1 为什么要使用垃圾回收机制?
“垃圾收集”暗示程序不再需要的对象就是垃圾,可以被丢弃。更精确,更新的说法是“内存回收”。
1.1 新对象的使用
当一个对象不再被程序所引用时,他所使用的堆空间可以被回收,以便于被后续的新的对象使用。垃圾回收必须能判断哪些对象是不再被引用的,并且能够把他们所占据的堆空间释放出来,在释放不再被引用的对象的过程中,垃圾收集器运行将要被释放的对象的终结方法(finalizer)
1.2 处理堆碎片
除了释放不再被引用的对象之外,垃圾收集器还要处理堆碎片。堆碎片实在正常程序运行过程中产生的。新的对象分配了空间,不再被引用的对象被释放,所以堆碎块的空间位置介于活动的对象之间。请求分配新对象时可能不得不增大堆空间的大小,虽然可以使用的总空间是足够的。因为,堆中没有连续的空闲放得下新的对象。在一个虚拟机内存系统中,增长的堆所需要的额外分页(或交换)空间会影响运行程序的性能。
1.3 使用垃圾收集的有点和缺点
优点:把用户从释放占用内存的重担中解放出来
在一定程序上帮助程序保持完整性(是java安全策略一个重要的组成部分)
缺点:加大了程序的负担,可能会影响性能。虚拟机在追踪哪些对象被正在执行的程序所引用,并且动态的终结不再被使用的对象。和明确释放不再被使用的内存比起来,这个活动会需要更多的CPU时间。
2 垃圾收集算法
任何垃圾收集算法都必须完成俩件事情,首先,他必须检测出垃圾对象。其次,他必须回收垃圾对象所使用的堆空间并且还给程序。
垃圾检测通常通过建立一个根对象的集合并且检查从这些根对象开始的可触及性来实现。(可触及性:如果正在执行的程序可以访问到的根对象和某个对象之间存在引用路径)。对于程序来说,根对象总是可以被访问的。从这些根对象开始,任何可以被触及的对象都被认为是“活动”的对象。无法触及的对象被认为是垃圾,因为他们不再影响程序的未来执行。
区分活动对象和垃圾的基本方法是引用计数和跟踪。
2.1 引用计数收集器
在这种方法中,堆中每一个对象都有一个引用计数。当一个对象呗创建了,并且指向该对象的引用被分配了一个变量,这个对象的引用计数被置为1。当其他任何变量被赋值为对这个对象的引用时,计数加1.当一个对象的引用超过了生存期或者被设置一个新的值时,对象的引用计数减1。任何引用计数为0的对象都可以当成垃圾进行回收。当一个对象被垃圾收集的时候,他引用的任何对象计数值减1。这种方法中,一个对像被垃圾回收之后可能会导致后续其他对象的垃圾收集行动。
优缺点:可以很快的执行,交织在程序的运行之中。这个特性对于程序不能被长时间打断的实时环境很有利。坏处就是,引用计数无法检测出循环(俩个对象或者更多对象的相互引用)。目前该技术已经不为人接受了
2.2 跟踪收集器
跟踪收集器追踪从根节点开始的对象引用图。在追踪过程中遇到的对象以某种方式打上标记。总的来说,要么在对象本身设置标记,要么用一个队里的位图来设置标记。当追踪结束时,未被标记的对象就知道是无法触及的,从而被收集。
基本的追踪算法被称作“标记并清除”。在标记阶段,垃圾收集器遍历引用树,标记每一个遇到的对象。在清除阶段,未被标记的对象被释放,使用的内存被返回到正在执行的程序。清除步骤 必须包括对象的终结。
2.3 压缩收集器
这种方法用来简化消除堆碎块的工作,但是每一次对象访问都会带来性能的损失。
标记并清除收集器通常使用的俩种策略是压缩和拷贝。这俩种方法都是快速的移动对象来减少碎块。压缩收集器吧活动的对象越过空间滑动到堆的一端,在这个过程中,堆的另一端就会出现一个大的连续空闲区,所有被移动的对象的引用会被更新,指向新的位置。
2.4 拷贝收集器
拷贝收集器吧所有的活动对象移动到一个新的区域。再考呗过程中,他们紧挨着布置,所以可以消除原本他们在就区域的空隙。原有的区域被认为都是空闲区。这种方法的好处是对象可以在从跟对象开始的遍历过程中随着发现而被拷贝,不再有标记和清除的区分。
一般的拷贝收集器算法被称为“停止并拷贝”。
2.5 按代收集的收集器
在非常早的时候,我们看到过许多“分配慢”的意见 —— 因为就像早期 JVM 中的一切一样,它确实慢 —— 而性能顾问提供了许多避免分配的技巧,例如对象池。(公共服务声明:除了对最重量的对象之外,对象池现在对于所有对象都是严重的性能损失,而且要在不造成并发瓶颈的情况下使用对象池也很需要技巧。)但是,从 JDK 1.0 开始已经发生了许多变化;JDK 1.2 中引入的分代收集器(generational collector)支持简单得多的分配方式,可以极大地提高性能。
特征:
按代收集的收集器通过把对象按照寿命来分组解决这个效率低下的问题,更多的收集那些短暂出现的年幼对象,而非寿命较长的对象。在这种方法里,堆被划分为两个或者更多的子堆,每一个子堆为一“代”对象服务。最年幼的那一代进行最频繁的垃圾收集。因为大多数对象都是短促出现的,只有很小部分的年幼对象可以在它们经历第一次收集后存活。如果一个最年幼的对象经历了好几次垃圾收集后仍然存活,那么这个对象就成长为寿命更高的一代;它被转移到另外一个子堆中去。年龄更高的每一代的收集都没有年轻的那一些来的频繁。每当对象在它所属的年龄层(代)中变得成熟(逃过了多次垃圾收集)之后,它们就被转移到更高的年龄层中去。
2.6 自适应收集器
自适应收集器利用如下事实:在某种情况下某些垃圾收集算法工作的更好,而另外一些收集算法在另外的情况下工作更好。自适应算法监视堆中的情形,并且对应的调整为合适的垃圾收集技术。核心在于不同的情况下,使用这些算法最擅长的场景使用。
3 火车算法
垃圾收集算法和明确释放对象比起来有一个潜在的缺点,即垃圾收集算法中程序员对安排CPU时间进行内存回收缺乏控制。
火车算法是分代收集器所用的算法,目的是在成熟对象空间中提供限定时间的渐进收集。那么为什么要使用渐进收集呢?因为大范围的垃圾回收会占用大量的资源和时间,可能会导致暂停和无法满足系统实时性的要求,因此使用渐进收集。
车厢,火车和火车站
火车算法把成熟对象空间划分为固定长度的内存块,算法每次在一个块中单独执行。每个块属于一个集合。
块被叫车厢,集合被叫做火车,成熟对象空间是火车站。
火车被排序,块被附加到火车的尾部
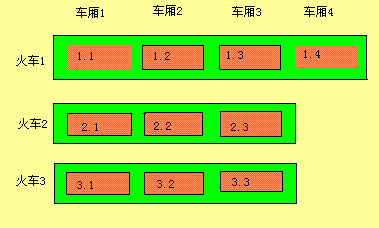
这种方式表示出了成熟对象空间内所有块的总体排序。
车厢收集
火车算法执行的时候,要么收集最小数字火车中的最小数字车厢,要么收集整个最小数字火车。
如果整个火车都是垃圾对象,那么整个火车都被收集。否则,收集最小数字车厢。
收集最小数字车厢时,如果发现该车厢内部有被其他车厢引用对象则会转移到引用的车厢,如此循环,最后收集整个车厢。
收集最小数字火车时,如果发现该火车内有被其他火车引用对象则会转移到引用的火车,如此循环,最后收集整个火车。
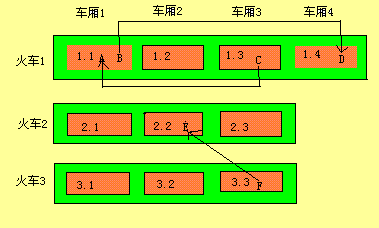

记忆集合和流行对象
为了促进收集过程,火车算法使用了记忆集合。一个记忆集合是一个数据结构,包含所有对一节车厢或者一列火车的外部引用。一个空的记忆集合表明车厢或者火车中的对象都不再被车厢或者火车外的任何变量引用,可以被垃圾收集。