centerNet的 创新点:
这是一种不需要使用anchor的网络结构,网络的输出使用的由3个head层所决定,第一个输出类别数,第二个输出中心点位置,第三个输出偏置项
(hm): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1)) ) (wh): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1)) ) (reg): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1)) )
我们先放置一张检测结果来进行演示
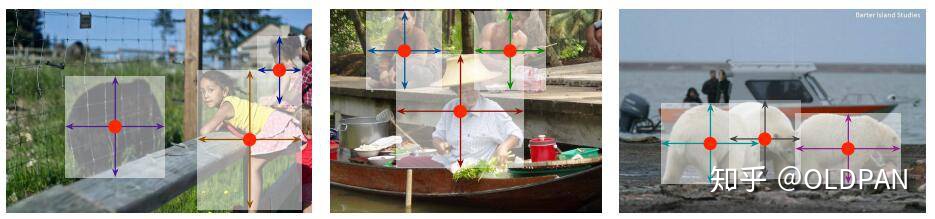
假设输入一张图的大小是640x640, 下采样的比例是4的话,那么卷积图的尺度是160x160
损失函数谈论
中心点预测损失函数
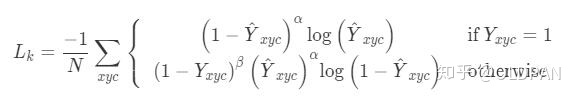
这里采用的也是focal loss的思想
第一种情况: 当是目标物体时,当 接近1的话,这个物体容易被识别出来,即(1-
)^a的值越小,即损失值也越小,使得权重偏向于更难训练的目标
第二种情况: 1.当不是目标物体时,假如此时的概率值是0.9,因为这个时候的概率值应该是0才对,我们使用( )^a进行惩罚,但是由于可能是中心点附件的位置,所以使用(1-Yxyc)^P 进行安慰一下
2.当不是目标物体时,假如此时的概率值是0.1, 对于( )^a进行奖励,使用(1-yxyc)^P进行惩罚,即离的越远,损失函数越大,离的越近,损失函数越小,这相当于弱化了实际中心点其他负样本的损失比重,相当于处理正负样本不平衡。
目标预测偏置损失函数
由于中心点直接采用的是特征图的中心点,因此在实际的缩放过程中,应该是需要有关于中心点位置的偏移量
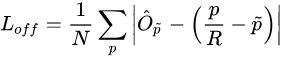
假设我们有一张640和320的图片,resize成512,512, 由于网络下采样的比例是4,因此缩放为128, 128,如果此时实际的中心是[98.97667,2.3566666],那么对应位置上的中心点的位置是98, 2, 由此可知,此时的偏移量应该是0.97667, 0.3566666,这里使用的就是L1 loss, 这个式子中 是我们预测出来的偏置,而
则是在训练过程中提前计算出来的数值
目标预测长宽损失函数
为了减少回归的难度,这里使用 作为预测值,使用L1损失函数,与之前的
损失一样:
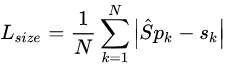
总的损失函数表达式
在论文中 ,然后
,论文中所使用的backbone都有三个head layer,分别产生[1,80,128,128]、[1,2,128,128]、[1,2,128,128],也就是每个坐标点产生
个数据,分别是类别以及、长宽、以及偏置。
推理阶段:
在一阶和二阶检测识别网络中,由于存在大量的anchor,因此很有可能存在一个关键点,有多个大于阈值的检测结果,但是这里我们一个特征点只对应一个检测目标,因此我们使用3x3的maxPool,判断当前的点是否比周围其他8个点都大,从中挑选出大于阈值的前100个点,作为最后的检测结果
最终的检测结果 阈值大于0.3的结果

不添加阈值的,前100个结果
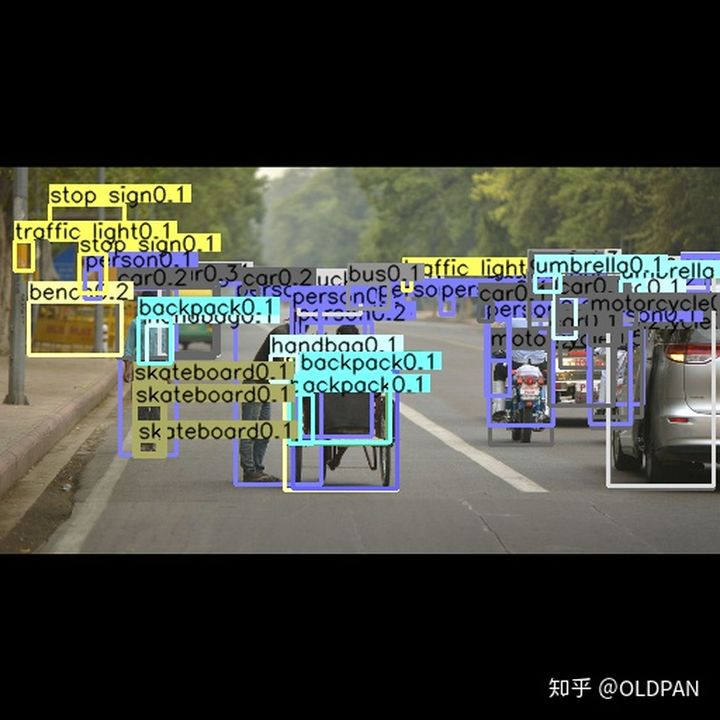
热力图
