python基础
一. python怎么连接数据库
答案:
- 安装pymysql:
pip install pymysql - 连接数据库,创建游标
# 连接数据库:cursorclass = pymysql.cursors.DictCursor 指定返回数据为字典格式
conn = pymysql.Connect(host, port, db, user, passwd,cursorclass = pymysql.cursors.DictCursor)
# 创建游标
cursor = conn.cursor()
- 准备好增删改查的sql语句,执行sql语句
增
# 使用格式化的方法构造sql语句
# 列表和元组 %s。字典%(键名)s
# eg1:列表
data = [14, 'xiaojian']
insert_sql = "insert into test1(id, name) values(%s, %s)"
# eg2:字典
data = {'id': 14, 'name': 'xiaojian'}
insert_sql = "insert into test1(id, name) values(%(id)s, %(name)s)"
# 执行execute方法
cursor.execute(insert_sql, data)
# 提交
conn.commit()
# 回滚
conn.rollback()
删
# 使用格式化的方法构造sql语句
data = 1
delete_sql = "delete from items where id = %s"
# 执行execute方法
cursor.execute(delete_sql, data)
# 提交
conn.commit()
# 回滚
conn.rollback()
改
# 使用格式化的方法构造sql语句
data = ("beck", 1)
update_sql = "update userinfo set name = %s where id = %s"
# 执行execute方法
cursor.execute(update_sql, data)
# 提交
conn.commit()
# 回滚
conn.rollback()
查
# 构造sql语句
query_sql = "select * from userinfo"
# 执行execute方法
cursor.execute(query_sql, data)
# 获取一条数据
data_one = cursor.fetchone()
# 获取所有数据
data_all = cursor.fetchall()
#查询是没有提交和回滚的方法的
- 对于查询到的数据做处理
- 关闭游标
cursor.close()
- 关闭连接
conn.close()
二. python是怎么获取当前系统时间
方法一:使用datetime模块
from datetime import datetime
datetime.now()
运行结果:datetime.datetime(2022, 6, 28, 21, 32, 14, 702706)
# 格式化输出
datetime.now().strftime('%Y-%m-%d %H:%M:%S')
运行结果:'2022-06-28 21:34:26'
方法二:使用time模块
import time
time.localtime(time.time())
运行结果:time.struct_time(tm_year=2022, tm_mon=6, tm_mday=28, tm_hour=21, tm_min=37, tm_sec=49, tm_wday=1, tm_yday=179, tm_isdst=0)
# 格式化输出
time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
运行结果:'2022-06-28 21:44:32'
三. python中的数据类型有哪一些
总共有六大类:
Numbers(数字)
String(字符串)
List(列表)
Tuple(元组)
Dictionary(字典)
Set(集合)
按照可变不可变分类有两种:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
数字类型细分
int(长整型)
float(浮点型)
complex(复数)
bool(布尔型)
四. python中怎么设置定时任务
- 安装轻量级的定时任务调度的库:
pip install schedule - 代码
import schedule
import time
def run():
print("I'm testing...")
schedule.every(10).minutes.do(run)
schedule.every().hour.do(run)
schedule.every().day.at("10:30").do(run)
schedule.every(5).to(10).days.do(run)
schedule.every().monday.do(run)
schedule.every().wednesday.at("13:15").do(run)
while True:
schedule.run_pending()
time.sleep(1)
schedule本身是个定时器。在while True死循环中,schedule.run_pending()是保持schedule一直运行,去查询上面那一堆的任务,在任务中,就可以设置不同的时间去运行
五. python中元组和列表的区别
相同点
- 都是序列
- 可存储任何数据类型
- 可通过索引访问
- 都支持切片
- 可以随意嵌套
不同点
- 写法上不同,列表: [], 元组()
- 是否可变。列表上可变的,可随意的增加、删除、修改元素,元组上不可变的,不可增加、删除、修改元素
- 是否可作为字典的key。由于列表是可变的,不能作为字典的key,而元组是不可变的,可以作为字典的key
- 大小不同。存储同样的元素,与列表相比,元组内存更小,速度更快
>>> my_list = ['http://www.baidu.com', 'http://www.google.cn']
>>> my_tuple = ('http://www.baidu.com', 'http://www.google.cn')
>>> my_list.__sizeof__()
56
>>> my_tuple.__sizeof__()
40
六. json和str类型转换
import json
json.loads(). #str转python dict对象(json)
json.dumps(). #python dict(json)对象转str
七. Excel文件操作
- 安装openpyxl库:
pip install openpyxl - 代码:
# 引入库
from openpyxl import load_workbook
# 加载一个excel文件,进入到工作簿
wb = load_workbook("testdata.xlsx")
# 获取指定的表单
sh = wb["Sheet1"]
# 获取表单中数据
name = sh.cell(row=2, column=1).value
print(name)
# 修改表单中的数据--修改数据,注意在写操作时,必须先关闭excel文件
sh.cell(row=2, column=3).value = 18
# 保存修改数据的操作--保存数据
wb.save("testdata.xlsx")
# 获取总行数、总列数
print(sh.max_row)
print(sh.max_column)
print(sh.cell(row=3, column=3).value)
sh.cell(row=3, column=3).value = 25
print(sh.cell(row=3, column=3))
# 读取所有数据,按行读取
for index in range(1, sh.max_row + 1):
print("行号: ", index)
for sub_i in range(1, sh.max_column + 1):
print("列号: ", sub_i, "内容: ", sh.cell(row=index, column=sub_i).value)
结果:
小翟
3
3
18
<Cell 'Sheet1'.C3>
行号: 1
列号: 1 内容: name
列号: 2 内容: sex
列号: 3 内容: age
行号: 2
列号: 1 内容: 小翟
列号: 2 内容: 男
列号: 3 内容: 18
行号: 3
列号: 1 内容: 瑛子
列号: 2 内容: 女
列号: 3 内容: 25
八. 多线程、进程和协程
可以看这一篇:《Python的多线程、多进程及协程》
九. 如何提取json中的内容
- 正则表达式
- 使用json.loads() 转为python 字典,再通过key获得值
- jsonpath
接口用例和自动化
一. 淘宝中购买的接口测试,如何设计测试用例
二. 微信支付的接口测试,如何设计测试用例
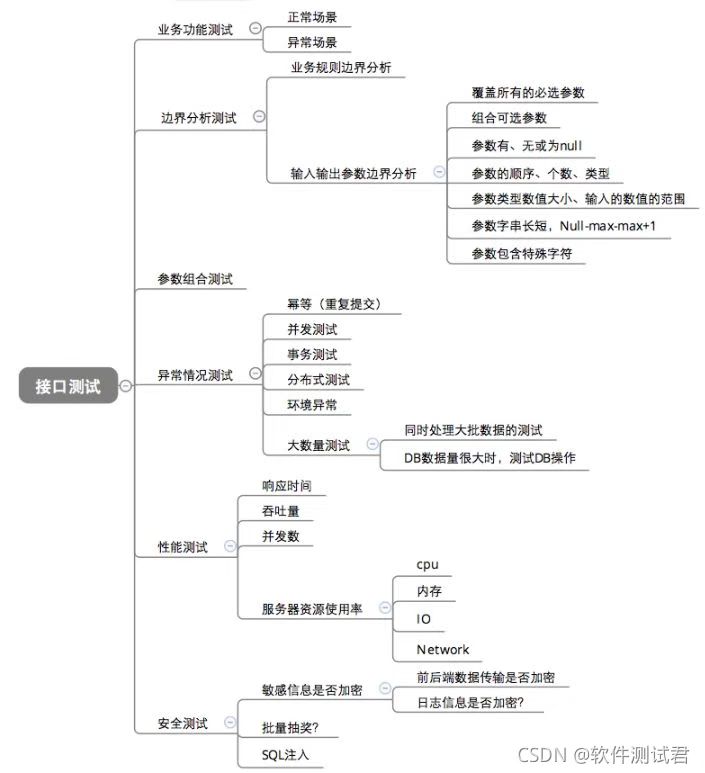
所有的接口测试,都涉及到这样的原则:
- 业务功能测试:正常场景、异常场景
- 边界值分析测试:业务规则边界分析、输入输出参数边界值分析(覆盖必选、组合可选、参数有无、参数顺序个数类型、参数类型数值大小,数值范围、参数字符串长短、特殊字符等等)
- 参数组合测试
- 异常情况测试:幂等、并发、事务、分布式、环境异常、大数据量测试
- 性能测试:响应时间、吞吐量、并发数、服务器资源使用率(CPU、内存、IO、网络)
- 安全测试:敏感信息是否加密、SQL注入等
三. 框架如何设计?自动化的目的?达到的效果?框架分层的目的?用例的参数化?数据驱动的实现?
-
框架如何设计
设计思想:数据和用例分离
如何实现:数据存储在excel中,通过openpyxl读取数据,封装成一个字典列表的形式,列表中的每一个字典都对应着一条case,通过ddt.data进行拆包,将每个元素分别传给封装好的request方法去做请求,拿到响应之后,将结果提取出来和期望结果做断言,最后通过unittest的loader方法,来收集测试用例,生成html报告 -
自动化的目的:
(1). 基于接口层面实现脱离手工的方式高效执行测试
(2). 接口自动化目的是提升效率
(3). 通过适当的验证来获得控制反馈,对系统变更有把握
(4). 方便回归测试
(5). 提高回归测试效率,保证质量
(6). 控制住接口质量,终端问题可以少很多
(7). 更早的发现问题
(8). 缩短测试周期
(9). 发现更底层的问题 -
达到的效果:
(1). 灵活高效。灵活指的是可以通过编码的方式为接口自动化框架新增功能,高效指的是通过代码实现接口自动化,可以提高接口测试效率
(2). 可复用性。通过数据和用例分离,配置和用例分离,实现了一次配置,运行多次,代码复用性高,接口变动时,只需要修改相关配置和数据就行
(3). 可维护性。不懂代码的同学也能快速上手,维护测试数据,扩展测试用例
(4). 可扩展性。如果要在自动化框架的基础上扩展测试平台,需要可扩展性比较强
(5). 可追溯性。接口运行有相关的日志和报告,出现问题可以溯源
(6). 持续集成。可以部署到jenkins上实现持续集成 -
框架分层的目的
(1). 能够管理系统公共的数据,系统发生变化后方便切换
(2). 能够实现接口层级的复用,提高接口自动化脚本的可维护性
(3). 能够实现接口之间的关联,也就是需要结果提取器
(4). 能够操作数据库处理数据(预制数据、清理垃圾数据)
(5). 能够实现测试用例的前置后置步骤(类似 unittest 的 setup 和 teardown)
(6). 各种灵活的预期结果比较器
(7). 测试脚本和框架代码完全分离,懂接口测试但是不懂代码的人一天即可完全掌握,超低的学习使用成本
(8). 支撑 http/https 协议的接口测试
(9). 灵活的扩展能力(自定义函数和自定义比较器) -
用例的参数化
(1). 随机数:使用${}的形式,在公共目录common下定义了一些随机数的方法,如果请求数据中有出现这样的形式,会调用替换函数做替换
(2). 关联接口:使用{{}}的形式,在公共目录common下的context.py中定义了一个公共类Context,在接口请求后,如果excel的用例中有response_extract字段,那么就分割这个字段对应的值,将=前的值作为Context的key、将=后的jsonpath表达式从响应结果里提取出来作为value,反射给Context类,在接口请求前,如果请数据里有{{}}的形式,会调用替换函数做替换
反射类:common/context.py
class Context:
pass
随机数类:common/random_generate.py
import time
class RandomGenerate:
def __init__(self):
self.timestamp = str(round(time.time_ns()))
#随机生成手机号
def random_phone(self):
random_phone = "131" + self.timestamp[-8:]
return random_phone
变量替换:common/replace_variable.py
from common.random_generate import *
from common.context import *
import re
class ReplaceVariable:
def replace_variable(params):
if params.find("${") != -1:
replace_string = eval("RandomGenerate().random_{0}()".format(re.sub("\d+", "", re.findall("\${(\\w+)}", params)[0])))
params = re.sub("\${\\w+}", replace_string, params)
elif params.find("{{") != -1:
replace_string = eval("Context.{0}".format(re.findall("{{(\\w+)}}", params)[0]))
params = re.sub("{{\\w+}}", replace_string, params)
return params
测试类:test_cases/test_my_request.py
#替换请求参数
request_data = json.loads(ReplaceVariable.replace_variable(case_data["request_data"][i]))
logging.info("请求数据: {0}".format(request_data))
#响应数据反射
response_extract = case_data["response_extract"][i]
if response_extract:
key, express = response_extract.split("=")
setattr(Context, key, str(jsonpath(result, express)[0]))
- 数据驱动的实现
类上面加装饰器:@ddt.ddt
方法上面加装饰器:@ddt.data(*all_case_data)
Linux
一. linux中的查看日志的命令
cat default.log
查询实时日志
tail -f default.log. 查看实时日志
tail -500f default.log 查看最后的500行的实时日志
tail -1000f default.log. 查看最后的1000行的实时日志
二. linux中查看文件中过滤关键字的命令
tail -f default.log | grep 关键字
三. 如何查看linux中日志关键字上下几行的日志
后10行
tail -f default.log | grep 关键字 -A 10
前10行
tail -f default.log | grep 关键字 -B 10
其他
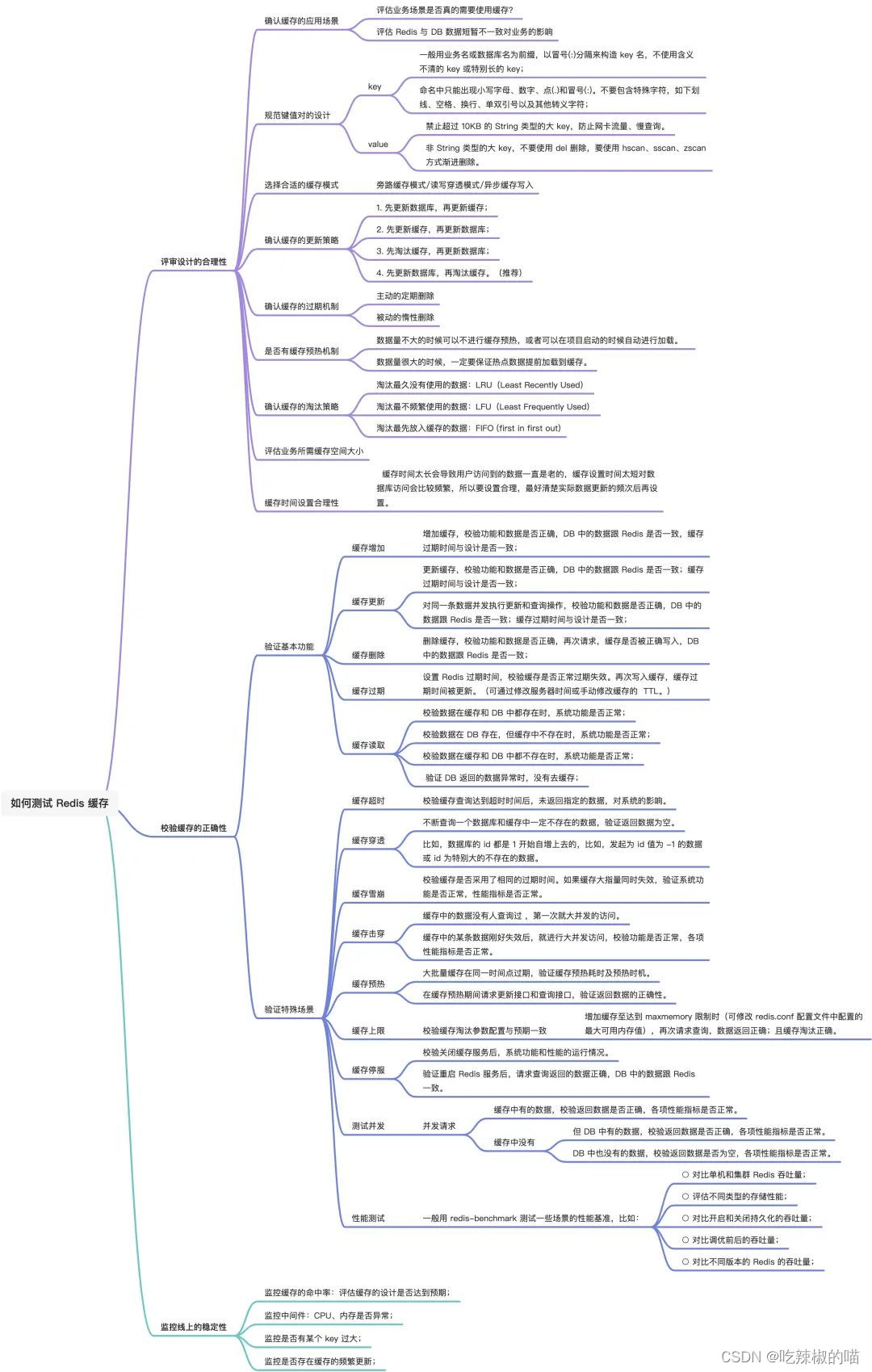
一. redis的作用?怎么测试?
- redis的作用
redis交换数据快,所以在服务器中常用来存储一些需要频繁调取的数据,这样可以大大节省系统直接读取磁盘来获得数据的I/O开销,更重要的是可以极大提升速度。redis 的应用场景包括:缓存系统(“热点”数据:高频读、低频写)、计数器、消息队列系统、排行榜、社交网络和实时系统
简而言之,就是加快访问速度,减少服务器和数据库压力
- 如何测试redis
二. kafka的作用?怎么测试?
- kafka的作用
- 流量削峰
- 系统节藕
- 异步处理
- 冗余存储
- 顺序性保障及回溯消费的功能
- 如何测试kafka
参考这一篇:《kafka测试方案》