一、安装与配置
- 安装python包
pip install django-haystack
pip install whoosh
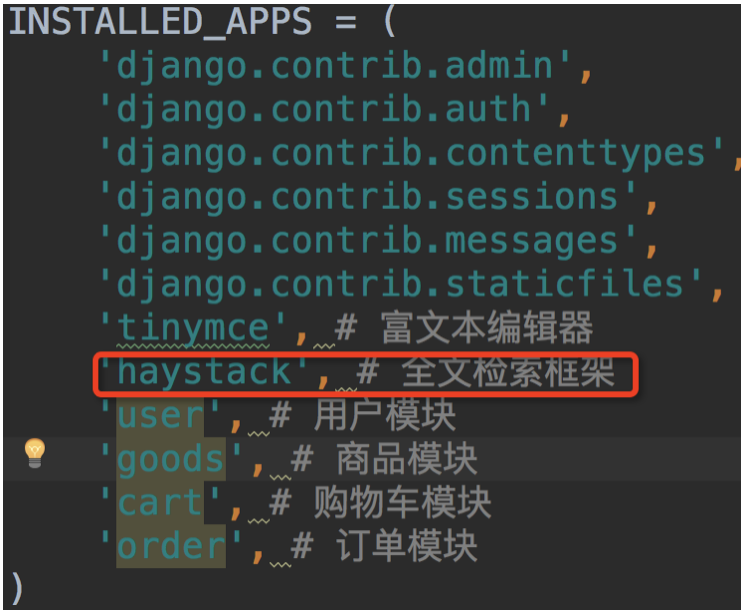
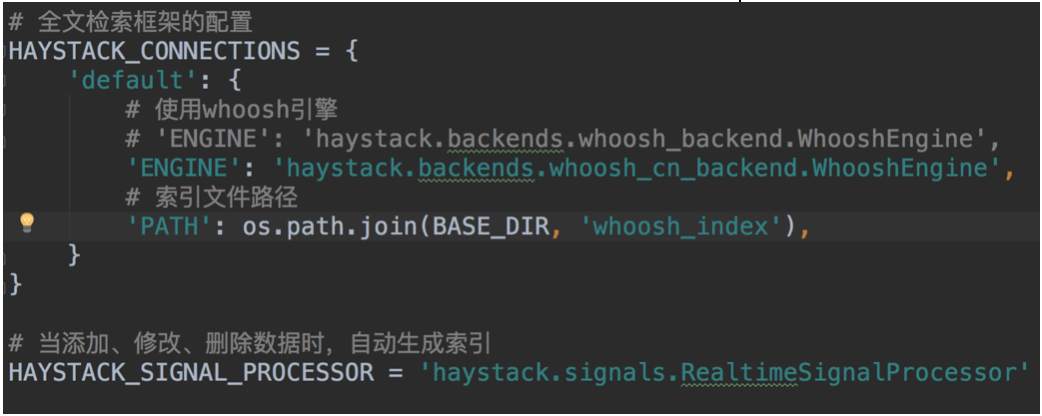
- 在settings.py文件中注册应用haystack并做如下配置
二、索引文件生成
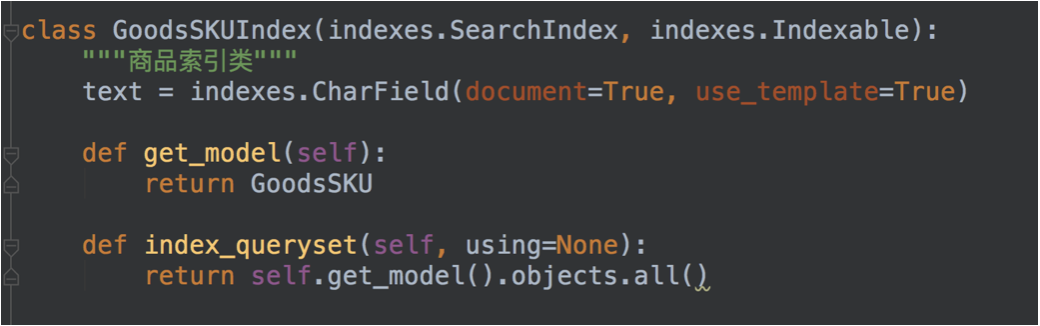
- 在goods应用目录下新建一个search_indexes.py文件,在其中定义一个商品索引类
- 在templates下面新建目录search/indexes/goods
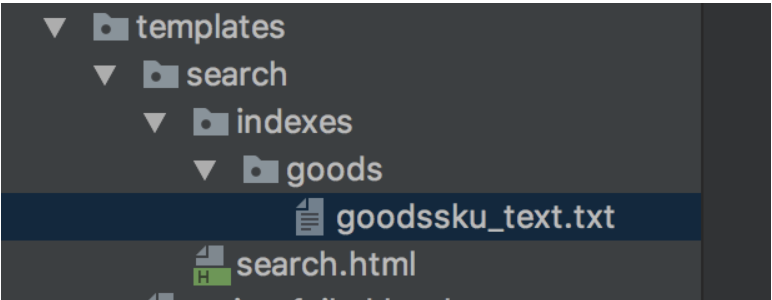
- 在此目录下面新建一个文件goodssku_text.txt并编辑内容如下
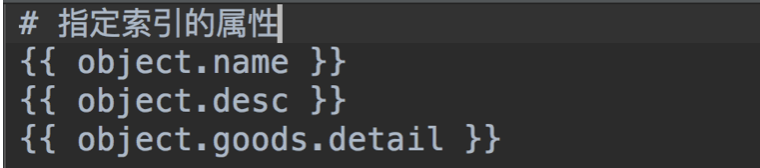
- 使用命令生成索引文件
python manage.py rebuild_index
三、全文检索的使用
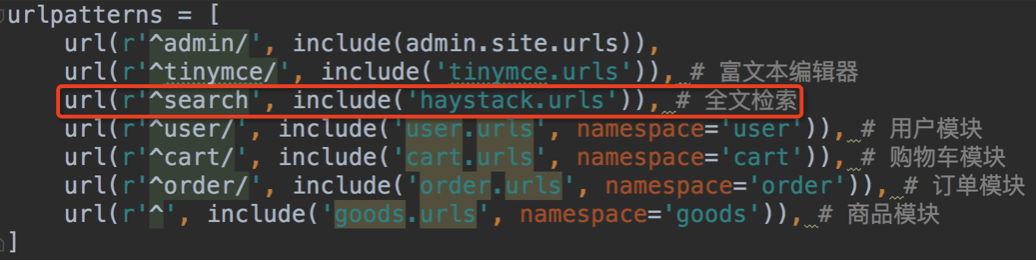
1. 配置url
2. 表单搜索时设置表单内容如下

点击标题进行提交时,会通过haystack搜索数据
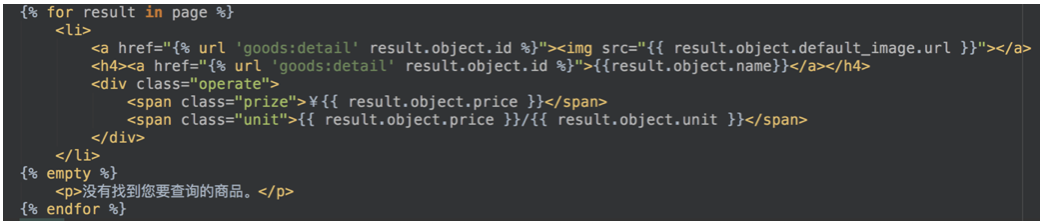
- 全文检索结果
搜索出结果后,haystack会把搜索出的结果传递给templates/search目录下的search.html,传递的上下文包括:
query:搜索关键字
page:当前页的page对象 –>遍历page对象,获取到的是SearchResult类的实例对象,对象的属性object才是模型类的对象。
paginator:分页paginator对象
通过HAYSTACK_SEARCH_RESULTS_PER_PAGE 可以控制每页显示数量。
四、改变分词方式
1. 安装jieba分词模块。
pip install jieba
- 找到虚拟环境py_django下的haystack目录。
/home/python/.virtualenvs/bj17_py3/lib/python3.5/site-packages/haystack/backends/
- 在上面的目录中创建ChineseAnalyzer.py文件。
1 import jieba 2 3 from whoosh.analysis import Tokenizer, Token 4 5 6 class ChineseTokenizer(Tokenizer): 7 8 def __call__(self, value, positions=False, chars=False, 9 10 keeporiginal=False, removestops=True, 11 12 start_pos=0, start_char=0, mode='', **kwargs): 13 14 t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) 15 16 seglist = jieba.cut(value, cut_all=True) 17 18 for w in seglist: 19 20 t.original = t.text = w 21 22 t.boost = 1.0 23 24 if positions: 25 26 t.pos = start_pos + value.find(w) 27 28 if chars: 29 30 t.startchar = start_char + value.find(w) 31 32 t.endchar = start_char + value.find(w) + len(w) 33 34 yield t 35 36 37 def ChineseAnalyzer(): 38 39 return ChineseTokenizer()
- 复制whoosh_backend.py文件,改为如下名称。
whoosh_cn_backend.py
- 打开复制出来的新文件,引入中文分析类,内部采用jieba分词。
from .ChineseAnalyzer import ChineseAnalyzer
- 更改词语分析类。
查找
analyzer=StemmingAnalyzer()
改为
analyzer=ChineseAnalyzer()
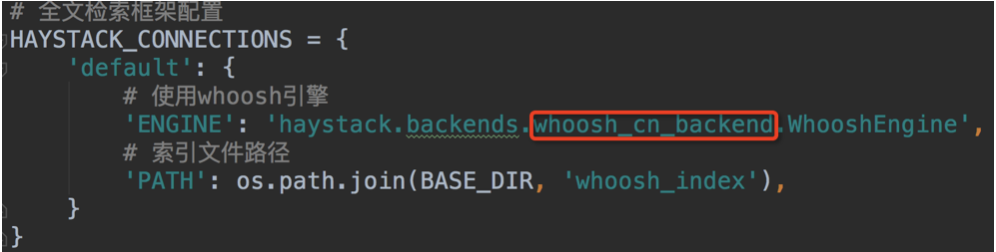
- 修改settings.py文件中的配置项。
- 重新创建索引数据
python manage.py rebuild_index