打算学习用selenium + phantomJS爬取淘女郎页面照片。
一. 先安装lxml模块
python默认的解析器是html.parser,但lxml解析器更加强大,速度更快
1. 执行 pip install virtualenv
2. 从官方网站下载与系统,Python版本匹配的lxml文件:
http://pypi.python.org/pypi/lxml/2.3/
3. 执行 easy_install lxml-2.3-py2.7-win-amd64.egg
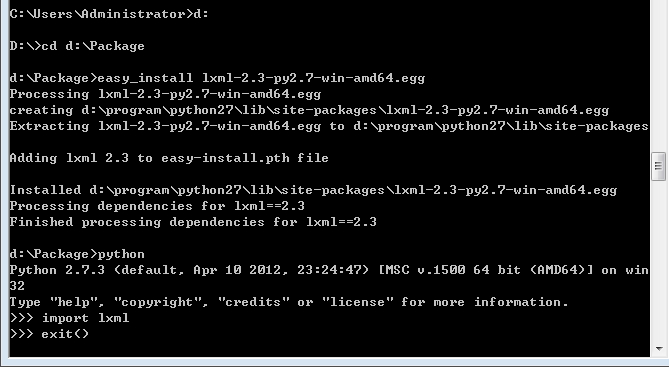
二. 安装selenium
pip install selenium
三. 使用selenium写个代码,体验一下,却出现报错
1 from selenium import webdriver 2 3 browser = webdriver.Chrome() 4 browser.get('http://www.baidu.com')
运行一下,出现报错
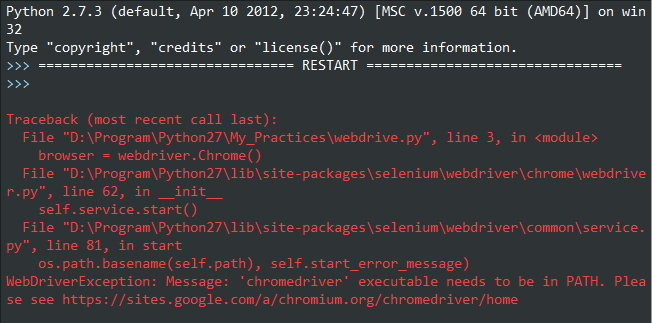
原因是没有安装chrome浏览器的chromedriver(浏览器驱动),好了直接下载chromedriver.exe,把它放到chrome的安装目录下...GoogleChromeApplication ,并配置环境变量,再次运行,又出现问题了:
原因:这是chrome浏览器版本和chromedriver版本不对应引起的,需要先查看chrome版本(可以在浏览器输入:chrome://help),我的版本是59:
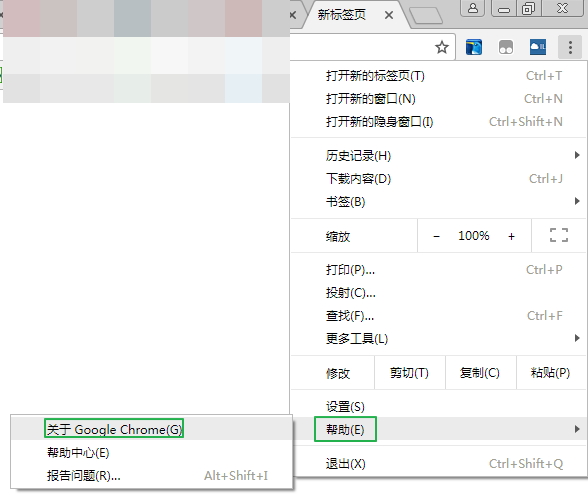
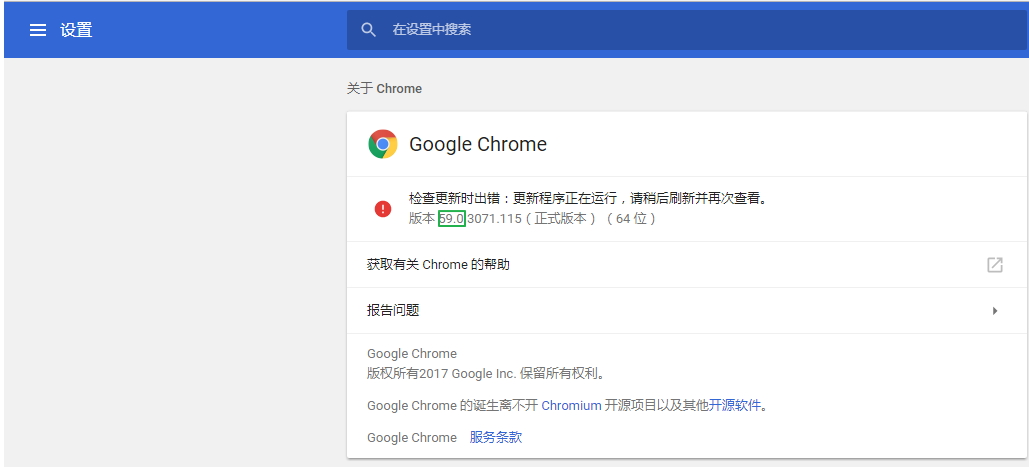
再查看chrome浏览器与chromedriver的对应表,这里这个博客selenium之 chromedriver与chrome版本映射表(更新至v2.31),列出版本映射表:
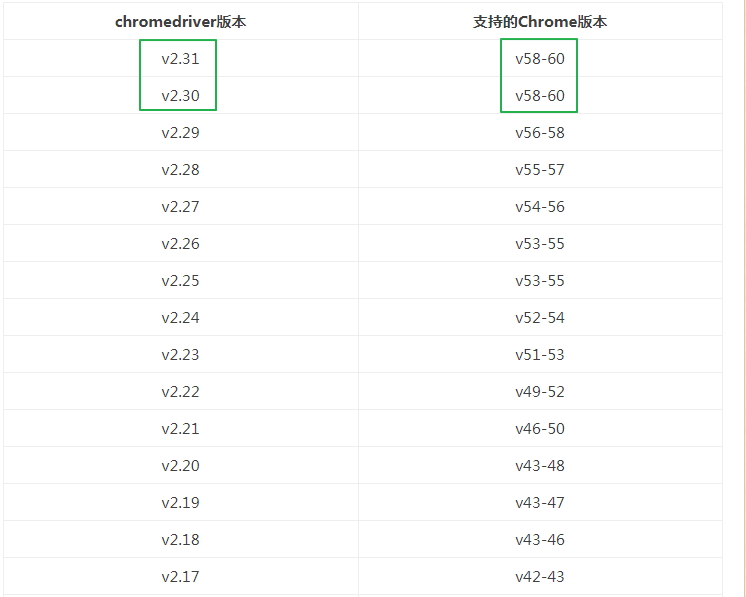
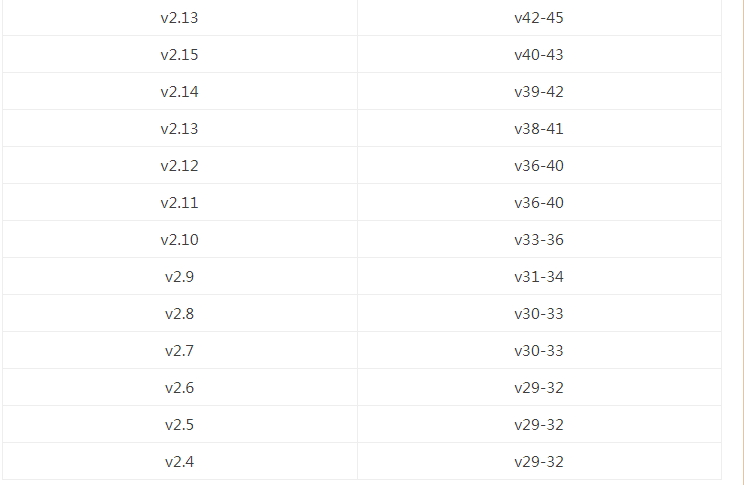
我的版本59对应的chromedriver的版本是2.3.0或2.3.1,从http://chromedriver.storage.googleapis.com/index.html下载2.3.0,得以成功运行:
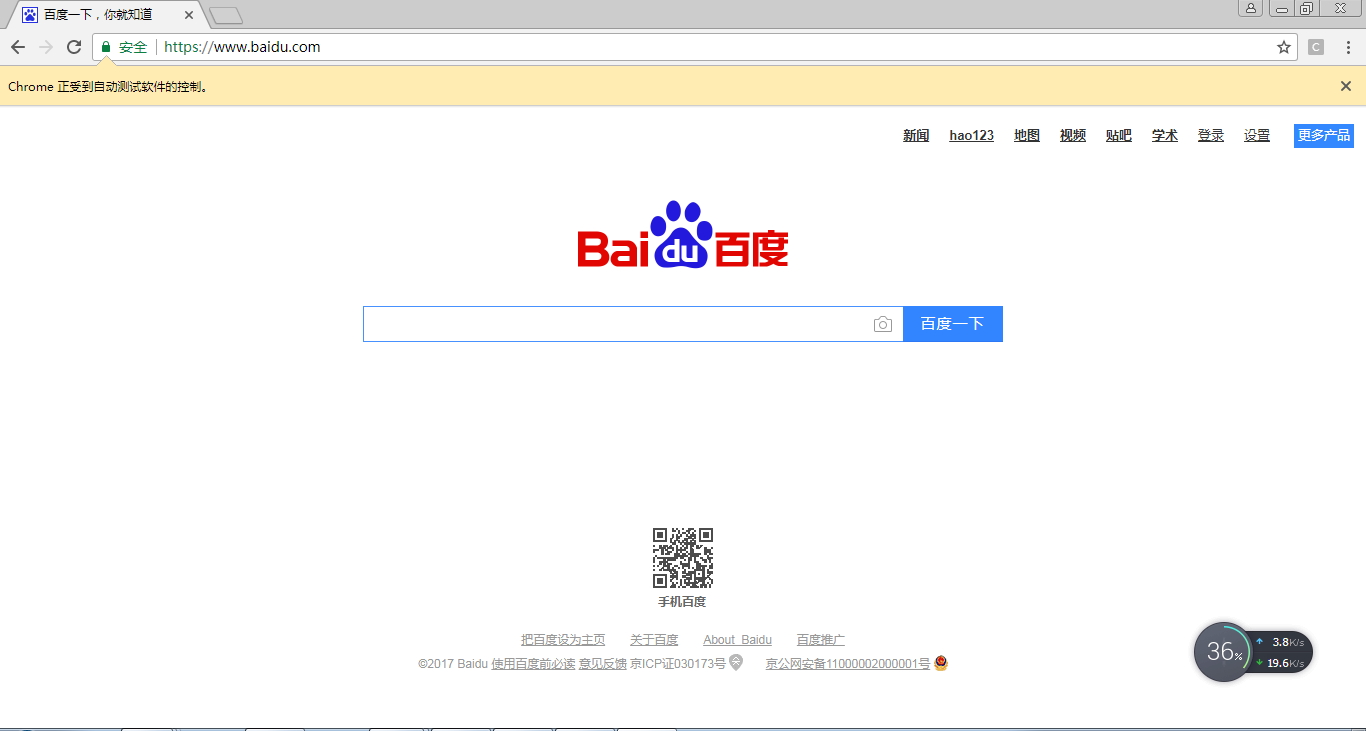
注:
可以去官网地址查看每个chromedriver版本对应的chrome浏览器版本:https://sites.google.com/a/chromium.org/chromedriver/downloads