python语言刚刚开始学,又遇到了一个同学忘记自己的准考证号,99宿舍找回准考证号失败了,所以就想知道准考证号的大致范围,一个一个的去查总有结果,这只是最初的想法,于是就勇敢的去做了。
用wireshark抓包分析 得到的信息为 post方法
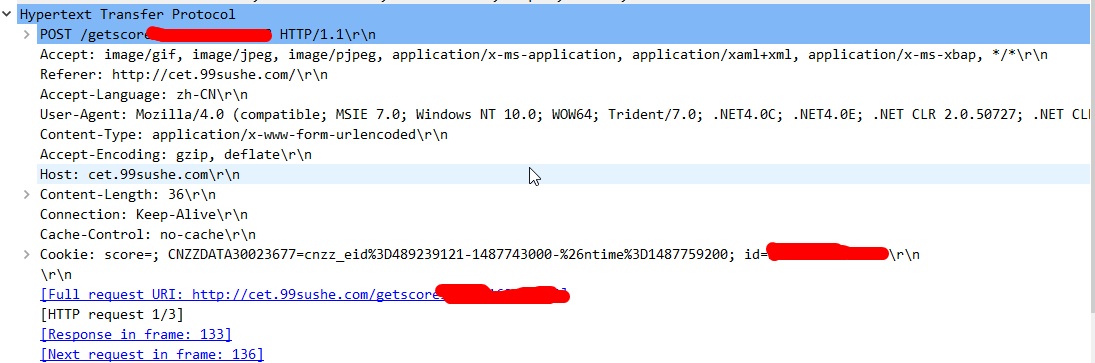
然后用python模拟post 由于这次是失败的,所以就没有贴代码
尝试过改过表头 返回的数据总是不正确,于是去网上查,看到爬学信网的代码,于是测试成功,但是99宿舍的没有成功,或许是99改了post提交
爬学信网的代码:
import requests import re #自定义头文件 header={'Referer':'http://www.chsi.com.cn/cet/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0', 'Host':'www.chsi.com.cn'} #学信网的url url="http://www.chsi.com.cn/cet/query" #读取每一行的准考证号和姓名 num0=0000000000 #准考证号 for i in range(100): num=str(num0+i) name='' #名字前两位 param={ 'zkzh':num, 'xm':name } #构造get response=requests.get(url,headers=header,params=param) #为了方便正则表达式找总分,去掉所有换行符 newtext=response.text.replace(' ','') try: #正则表达式找到总分 score=re.findall('<span class="colorRed">.*?(d+)',newtext) #输出“姓名+总分”字符串 ans=name+" "+score[0] #打印该字符串 print(ans) except: #打印未能成功爬取的人 print("no:",num,response.status_code)
总结这次失败的原因:对python语言不够熟悉,对post提交不够了解。
-----------------------------------------------------2017 2 26 下午--------------------------------------------
又尝试了一次,这次用的fiddler 4 来模拟http请求,几次模拟post提交都成功了,但是用python模拟就失败,当用fiddler抓python的post提交时,才发现中文没有进行编码,改掉之后,就成功了,
模拟post提交代码如下:
#!coding:utf-8 import requests header= { 'Host': 'cet.99sushe.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'Referer': 'http://cet.99sushe.com/', 'Cookie': 'CNZZDATA30023677=cnzz_eid%3D1356778947-1488029294-null%26ntime%3D1488083343; id=准考证号; score=', 'Connection': 'keep-alive', 'Upgrade-Insecure-Requests':'1', 'Content-Type': 'application/x-www-form-urlencoded', 'Content-Length': '36' } param={'id':'准考证号','name':'名字'.encode('gbk')} url="http://cet.99sushe.com/getscore+准考证号" print(url,param) response=requests.post(url,headers=header,data=param) print(response.text)
总结:汉字记得编码,如果查询的数量多的话,学信网会有验证码,99宿舍网会封ip,这点需要注意,