函数说明:
1. .hist 对于Dataframe格式的数据,我们可以使用.hist直接画出直方图
对于一些像年龄和工资一样的连续数据,我们可以对其进行分段标记处理,使得这些连续的数据变成离散化
就好比:我们可以将0-9岁用0表示
10-19用1表示
20-29用2表示
...
下面我们对一个年龄数据进行了分段标记处理
代码:
第一步:导入数据
第二步:对年龄特征使用.hist画出直方图,直方图本身也是一个分段的过程
第三步:使用np.floor(/10)取整,将比如5岁的年龄计算后为0
第四步:将特征放入原数据中,进行展示
import pandas as pd import matplotlib.pyplot as plt import numpy as np # 第一步 fcc_survey_df = pd.read_csv('datasets/fcc_2016_coder_survey_subset.csv') # 对年龄特征进行分段标记:比如0-9分为0, 10-19为1.... # 先对年龄字典画直方图,直方图本身也是一种分段过程 # 第二步 fig, ax = plt.subplots() fcc_survey_df['Age'].hist(color='#A9C5D3') ax.set_xlabel('Age') ax.set_ylabel('Frequency') ax.set_title('Age bins') plt.show()
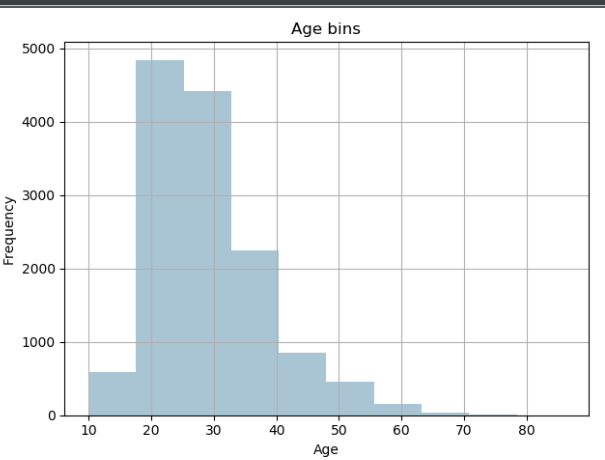
# 第三步我们使用/10取整对年龄字段进行分段处理 Age_bins = np.floor(fcc_survey_df['Age'].values / 10) # 第四步:将列表放入原数据中进行展示 fcc_survey_df['Age_bins'] = Age_bins print(fcc_survey_df[['Age', 'Age_bins']].head())
