1. ops = tf.train.GradientDescentOptimizer(learning_rate) 构建优化器
参数说明:learning_rate 表示输入的学习率
2.ops.compute_gradients(loss, tf.train_variables(), colocate_gradients_with_ops=True)
参数说明:loss表示损失值, tf.train_variables() 表示需要更新的参数, colocate_gradients_with_ops= True表示进行渐变的操作
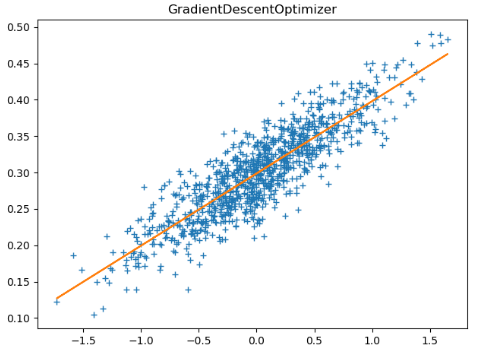
tf.train.GradientDescentOptimizer 梯度下降优化器
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt TRAIN_STEP = 20 data = [] num_data = 1000 for i in range(num_data): x_data = np.random.normal(0.0, 0.55) y_data = 0.1 * x_data + 0.3 + np.random.normal(0.0, 0.03) data.append([x_data, y_data]) # 第二步:将数据进行分配,分成特征和标签 X_data = [v[0] for v in data] y_data = [v[1] for v in data] learning_rate_placeholder = 0.5 # 初始学习率 global_step = tf.Variable(0, trainable=False) # 设置初始global_step步数 learning_rate = tf.train.exponential_decay(learning_rate_placeholder, global_step, 15, 0.1, staircase=True) W = tf.Variable(tf.truncated_normal([1], -1, 1), 'name') # 进行参数初始化操作 b = tf.Variable(tf.zeros([1])) logits = X_data * W + b # 构造拟合函数 loss = tf.reduce_mean(tf.square(y_data - logits)) # 使用平方和来计算损失值 opt = tf.train.GradientDescentOptimizer(learning_rate) # 构造梯度下降优化器 grad = opt.compute_gradients(loss, tf.trainable_variables(), colocate_gradients_with_ops=True) # 计算梯度,这里的trainable_variables()表示所有的参数,这里我们可以使用参数进行finetune操作 grad_opt = opt.apply_gradients(grad, global_step=global_step) # 进行global的迭代更新,同时构造更新梯度的操作 UPDATA_OP = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # 收集之前的操作 with tf.control_dependencies(UPDATA_OP): # 在进行训练操作之前先将保证其它操作做完 train_op = tf.group(grad_opt) # 进行操作的实例化,用于进行参数更新 sess = tf.Session() sess.run(tf.global_variables_initializer()) # 权重参数初始化操作 for i in range(TRAIN_STEP): sess.run(train_op) # 进行实际的参数更新操作 plt.plot(X_data, y_data, '+') # 画图操作 plt.plot(X_data, X_data*sess.run(W) + sess.run(b), '-') plt.show()
tf.train.AdamOptimizer 自适应学习率梯度下降

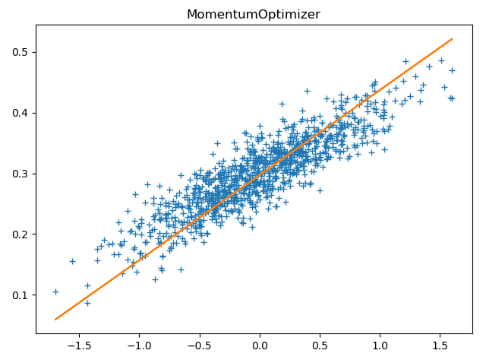
tf.train.MomentumOptimizer(learning_rate, 0.7) 动量梯度下降
原理说明:

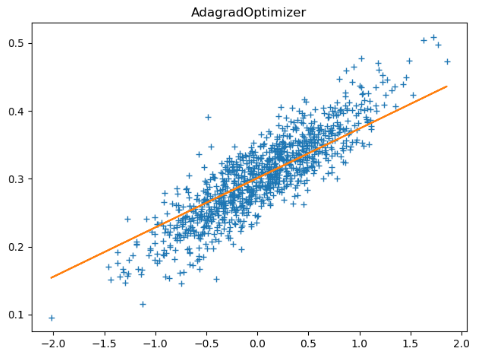
tf.train.AdagradOptimizer Adagra算法的学习率增加