
net.core.wmem_max = 16777216
net.core.rmem_default = 87380
net.core.rmem_max = 16777216
#减少失效连接所占用的TCP资源的数量,加快资源回收的效率
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 3
#单个共享内存段的最大值
kernel.shmmax = 4294967295
- 这个参数应该设置的足够大,以便能在一个共享内存段下容纳整个的Innodb缓冲池的大小。
- 这个值的大小对于64位linux系统,可取的最大值为(物理内存值-1)byte,建议值为大于物理内存的一半,一般取值大于Innodb缓冲池的大小即可。
#控制换出运行时内存的相对权重
vm.swappiness = 0
这个参数当内存不足时会对性能产生比较明显的影响。(设置为0,表示Linux内核虚拟内存完全被占用,才会要使用交换区。)
在Linux系统安装时都会有一个特殊的磁盘分区,称之为系统交换分区。
使用
free -m 命令可以看到swap就是内存交换区。作用:当操作系统没有足够的内存时,就会将部分虚拟内存写到磁盘的交换区中,这样就会发生内存交换。
- 降低操作系统的性能
- 容易造成内存溢出,崩溃,或都被操作系统kill掉
增加资源限制(/etc/security/limit.conf)
- * soft nofile 65535
- * hard nofile 65535
soft:表示当前系统生效的设置(soft不能大于hard )
hard:表明系统中所能设定的最大值
nofile:表示所限制的资源是打开文件的最大数目
65535:限制的数量
磁盘调度策略
查看调度策略的方法:
cat /sys/block/devname/queue/scheduler
修改调度策略的方法:
echo <schedulername> > /sys/block/devname/queue/scheduler
更全面的参数优化,查看《Linux性能优化大师》
四、MySQL的参数优化

内存配置相关参数
mysql内存分配需要考虑到操作系统需要使用的内存,其他应用程序所要使用的内存,mysql的会话数以及每个会话使用的内存,然后就是操作系统实例所使用的内存。生产环境的mysql往往都是一个实例独占一个服务,因此,mysql实例需要考虑 mysql 的会话数,会话内存以及实例内存。
会话内存参数会为每一个连接的会话分配对应大小的内存,相关的主要参数有如下几个:
- sort_buffer_size:会话发送的语句需要进行排序时就会一次性分配对应的大小的缓存
- join_buffer_size:应用程序经常会出现一些两表(或多表)join 的操作需求,Mysql 在完成某些 join 需求的时候(all / index join),为了减少参与 join 的“被驱动表”的读取次数以提高性能,需要使用到 join buffer 来协助完成 join 操作。当 join buffer 太小,mysql 不会将该 buffer 存入磁盘文件,而是先将 join buffer 中的结果集与需要 join 的表进行 join 操作,然后清空 join buffer 中的数据,继续将剩余的结果集写入此 buffer 中,如此往复,会造成驱动表需要被多次读取,成倍增加 IO 访问,降低效率。
- read_buffer_size:mysql读入缓冲区的大小。对表进行顺序扫描的请求将分配一个读入缓冲区,mysql 会为他分配一段内存缓冲区。read_buffer_size 变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行的太慢,可以通过增加该变量以及内存缓冲区大小提高其性能。
- read_rnd_buffer_size:mysql 的随机读取缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,mysql 会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但 mysql 会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
- Innodb_buffer_size:InnoDB 使用该参数指定大小的内存来缓冲数据和索引,这个是 InnoDB引擎中影响性能最大的参数
- key_buffer_size:myisam 决定索引处理的速度,尤其是索引读的速度。默认是 16M,通过检查状态值 key_read_requests(从缓存读取索引的请求次数) 和 key_reads(从磁盘读取索引请求次数),可以知道 key_buffer_size 设置是否合理。比例 key_reads / key_read_requests 应该尽可能的低,至少是 1:100,1:1000 更好(SHOW STATUS LIKE 'key_read%')。key_buffer_size 只对 MyIsam 表起作用。即使你不使用 MyIsam 表,但是内部的临时磁盘表是 MyIsam 表,也要使用该值。设置该值大小可以通过语句获取:select sum(index_length) from information_schema.tables where engine='myisam';
IO相关配置参数
innodb 相关参数
innodb_log_file_size:这个值设置 redo log 文件的大小
innodb_log_files_in_group:这个值设置 redo log 文件的个数
innodb_log_buffer_size:redo log 缓存池的大小
innodb_flush_log_at_trx_commit:这个参数设置了 mysql redo log 刷新到日志文件的方式。该参数设置有以下三个值:
0:每隔一秒 mysql 将 redo log buffer 中的数据刷新到操作系统 cache中,并刷新到磁盘中,但是事务提交并不会引起任何操作。这样会至少丢失1秒钟的数据。
1:在每次事务提交时执行 log 写入 cache,并将数据刷新到磁盘(系统默认)
2:事务提交时会将数据刷新到操作系统的cache中,但是并不会引起数据刷新到磁盘中,该模式下,mysql会每秒执行一次刷新到磁盘操作,这样在系统崩溃时有可能造成 1s 的数据丢失。
当设置为0,该模式速度最快,但是不太安全,mysqld 进程崩溃会导致上一秒所有事务数据的丢失。设置为1,该模式最安全,但也是最慢的一种方式。在mysqld服务器崩溃或者服务器主机 crash的情况下,binary log只有可能丢失最多一个语句或者一个事务。设置为2,该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒数据才会丢失(介于0,1之间)
innodb_flush_method:这个参数控制着 innodb 数据文件及 redo log的打开、刷写模式。有三个值:fdatasync(默认,调用 fsync() 去刷数据文件redo log的buffer)、O_DSYNC、O_DIRECT
innodb_double_write:双写缓存,用来缓存保护数据避免写数据块时造成数据块损坏
MyIsam相关参数
delay_key_write:指在表关闭之前,将对表的 update 操作只更新数据到磁盘,而不更新索引到磁盘,把对索引的更改记录在内存。
安全相关配置参数
expire_log_days:指定二进制日志保留的天数
skip_name_resolve:禁用DNS查找
read_only:将数据库设置为只读模式
skip_slave_start:mysql启动后不会启动主从复制
其他配置
sync_binlog:同步二进制日志的频率,设置0的表示 mysql 不控制 bin log的刷新, bin log 日志刷新到磁盘完全依赖于文件的操作系统,这时候的性能是最好的,但是风险也是最大的。当设置为 n 时,指每个 N 次操作时进行磁盘同步,这里将磁盘设置为1是最安全的设置,但是刷新的频率过高对 IO 的影响也非常大。
tmp_table_size:规定了内部内存临时表的最大值,每个线程都要分配,如果内存临时表超出了限制,mysql 就会自动地把它转化为基于磁盘的 MyIsam表,存储在指定的 tmpdir 目录下
max_heap_table_size:这个变量定义了用户可以创建的内存表(memory table)的大小,这个值用来计算内存表的最大行数值。这个变量支持动态改变,即 set @max_heap_table_size = xxx,但是对于已经存在的内存表就没有什么用,除非这个表被重新创建或者修改或者 truncate table,服务重启也会设置已经存在的内存表为全局 max_heap_table_size 的值。这个参数和 tmp_table_size 一起限制了内部内存表的大小
max_connections:设置 mysql 会话连接的最大值
五、MySQL表结构与SQL优化
索引优化规则
理解索引优化的原理:《彻底搞懂MySQL的索引》
使用最左前缀规则
如果使用联合索引,要遵守最左前缀规则。即要求使用联合索引进行查询,从索引的最左前列开始,不跳过索引中的列并且不能使用范围查询(>、<、between、like)。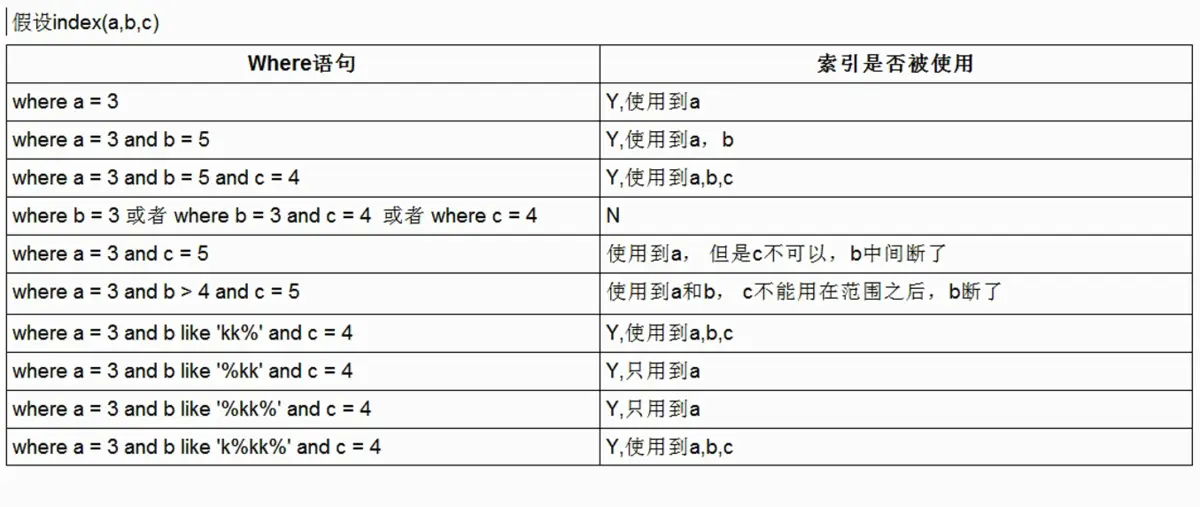
模糊查询不能利用索引(like '%XX'或者like '%XX%')
假如索引列code的值为'AAA','AAB','BAA','BAB',如果where code like '%AB'条件,由于条件前面是模糊的,所以不能利用索引的顺序,必须逐个查找,看是否满足条件。这样会导致全索引扫描或者全表扫描。
如果是where code like 'A%',就可以查找code中A开头的数据,当碰到B开头的数据时,就可以停止查找了,因为后面的数据一定不满足要求,这样可以提高查询效率。
不要过多创建索引
过多的索引会占用更多的空间,而且每次增、删、改操作都会重建索引。
在一般的互联网场景中,查询语句的执行次数远远大于增删改语句的执行次数,所以重建索引的开销可以忽略不计。但在大数据量导入时,可以考虑先删除索引,批量插入数据,然后添加索引。
尽量扩展索引,比如现有索引(a),现在又要对(a,b)进行索引,那么只需要修改索引(a)即可,避免不必要的索引冗余。
索引长度尽量短
短索引可以节省索引空间,使查找的速度得到提升,同时内存中也可以装载更多的索引键值。
太长的列,可以选择建立前缀索引。
索引更新不能频繁
更新非常频繁的数据不适宜建索引,因为维护索引的成本。
索引列不能参与计算
不要在索引列上做任何的操作,包括计算、函数、自动或者手动类型的转换,这样都会导致索引失效。
比如,where from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成where create_time = unix_timestamp(’2014-05-29’)。
查询时的优化
小表驱动大表

第一张表是全表索引(要以此关联其他表),其余表的查询类型type为range(索引区间获得),也就是6 * 1 * 1,共遍历查询6次即可;
建议使用left join时,以小表关联大表,因为使用join的话,第一张表是必须全扫描的,以少关联多就可以减少这个扫描次数。
这里所说的表的type,指的是explain执行计划中的结果字段。
避免全表扫描
mysql在使用不等于(!=或者<>)的时候无法使用导致全表扫描。在查询的时候,如果对索引使用不等于的操作将会导致索引失效,进行全表扫描
避免mysql放弃索引查询
如果mysql估计使用全表扫描要比使用索引快,则不使用索引。(最典型的场景就是数据量少的时候)
使用覆盖索引,少使用select*
需要用到什么数据就查询什么数据,这样可以减少网络的传输和mysql的全表扫描。
尽量使用覆盖索引,比如索引为name,age,address的组合索引,那么尽量覆盖这三个字段之中的值,mysql将会直接在索引上取值(using index),并且返回值不包含不是索引的字段。
order by的索引生效
order by排序应该遵循最佳左前缀查询,如果是使用多个索引字段进行排序,那么排序的规则必须相同(同是升序或者降序),否则索引同样会失效。
不正确的使用导致索引失效
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引。
for update锁表
A, B两个事务分别使用select ... where ... for update进行查询时:
A事务执行查询操作的时候,如果这个查询结果为空,无论where条件是否是索引字段,B事务执行查询操作时,不会被阻塞。
A事务执行查询操作的时候,当where条件是索引字段,则B事务执行同样的查询时会被行加锁阻塞;当where条件不是索引字段,则B事务执行有结果集的查询,都会被阻塞。
其他优化
开启慢查询
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,更好的优化数据库系统的性能。实时获取有性能问题的SQL
利用information_schema数据库的processlist表,实时查看执行时间过长的线程,定位需要优化的SQL。
例如下面的SQL的作用是查看正在执行的线程,并按Time倒排序,查看执行时间过长的线程。
select * from information_schema.processlist where Command != 'Sleep' order by Time desc;
垂直分割
“垂直分割”是一种把数据库中的表,按列变成几张表的方法。这样可以降低表的复杂度和字段的数目,从而达到优化的目的。
示例一:
在Users表中有一个字段是address,它是可选字段,并且不需要经常读取或是修改。
那么,就可以把它放到另外一张表中,这样会让原表有更好的性能。
示例二:
有一个叫 “last_login”的字段,它会在每次用户登录时被更新,每次更新时会导致该表的查询缓存被清空。
所以,可以把这个字段放到另一个表中。
这样就不会影响对用户ID、用户名、用户角色(假设这几个属性并不频繁修改)的不停地读取了,因为查询缓存会增加很多性能。
拆分执行时间长的DELETE或INSERT语句
避免在生产环境上执行会锁表的DELETE或INSERT的操作。一定把其拆分,或者使用LIMIT条件也是一个好的方法。
示例:
while (1) { //每次只做1000条 mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000"); if (mysql_affected_rows() == 0) { // 没得可删了,退出! break; } // 每次都要休息一会儿 usleep(50000); }