一、背景介绍:
运行在k8s集群中负责支付业务一个服务,运营一段时间就会被k8s kill,然后重启, 通过查看k8s 的event发现系统达到了memory到达了上限被集群kill调。
服务配置:jdk:1.8、堆内存:-Xmx800m -Xms800m 设置为800M, k8s的memory.limit设置为1G。
二、排查问题:
1.初步分析: 由于系统的请求量不大,所以设置的堆内存足够了,所以可以排除堆内存设置过小原因。同时由于服务被kill的原因是因为物理内存占用过大。所以怀疑是堆外内存溢出。
jvm内存结构分为:堆内存(新生代、老年代), 堆外内存(线程栈、元空间、直接内存)
2.排查:
2.1 gc状态分析:jstat -gcutil pid 5s
结果:各区域的占用情况,gc情况无明显异常
2.2 堆dump: jmap -dump:format=b,file=heap.hprof pid, 使用mat分析如下:
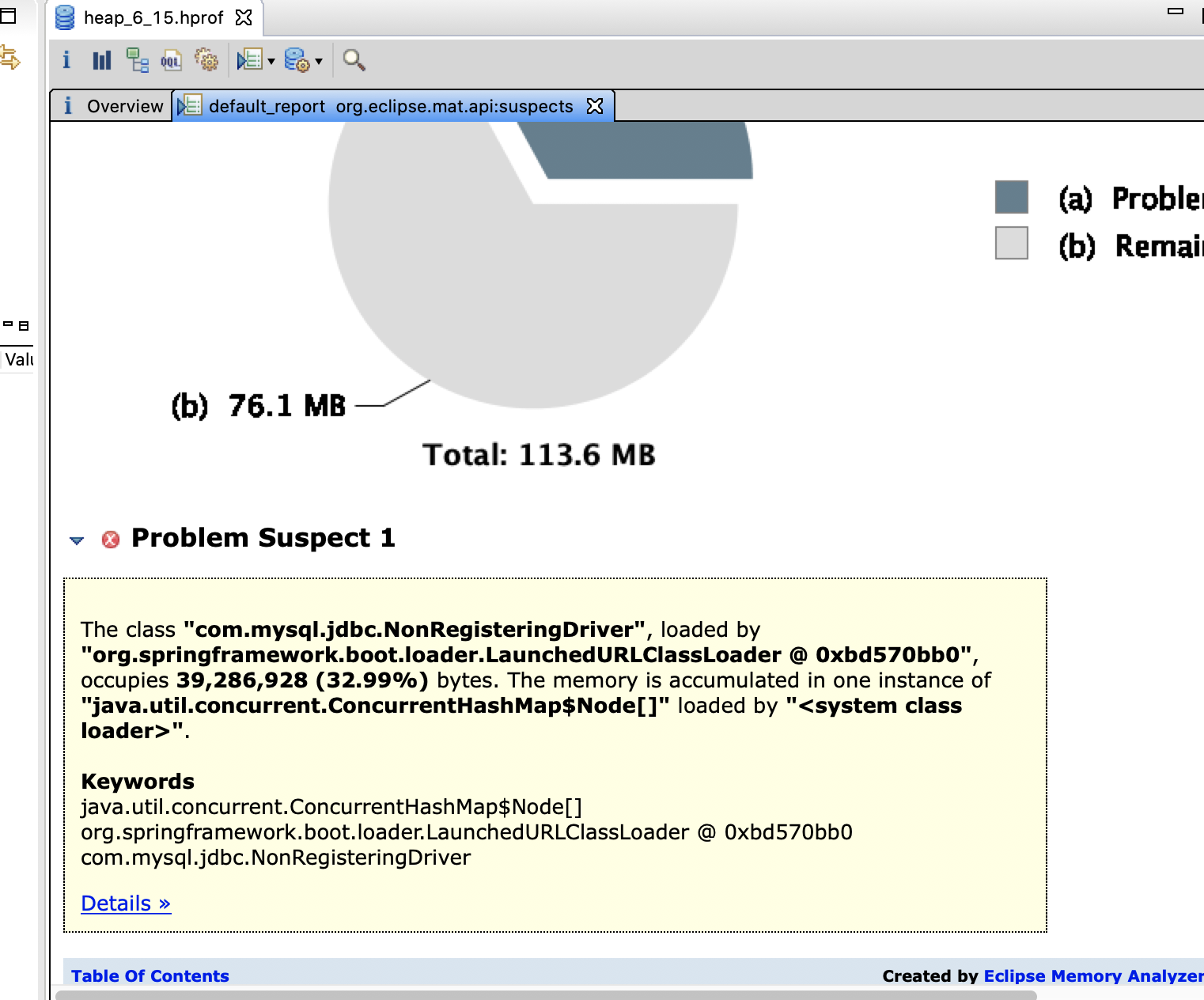
很明显 com.mysql.jdbc.NonRegisteringDriver占用堆内存的33%。其中java.util.concurrent.ConcurrentHashMap$Node[] 存在内存泄漏的可能。
ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs 保存mysql connection的虚引用。
当 mysql connection被释放后,虚引用的refQueue中会收到释放的connection。 定时清理线程会取出refQueue中保存的connection,然后将connection从 connectionPhantomRefs中清除。
当查看详细情况发现: connectionPhantomRefs 保存的连接个数600多个,而mysql的tomcat的连接池最大设置的max-active=100,
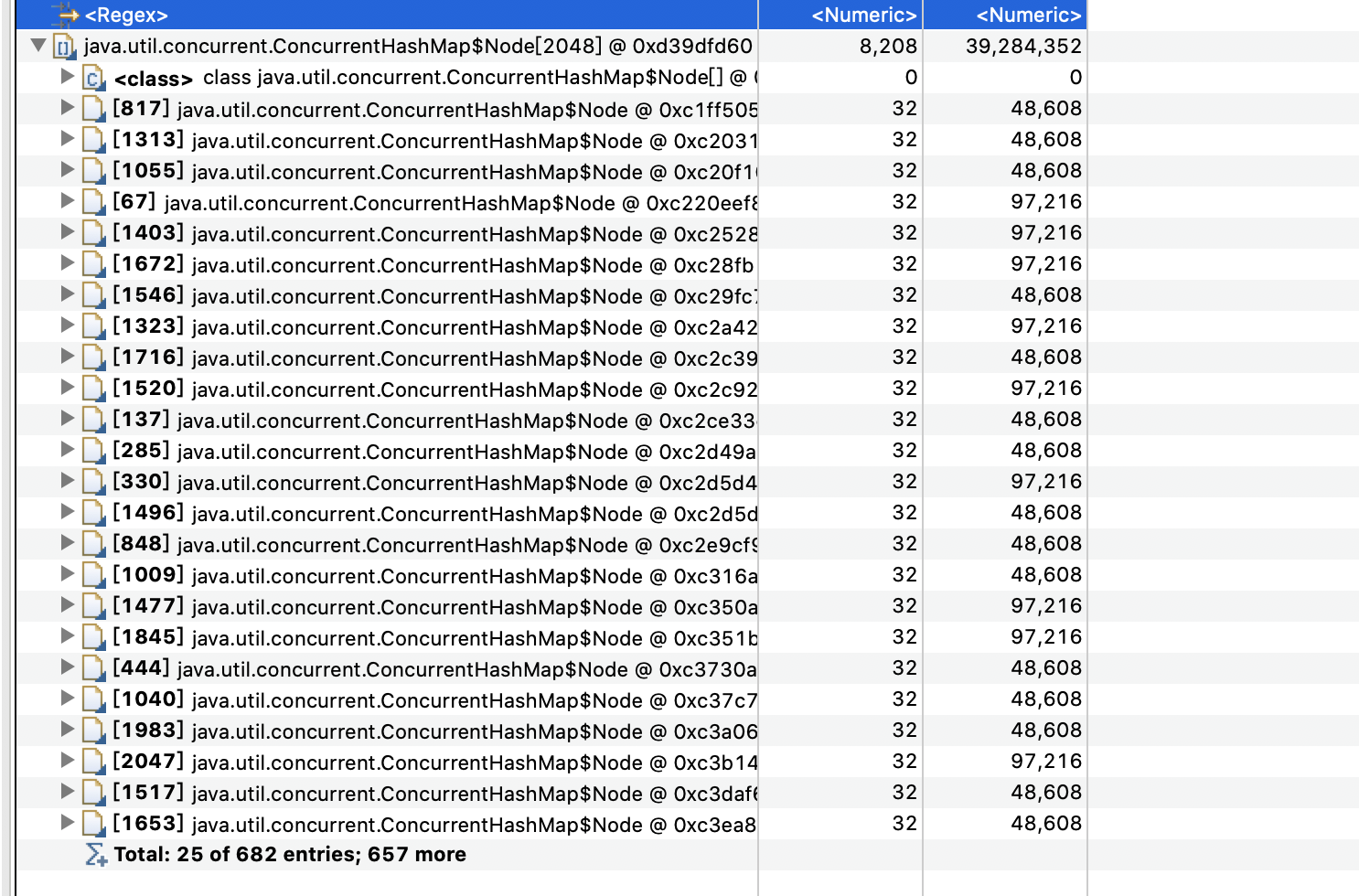
这说明了两个问题:
- 1. 有大部分的连接池没有被回收
- 2. 最大连接数max-active:100,而实际生成的却远远大于max-active
2.3 连接池配置分析
根据2.2中堆dump的情况发现了两个问题:
- (1) 有大部分的连接池没有被回收
- (2)最大连接数max-active:100,而实际生成的却远远大于max-active,
关于问题(1):通过jstat -gcutil pid 5s发现jvm old区占用50%,一直没有FGC。 通过jcmd GC.run手动gc后,再次dump发现om.mysql.jdbc.NonRegisteringDriver保存的连接数目减少了
关于问题(2): 通过排查,发现tomcat连接池设置的最大生命周期 max-age:60000, 即连接创建一分钟后就会被销毁。
三、解决问题:
1. 增加连接池超时时间,超时时间稍微小于mysql的waitTimeout即可
2. jvm迟迟没有fgc导致连接池中连接没有释放,可以稍微调小堆内存
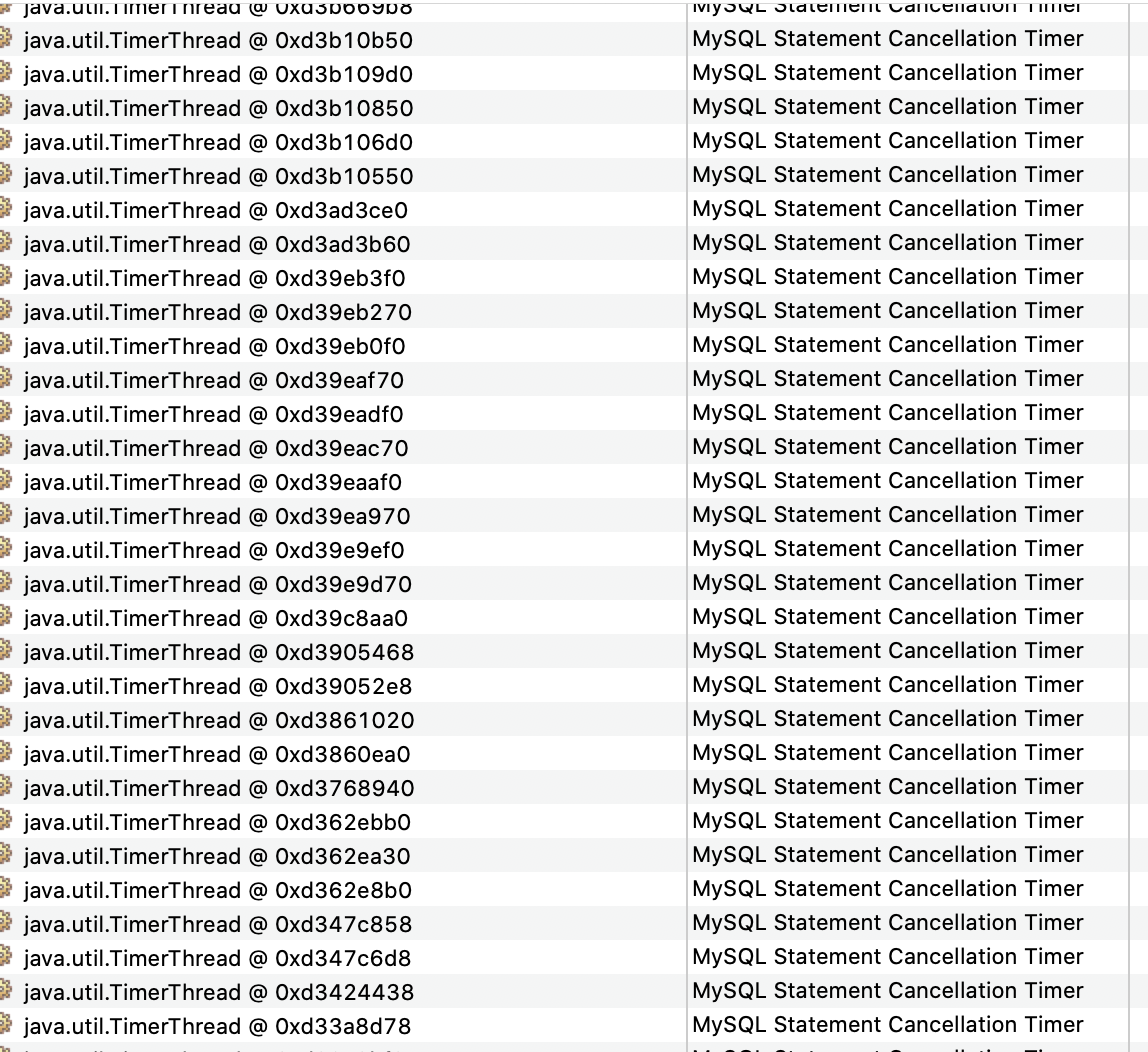
3. 回归到最开始的疑问,为什么会是堆外内存溢出呢? 通过堆外内存几个区域的分析,发现其中大量的MysqlStatement Cancellation Timer:
mysql每个连接一个超时检测线程用于检测sql语句是否超时,mysql的连接没有释放导致线程也未释放。 而线程栈占用默认大小为1m,所以导致了堆外内存溢出