1. csv.reader(csvfile) # 进行csv文件的读取操作
参数说明:csvfile表示已经有with oepn 打开的文件
2. X.tolist() 将数据转换为列表类型
参数说明:X可以是数组类型等等
代码说明:使用的是单层的rnn网络,迭代的终止条件为,第n的100次循环的损失值未降低次数超过3次,即跳出循环
数据说明:使用的是乘客的人数,训练集和测试集的分配为0.8和0.2, train_x使用的是前5个数据,train_y使用的是从2个数据到第6个数据,以此往后类推
代码:
第一部分:数据的读入,并将数据拆分为训练集和测试集,同时构造train_x, train_y, test_x, test_y, 每一个train的大小为5, 1
第二部分:实例化模型,同时对模型进行训练操作
第三部分:进行模型的测试,这里分为两种情况,一种是每5个测试集数据预测每5个结构,第二种是使用train的最后5个数据进行预测,将预测结果的最后一个数,与用于预测的后4个数据进行拼接,作为下一次预测的5个数,进行预测
第一部分:数据的读入:
第一步:使用csv.reader(csvfile) 进行csv文件的读取,使用[float(row[0] for row in data if len(row)>0)], 同时对数据进行归一化的操作
第二步:构造数据切分的函数,把数据分为训练集和测试集
第三步:将数据构造为[None, 5, 1] 每一列数据有5个数,比如以前5个数据为train_x, 第2个数据到第六个数据为train_y, 以此类推
np.expand_dim(train_data[i:i+seq_size], axis=1).tolist() , 将train_data 和 test_data 进行切分
第二部分:rnn模型的训练:
第一步:实例化模型
第一步:对输入的Input_dim, seq_size, num_hidden进行self的操作
第二步:使用tf.placeholder(tf.placeholder, [None, seq_size, input_dim]) 初始化输入参数
第三步:使用tf.Variable(tf.truancate_normal([num_hidden, 1]), name='W_out') 初始化变换W_out和b_out
第四步:构造self.model(), 用于获得预测值y_pred
第一步:使用rnn.BasicLSTM构造cell
第二步:使用tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32) 获得outputs和states
第三步:对self.W_out使用tf.expand_dim添加维度, 使用tf.tile将维度变为[?, 10, 1] 因为self.x的维度为[?, 4, 10]
第四步:使用tf.matmul(self.x, self.W_out) + self.b_out 获得输出的结果
第五步:使用tf.squeeze(out) 对矩阵的维度进行压缩,将[?, 4, 1] 变为[?, 4], 返回结果
第五步:使用均方根误差作为损失值,即tf.reduce_mean(tf.square(self.y - self.model()))
第六步:定义self.train_op, 使用自适应梯度下降进行损失值的降低
第七步:定义self.Saver
第二步:进行模型的训练操作
第一步:使用with 构造sess函数
第二步:使用tf.get_varaible_scope().reuse_variable()进行模型参数的复用
第三步:使用sess.run(tf.global_) 进行模型参数的初始化
第四步:定义max_patience = 3, 定义test_loss = float('inf')最小损失值
第五步:循环,当patience > 0时, sess.run(train_op) 降低损失值,如果迭代操作一百次,就判断当前的损失值是否小于最小损失值,如果是,将patince重新变为max_patince, 当前损失值等于最小损失值, 如果不是,patince -= 1
第三步:构造模型的预测函数
这里将sess也进行输入,以便后续的操作
第一步:使用tf.get_variable_scope().reuse_variable() 进行模型参数的复用
第二步:使用self.Saver.save对sess进行重新的加载
第三步:使用sess.run() 执行self.model输入参数为test_x, 输出结果为out
第三部分:对结果进行测试,并进行画图操作,这里有两种情况,使用前5个预测第二个到第六个,输出结果以及使用预测出来结果的最后一个拼接到用于预测的后4个,作为新的输入进行预测
第一步:使用predictor.test() 进行测试集test_x的测试
第二步:将train_data, 测试的结果以及test_data进行画图操作
第三步:pred_series第一个测试数据为train[-1]
第四步:循环20次,predictor.test(sess, pred_series)获得测试的结果,next_seq
第五步:将测试结果的最后一个数添加到列表中,以便后续作图
第六步:将测试结果的最后一个数与用于进行预测的后4个数,使用np.vstack() 进行拼接
代码:rnn_ts.py
import tensorflow as tf import numpy as np import data_loader from tensorflow.contrib import rnn import matplotlib.pyplot as plt class SeriesPredictor: def __init__(self, input_dim, seq_size, num_hidden): # 将输入变为self类型 self.input_dim = input_dim self.seq_size = seq_size self.num_hidden = num_hidden # 使用tf.placeholder()对输入进行初始化,维度为[None, seq_size, dim] self.x = tf.placeholder(tf.float32, [None, seq_size, input_dim]) self.y = tf.placeholder(tf.float32, [None, seq_size]) # 使用tf.Variable()对w和b进行初始化 self.W_out = tf.Variable(tf.random_normal([num_hidden, 1]), name='W_out') self.b_out = tf.Variable(tf.constant(0.1, shape=[1]), name='b_out') # 使用self.model()的预测返回值来构造均分误差损失值 self.loss = tf.reduce_mean(tf.square(self.model() - self.y)) # 构造损失值的梯度下降操作 self.train_op = tf.train.AdamOptimizer().minimize(self.loss) # 构建模型的保存 self.Saver = tf.train.Saver() # 用于输出模型的预测结果 def model(self): # 构造单层的rnn网络 cell = rnn.BasicLSTMCell(self.num_hidden) # 使用tf.nn.dynamic_rnn输出网络的结构 outputs, states = tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32) # 获得输入的self.x的大小 num_examples = tf.shape(self.x)[0] # 将self.W_out添加一个维度 tf_expand = tf.expand_dims(self.W_out, axis=0) # 将添加的维度转换为和self.x相同大小的维度即[None,10, 1] tf_tile = tf.tile(tf_expand, [num_examples, 1, 1]) # 输出预测的结果 out = tf.matmul(outputs, tf_tile) + self.b_out # 对预测结果的维度进行压缩 out = tf.squeeze(out) # 返回预测结果 return out # 构造训练函数 def train(self, train_x, train_y, test_x, test_y): # 使用with 构造sess with tf.Session() as sess: # 进行参数的复用 tf.get_variable_scope().reuse_variables() # 构造模型的初始化 sess.run(tf.global_variables_initializer()) # 定义最大的次数 max_patience = 3 patience = max_patience # 定义最小损失值 min_mse = float('inf') i = 0 # 如果patince > 0,将进行一直的迭代 while patience > 0: # 进行模型的参数下降的操作 sess.run(self.train_op, feed_dict={self.x:train_x, self.y:train_y}) # 如果迭代一百次 if i % 100 == 0: # 计算test的损失值 test_mse = sess.run(self.loss, feed_dict={self.x:test_x, self.y:test_y}) print(i, test_mse) # 如果test的损失值小于最小损失值 if test_mse < min_mse: # patince重置为最大patience patience = max_patience # 将最小损失值替换为当前损失值 min_mse = test_mse else: # 否者patince将减小 patience -= 1 i = i + 1 # 将模型sess进行保存 path_sess = self.Saver.save(sess, './model') print('the sess save path is {}'.format(path_sess)) # 第三步:构造模型预测函数 def test(self, sess, test_x): # 进行参数的复用 tf.get_variable_scope().reuse_variables() # 将sess进行重新的加载 self.Saver.restore(sess, './model') # 使用sess执行self.model() 操作 out = sess.run(self.model(), feed_dict={self.x:test_x}) return out # 定义绘图函数 def plot_results(train_x, predictions, test_data, filename): plt.figure() num_exmaple = len(train_x) # 绘制训练集函数train_data plt.plot(list(range(num_exmaple)), train_x, label='train_x', c='r') # 绘制测试集预测的结果 plt.plot(list(range(num_exmaple, num_exmaple + len(predictions))), predictions, label='predictions', c='b') # 绘制测试集test_data plt.plot(list(range(num_exmaple, num_exmaple + len(test_data))), test_data, label='test_data', c='g') plt.legend() if filename: plt.savefig(filename) else: plt.show() # 数据准备 if __name__ == '__main__': seq_size = 5 # 第一部分:数据的准备 # 第一步:进行数据的加载操作 data = data_loader.load_series('international-airline-passengers.csv') # 第二步:进行数据的切分 train_data, test_data = data_loader.split_data(data) # 第三步:使用np.expand_dims将数据维度变化为[5, 1], 将train数据进行平推式的添加 train_x, train_y = [], [] for i in range(len(train_data) - 1 - seq_size): train_x.append(np.expand_dims(train_data[i:i+seq_size], axis=1).tolist()) train_y.append(train_data[i+1:i+1+seq_size]) test_x, test_y = [], [] for i in range(len(test_data) - 1 -seq_size): test_x.append(np.expand_dims(test_data[i:i+seq_size], axis=1).tolist()) test_y.append(test_data[i+1:i+1+seq_size]) # 第二部分:进行模型的训练 # 第一步:模型的实例化操作 predictor = SeriesPredictor(input_dim=1, seq_size=seq_size, num_hidden=10) # 第二步:进行模型的训练 predictor.train(train_x, train_y, test_x, test_y) # 第三部分:进行模型的预测 with tf.Session() as sess: # 进行模型的预测,使用预测结果的第一个位置进行画图操作 predictor_val = predictor.test(sess, test_x) predictor_val_last = predictor_val[:, 0] # 进行画图操作 plot_results(train_data, predictor_val_last, test_data, 'predictions.png') # 取训练数据的最后一组数据作为第一个测试数据 prev_seq = train_x[-1] pred_list = [] # 循环 for i in range(20): # 获得预测结果 next_seq = predictor.test(sess, [prev_seq]) # 将预测结果的最后一个结果与测试数据的前4个结果进行组合 prev_seq = np.vstack([prev_seq[1:], next_seq[-1]]) # 将测试结果的最后一个数据添加,以便进行画图 pred_list.append(next_seq[-1]) # 进行画图操作 plot_results(train_data, pred_list, test_data, 'predictions1.png')
data_loader.py
import numpy as np import csv def load_series(filename, dataidx = 1): # 打开文件f with open(filename) as cvsfile: # 使用csv.reader对打开的文件进行读取 csvreader = csv.reader(cvsfile) # 只选择每一行的第二个数据组成列表 data = [float(passage[dataidx]) for passage in csvreader if len(passage) > 0] # 对数据进行归一化操作 normalized_data = (data - np.mean(data)) / np.std(data) return normalized_data # 将数据切分成训练集和测试集 def split_data(data, train_size=0.8): # 数据的大小 num_data =len(data) train_data, test_data = [], [] # 循环数据 for i, x in enumerate(data): # 如果索引值小于训练集的比例,将数据添加到训练集 if i < num_data * train_size: train_data.append(x) # 否者添加到测试集 else: test_data.append(x) return train_data, test_data if __name__ == '__main__': data = load_series('international-airline-passengers.csv')
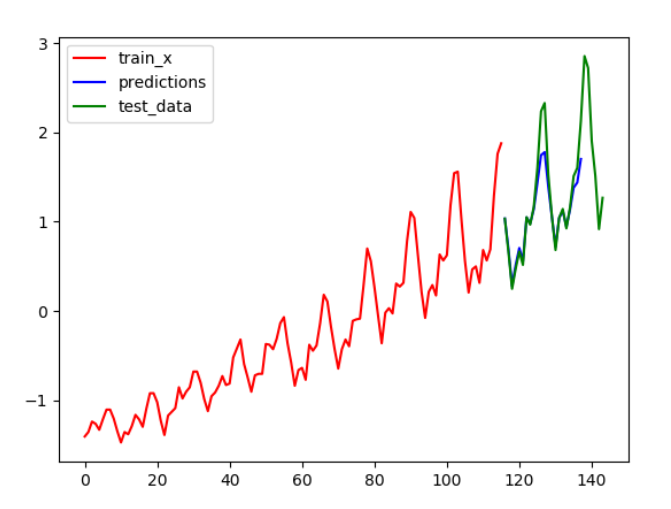

预测的结果 预测结果再进行预测