2019.05.08
1.面向对象的内存分析
java虚拟机的内存可以分为三个区域:栈stack、堆heap、方法区method area
(1)栈的特点如下:
1.栈描述的是方法执行的内存模型。每个方法被调用都会创建一个栈帧(存储局部变量、操作数、方法出口等)。
2.JVM为每个线程创建一个栈,用于存放该线程执行方法的信息(实际参数、局部变量等)。
3.栈属于线程私有,不能实现线程间的共享。
4.栈的存储特性是“先进后出,后进先出”。
5.栈由系统自动分配,速度快,是一个连续的内存空间。
(2)堆的特点如下:
1.堆用于存储创建好的对象和数组(数组也是对象)。
2.JVM只有一个堆,被所有线程共享。
3.堆是一个不连续的内存空间,分配灵活,速度慢。·
(3)方法区(又叫静态区)特点如下:
1.JVM只有一个方法区,被所有线程共享。
2.方法区实际也是堆,只是用于存储类、常量相关的信息。
3.用来存放程序中永远不变或唯一的内容。(类信息【class对象】、静态变量、字符串常量等)。
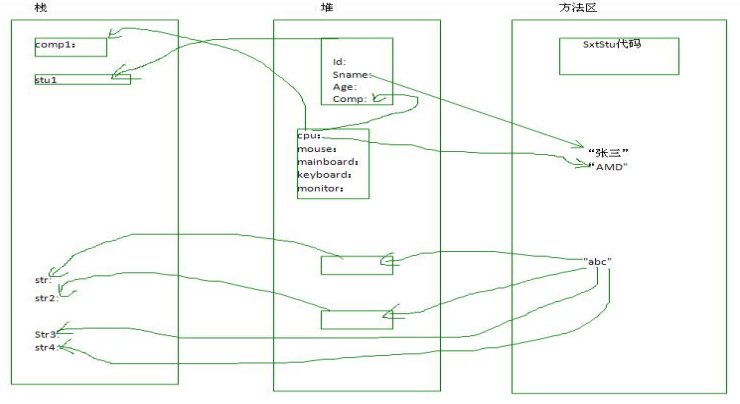
2.创建一个对象分为如下四步:
(1)分配对象空间,并将对象成员变量初始化为0或空。
(2)执行属性值的显式初始化
(3)执行构造方法
(4)返回对象的地址给相关的变量
3.this关键字
this的本质就是“创建好的对象的地址”由于在构造方法调用前,对象已经创建。因此,在构造方法中也可以使用this代表“当前对象”。
在类中,用static声明的成员变量为静态成员变量,也称为类变量。类变量的生命周期和类相同,在整个应用程序执行期间都有效。
5.重写与重载
6.构造方法调用顺序
构造方法第一句总是:super(...)来调用父类对应的构造方法。所以流程就是:先向上追溯到Object,然后再依次向下执行类的初始化块和构造方法,直到当前子类位置。
静态初始化块调用顺序,与构造方法调用顺序一样。
7.多态
多态指的是同一个方法调用,由于对象不同可能会有不同的行为。现实生活中,同一个方法,具体实现会完全不同。
多态的要点:
(1)多态是方法的多态,不是属性的多态(多态与属性无关)
(2)多态的存在要有三个必要条件:继承、方法重写、父类引用指向子类对象。
(3)父类引用指向子类对象后,用该父类引用调用子类重写的方法
8.final关键字
2019.05.09
1.抽象类
(1)使用要点:
有抽象方法的类只能定义成抽象类
抽象类不能实例化,即不能new来实例化抽象类
抽象类可以包含属性、方法、构造方法。但构造方法不能用来new实例,只能用来被子类调用
抽象类只能用来被继承
抽象方法必须被子类实现
(2)相关规定
抽象类也提供构造方法,并且子类也遵循对象实例化流程:先调用父类构造方法,再调用子类构造方法
抽象类中可以不定义抽象方法,但仍然无法直接实例化对象
abstract与final、private不能一起使用:
final声明的类不允许有子类,而abstract抽象类必须有子类
抽象方法必须要被重写,因此不能用private封装
抽象类也分为内部抽象类和外部抽象类:内部抽象类允许使用static
2.接口
(1)详细说明
访问修饰符:只能是public或默认
接口名:和类名采用相同命名机制
extends:接口可以多继承
常量:接口中的属性只能是常量,总是:public static final修饰
方法:接口中的方法只能是:public abstract
(2)要点
子类通过implements来实现接口中的规范
接口不能创建实例,但是可用声明引用变量类型
一个类实现了接口,必须实现接口中所有的方法,并且这些方法只能是public的
JDK1.7之前,接口中只能包含静态常量、抽象方法,不能有普通属性、构造方法、普通方法
JDK1.8后,接口包含普通的静态方法
3.非静态内部类
(1)非静态内部类必须寄存在一个外部类对象里,因此,如果有一个非静态内部类对象那么一定存在对应的外部类对象,非静态内部类对象单独属于外部类的某个对象。
(2)非静态内部类可以直接访问外部类的成员,但是外部类不能直接访问非静态内部类成员
(3)非静态内部类不能有静态方法,静态属性和静态初始化块
(4)外部类的静态方法,静态代码块不能访非静态内部类,包括不能使用非静态内部类定义变量,创建实例。why:非静态内部类依托于外部类对象
(5)成员变量访问要点:
内部类里方法的局部变量:变量名
内部类属性:this.变量名
外部类属性:外部类名.this.变量名
4.静态内部类(不依托外部类对象)
(1)当一个静态内部类对象存在,并不一定存在对应的外部类对象。因此,静态内部类的实例方法不能直接访问外部类的实例方法
(2)静态内部类看做外部类的一个静态成员。因此,外部类的方法中可以通过:静态内部类.名字的方式访问静态内部类的静态成员,通过new静态内部类()访问静态内部类的实例。
5.匿名内部类
适合只需要使用一次的类。比如:键盘监听操作等等
interface AA { void aa(); } public class TestAnonymousInnerClass { public static void test01(AA a){ a.aa(); } public static void main(String[] args) { TestAnonymousInnerClass.test01(new AA(){ @Override public void aa() { System.out.println("TestAnonymousInnerClass.main(...).new AA() {...}.aa()"); } }); } }
6.方法内部类
方法内部类定义在方法内部,作用域只限于方法,称为局部内部类
2019.05.10
1.包装类
java是面向对象语言,但并不是“纯面向对象”的,因为我们经常用到的基本数据类型就不是对象,但是我们在实际应用中经常需要将基本数据转化成对象,以便于操作。比如:将基本数据类型存储到Object[]数组或集合中的操作等等。
为了解决这个不足,java在设计类时为每个基本数据类型设计了一个对应的类进行代表,这样八个和基本数据类型对应的类统称为包装类。
| 基本数据类型 | 包装类 |
| byte | Byte |
| boolean | Boolean |
| short |
Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double |
Double |
相互转化:
public class TestWrappedClass { public static void main(String[] args) { //基本数据类型转成包装类对象 Integer a = new Integer(3); Integer b = Integer.valueOf(30); //把包装类对象转成基本数据类型 int c = b.intValue(); double d = b.doubleValue(); //把字符串转成包装类对象 Integer e = new Integer("9999"); Integer f = Integer.parseInt("999888"); //把包装类对象转成字符串 String str = f.toString(); //""+f //常见的常量 System.out.println("int类型最大的整数:"+Integer.MAX_VALUE); } }
2.自动装箱、自动拆箱
自动装箱和拆箱就是编译器将基本数据类型和包装类之间进行自动的互相转换(JDK1.5以后)
public class TestAutoBox { public static void main(String[] args) { Integer a = 234; //自动装箱。Integer a = Integer.valueOf(234); int b = a; //自动拆箱。编译器会修改成:int b = a.intValue(); Integer c = null; if(c!=null){ int d = c; //自动拆箱:调用了:c.intValue() } } }
3.可变字符序列:StringBuilder、StringBuffer
StringBuilder:线程不安全效率高
StringBuffer:线程安全效率低
函数使用:api
4.时间相关类
在计算机世界,我们把1970年1月1日00:00:00定未基准时间,每个度量单位是毫秒
获得当前时刻的毫秒数:System.currentTimeMillis();
(1)Date类
Date()对象表示一个特定的瞬间,精确到毫秒
(2)DateFormat类和SimpleDateFormat类
DateFormat类的作用把时间对象转化为指定格式的字符串。反之,把指定格式的字符串转化为时间对象。
DateFormat是一个抽象类,一般使用它的子类SimpleDateFormat类来实现
/** * 测试时间对象和字符串之间的互相转换 * DateFormat抽象类和SimpleDateFormat实现类的使用 * @author Ma * */ public class TestDateFormat { public static void main(String[] args) throws ParseException { //把时间对象按照“格式字符串指定的格式”转成相应的字符串 DateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); String str = df.format(new Date(4000000)); System.out.println(str); //把字符串按照“格式字符串指定的格式”转成相应的时间对象 DateFormat df2 = new SimpleDateFormat("yyyy年MM月dd日 hh时mm分ss秒"); Date date = df2.parse("1983年5月10日 10时45分59秒"); System.out.println(date); //测试其他的格式字符。比如:利用D,获得本时间对象是所处年份的第几天。 DateFormat df3 = new SimpleDateFormat("D"); String str3 = df3.format(new Date()); System.out.println(str3); } }
(3)Calendar日历类
Calendar类是一个抽象类,为我们提供了关于日期计算的相关功能。比如:年、月、日、时、分、秒的展示和计算。
GregorianCalendar是Calendar的一个具体子类,提供了世界上大多数国家/地区使用的标准日历系统。
/** * 测试日期类的使用 * @author Ma * */ public class TestCanlendar { public static void main(String[] args) { //获得日期的相关元素 Calendar calendar = new GregorianCalendar(2999,10,9,22,10,50); int year = calendar.get(Calendar.YEAR); int month = calendar.get(Calendar.MONTH); int day = calendar.get(Calendar.DATE); //也可以使用:DAY_OF_MONTH。 int weekday = calendar.get(Calendar.DAY_OF_WEEK); //星期几。 1-7. 1:星期日,2星期一,。。。7是星期六。 System.out.println(year) ; System.out.println(month) ; //0-11表示对应的月份。0是1月,1月是2月.....11是12月。 System.out.println(weekday); System.out.println(day); //设置日期的相关元素 Calendar c2 = new GregorianCalendar(); c2.set(Calendar.YEAR, 8012); System.out.println(c2); //日期的计算 Calendar c3 = new GregorianCalendar(); c3.add(Calendar.YEAR, -100); System.out.println(c3) ; //日期对象和时间对象的转化 Date d4 = c3.getTime(); Calendar c4 = new GregorianCalendar(); c4.setTime(new Date()); printCalendar(c4); } public static void printCalendar(Calendar c){ //打印:1918年10月10日 11:23:45 周三 int year = c.get(Calendar.YEAR); int month = c.get(Calendar.MONTH)+1; //0-11 int date = c.get(Calendar.DAY_OF_MONTH); int dayweek = c.get(Calendar.DAY_OF_WEEK)-1; //1-7.1周日,2周1,3周2.... String dayweek2 = dayweek==0?"日":dayweek+""; int hour = c.get(Calendar.HOUR); int minute = c.get(Calendar.MINUTE); int second = c.get(Calendar.SECOND); System.out.println(year+"年"+month+"月"+date+"日 "+hour+"时"+minute+"分"+second+"秒" +" 周"+dayweek2); } }
5.Math类
常用方法:
public class TestMath { public static void main(String[] args) { //取整相关操作 System.out.println(Math.ceil(3.2)); System.out.println(Math.floor(3.2)); System.out.println(Math.round(3.2)); System.out.println(Math.round(3.8)); //绝对值、开方、a的b次幂等操作 System.out.println(Math.abs(-45)); System.out.println(Math.sqrt(64)); System.out.println(Math.pow(5, 2)); System.out.println(Math.pow(2, 5)); //Math类中常用的常量 System.out.println(Math.PI); System.out.println(Math.E); //随机数 System.out.println(Math.random());// [0,1) } }
public class TestRandom { public static void main(String[] args) { Random rand = new Random(); //随机生成[0,1)之间的double类型的数据 System.out.println(rand.nextDouble()); //随机生成int类型允许范围之内的整型数据 System.out.println(rand.nextInt()); //随机生成[0,1)之间的float类型的数据 System.out.println(rand.nextFloat()); //随机生成false或者true System.out.println(rand.nextBoolean()); //随机生成[0,10)之间的int类型的数据 System.out.println(rand.nextInt(10)); //随机生成[20,30)之间的int类型的数据 System.out.println(20 + rand.nextInt(10)); //随机生成[20,30)之间的int类型的数据(此种方法计算较为复杂) System.out.print(20 + (int) (rand.nextDouble() * 10)); } }
6.File类
/** * 测试File类的基本用法 * @author Ma * */ public class TestFile { public static void main(String[] args) throws IOException { // File f = new File("d:/a.txt"); File f = new File("d:\a.txt"); System.out.println(f); f.renameTo(new File("d:/bb.txt")); File f2 = new File("d:/gg.txt"); f2.createNewFile(); //d盘下生成gg.txt文件 f2.delete(); //将该文件或目录从硬盘上删除 System.out.println("File是否存在:"+f2.exists()); System.out.println("File是否是目录:"+f2.isDirectory()); System.out.println("File是否是文件:"+f2.isFile()); System.out.println("File最后修改时间:"+new Date(f2.lastModified())); System.out.println("File的大小:"+f2.length()); System.out.println("File的文件名:"+f2.getName()); System.out.println("File的目录路径:"+f2.getAbsolutePath()); File f3 = new File("d:/电影/华语/大陆"); boolean flag = f3.mkdir(); //目录结构中有一个不存在,则不会创建整个目录树 boolean flag = f3.mkdirs();//目录结构中有一个不存在也没关系;创建整个目录树 System.out.println(flag);//创建失败 } }
7.异常
(1)RuntimeException子类
| 方法名 | 说明 |
| Exception | 异常层次结构的跟类 |
| ArithmeticException | 算术条件异常。比如:整数除零等。 |
| ArrayIndexOutOfBoundsException | 数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出 |
| SecurityException | 安全性异常 |
| NullPointerException | 尝试访问 null 对象成员 |
| ClassNotFoundException | 不能加载所需的类 |
| InputMismatchException | 欲得到数据类型与实际输入类型不匹配 |
| IllegalArgumentException | 方法接收到非法参数 |
| ClassCastException | 对象强制类型转换出错 |
| NumberFormatException | 数字格式转换异常,如把"ab"转换成数字 |
(2)IOException
| 方法名 | 说明 |
| IOException | 操作输入流和输出流时可能出现的异常 |
| EOFException | 文件已结束异常 |
| FileNotFoundException | 文件未找到异常 |
(3)其他
| 方法名 | 说明 |
| ClassCastException | 类型转换异常类 |
| ArrayStoreException | 数组中包含不兼容的值抛出的异常 |
| SQLException | 操作数据库异常类 |
| NoSuchFieldException | 字段未找到异常 |
| NoSuchMethodException | 方法未找到抛出的异常 |
| NumberFormatException | 字符串转换为数字抛出的异常 |
| StringIndexOutOfBoundsException | 字符串索引超出范围抛出的异常 |
| IllegalAccessException | 不允许访问某类异常 |
| InstantiationException | 当应用程序试图使用Class类中的newInstance()方法创建
一个类的实例,而指定的类对象无法被实例化时,抛出该异常 |
8.泛型
泛型的本质就是“数据类型的参数化”。我们可以把“泛型”理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。
我们可以在类的声明出增加泛型列表,如:<T,E,V>
/** * 测试泛型 * @author Ma */ public class TestGeneric { public static void main(String[] args) { MyCollection<String> mc= new MyCollection<String>(); mc.set("Ma", 0); String b = mc.get(0); } } class MyCollection<E> { //E:表示泛型 Object[] objs = new Object[5]; public void set(E e, int index){ objs[index] = e; } public E get(int index){ return (E) objs[index]; } }
9.容器(集合)
(1)Collection接口
Collection存储一组不唯一、无序的对象,它的两个子接口是List、Set
Collection接口中定义的方法:
| 方法 | 说明 |
| boolean add(Object element) | 增加元素到容器中 |
| boolean remove(Object element) | 从容器中移除元素 |
| boolean contains(Object element) | 容器中是否包含该元素 |
| int size() | 容器中元素的数量 |
| boolean isEmpty() | 容器是否为空 |
| void clear() | 清空容器中所有元素 |
| Iterator iterator() | 获得迭代器,用于遍历所有元素 |
| boolean containAll(Collection c) | 本容器是否包含c容器中所有的元素 |
| boolean addAll(Collection c) | 将容器c中所有元素增加到本容器 |
| boolean removeAll(Collection c) | 移除本容器和容器c中都包含的元素 |
| boolean retainAll(Collection c) | 取本容器和容器c中都包含的元素,移除非交集元素 |
| Object[] toArray() | 转化成Object数组 |
(2)List接口
- List是有序、可重复的容器
有序:List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
可重复:List允许加入重复的元素。
- List接口常用地实现类有3个:ArrayList、LinkedList和Vector
- List相对CollectIon增加了关于位置操作的方法
public static void test(){ List<String> list = new ArrayList<>(); list.add("A"); list.add("B"); list.add("C"); list.add("D"); System.out.println(list); list.add(2,"ma"); //添加 System.out.println(list); list.remove(2); //删除 System.out.println(list); list.set(2, "ma2"); //修改 System.out.println(list); System.out.println(list.get(2)); list.add("C"); list.add("B"); list.add("A"); System.out.println(list); System.out.println(list.indexOf("B")); System.out.println(list.lastIndexOf("B")); }
(3)ArrayList线性表中的顺序表
- ArrayList底层是用数组实现的存储。特点:查询效率高,增删效率低,线程不安全
- 在内存中分配连续的空间,实现了长度可变的数组
- 优点:遍历元素和随机访问元素的效率比较高
- 缺点:添加和删除需大量移动元素效率低,按照内容查询效率低
(4)LinkedList线性表中双向链表
- LinkedList底层用双向链表实现存储。特点:查询效率低,增删效率高,线程不安全
- 优点:插入、删除元素效率比较高
- 缺点:遍历和随机访问元素的效率低下
(5)Vector
- Vector底层说用数组实现的List,相关方法都加了同步检查,线程安全,效率低下
- Vector实现原理和ArrayList相同,功能相同,都是长度可变的数组结构,很多情况下可以互用
- Vector是早期JDK接口,ArrayLis是替代Vector的新接口
- 长度需要增长时,Vector默认增长一倍,ArrayList增长50%
(6)Map接口
- Map用来存储“键-值对”,Map类中存储的键值对通过键来标识,所以“键对象”不能重复,如果重复新的覆盖旧的。
- Map接口实现类有HashMap、TreeMap、HashTable、Properties等
| 方法 | 说明 |
| Object put(Object key,Object value) | 存放键值对 |
| Object get(Object key) | 通过键对象查找得到值对象 |
| Object remove(Object key) | 删除键对象对应的键值对 |
| boolean containsKey(Object key) | Map容器中是否包含键对象对应的键值对 |
| boolean containsValue(Object value) | Map容器中是否包含值对象对应的键值对 |
| int size() | 包含键值对的数量 |
| boolean isEmpty() | Map是否为空 |
| void putAll(Map t) | 将t的所有键值对存放到本map对象 |
| void clear() | 清空本map对象所有键值对 |
(7)HashMap
- HashMap:线程不安全,效率高,允许key或value为null
- HashMap(Key无序 唯一,Value无序 不唯一)底层实现采用了哈希表,哈希表的基本结构是“数组+链表”
- 当添加一个元素(key-value)时,首先计算key的hash值(hashcode&(数组长度-1)),以此确定插入数组中的位置,但可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值得元素得后面,他们在数组同一位置,就形成了链表,同一个链表上的Hash值是相同的,所以说数组存放的是链表。JDK8中,当链表长度大于8时,链表就转换为红黑树这样又大大提高了查找的效率。
- 扩容问题:HashMap的位桶数组,初始大小位16.实际使用时,大小是可变的。如果位桶数组中的元素达到(0.75*数组长度),就重新调整数组大小变为原来2倍大小。
(8)TreeMap
- TreeMap是红黑二叉树的典型实现,有序但速度低于HashMap
/** * 测试TreeMap的使用 * @author Ma * */ public class TestTreeMap { public static void main(String[] args) { Map<Integer,String> treemap1 = new TreeMap<>(); treemap1.put(20, "aa"); treemap1.put(3, "bb"); treemap1.put(6, "cc"); //按照key递增的方式排序 for(Integer key:treemap1.keySet()){ System.out.println(key+"---"+treemap1.get(key)); } Map<Emp,String> treemap2 = new TreeMap<>(); treemap2.put(new Emp(100,"张三",50000), "张三是一个好小伙"); treemap2.put(new Emp(200,"李四",5000), "李四工作不积极"); treemap2.put(new Emp(150,"王五",6000), "王五工作还不错"); treemap2.put(new Emp(50,"赵六",6000), "赵六是个开心果"); //按照key递增的方式排序 for(Emp key:treemap2.keySet()){ System.out.println(key+"---"+treemap2.get(key)); } } } class Emp implements Comparable<Emp> { int id; String name; double salary; public Emp(int id, String name, double salary) { super(); this.id = id; this.name = name; this.salary = salary; } @Override public String toString() { return "id:"+id+",name:"+name+",salary:"+salary; } @Override public int compareTo(Emp o) { //负数:小于,0:等于,正数:大于 if(this.salary>o.salary){ return 1; }else if(this.salary<o.salary){ return -1; }else{ if(this.id>o.id){ return 1; }else if(this.id<o.id){ return -1; }else{ return 0; } } } }
(9)HashTable
- HashTable:线程安全,效率低。不允许key或value为null
(10)Set接口
- Set接口继承自Collection,Set接口中没有新增方法,方法和Collection保持一致
- Set容器特点:无序、不可重复。无序值Set中的元素没有索引,我们只能遍历查找;不可重复指不允许加入重复的元素(Set中只能放入一个null元素,不能多个)
- Set常用的实现类有:HashSet、TreeSet
(11)TreeSet
- TreeSet底层实际是使用TreeMap实现,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。TreeSet内部需要对存储的元素进行排序,因此我们对应的类需要实现Commparable接口
2019.05.11
1.使用Iterator迭代器遍历容器元素(List/Set/Map)
Iterator方法
boolean hasNext():判断是否存在另一个可访问的元素
Object next():返回要访问的下一个元素
void remove():删除上次访问返回的对象
/** * 测试迭代器遍历List、Set、Map * @author Ma * */ public class TestIterator { public static void main(String[] args) { // testIteratorList(); // testIteratorSet(); // testIteratorMap(); testRemove(); } public static void testIteratorList(){ List<String> list = new ArrayList<>(); list.add("aa"); list.add("bb"); list.add("cc"); //使用iterator遍历List for(Iterator<String> iter=list.iterator();iter.hasNext();){ String temp = iter.next(); System.out.println(temp); } } public static void testIteratorSet(){ Set<String> set = new HashSet<>(); set.add("aa"); set.add("bb"); set.add("cc"); //使用iterator遍历Set for(Iterator<String> iter=set.iterator();iter.hasNext();){ String temp = iter.next(); System.out.println(temp); } } public static void testIteratorMap(){ Map<Integer,String> map1 = new HashMap<>(); map1.put(100, "aa"); map1.put(200, "bb"); map1.put(300, "cc"); //第一种遍历Map的方式 Set<Entry<Integer,String>> ss = map1.entrySet(); for(Iterator<Entry<Integer,String>> iter=ss.iterator();iter.hasNext();){ Entry<Integer,String> temp = iter.next(); System.out.println(temp.getKey()+"--"+temp.getValue()); } System.out.println("++++++++++++++++++++++++"); //第二种遍历Map的方式 Set<Integer> keySet = map1.keySet(); for(Iterator<Integer> iter=keySet.iterator();iter.hasNext(); ){ Integer key = iter.next(); System.out.println(key+"----"+map1.get(key)); } } //测试边遍历,边删除 public static void testRemove(){ List<String> list = new ArrayList<>(); for(int i=0;i<20;i++){ list.add("gao"+i); } for(int i=0;i<list.size();i++){ String temp = list.get(i); if(temp.endsWith("2")){ list.remove(i); } System.out.println(list.size()); System.out.println(list.get(i)); } } }
2.Collections工具类
类java.util.Collections提供了对Set、List、Map进行排序、填充、查找元素的辅助方法
| 方法 | 说明 |
| void sort(List) | 对List容器内元素排序,排序规则按照升序排序 |
| void shuffle(List) | 对List容器内的元素进行随机排序 |
| void reverse(List) | 对List容器内的元素进行逆序排序 |
| void fill(List,Object) | 用一个特定的对象重写整个List容器 |
| int binarySearch(List,Object) | 对于顺序的List容器,采用折半查找的方法查找特定对象 |
3.使用容器存储表格数据(ORM思想:对象关系映射)
(1)每一行数据使用一个Map,整个表格使用一个List
/** * 测试表格数据的存储 * ORM思想的简单实验:map表示一行数据,多行数据是多个map;将多个map放到list中 * @author Ma * */ public class TestStoreData { public static void main(String[] args) { Map<String,Object> row1 = new HashMap<>(); row1.put("id", 1001); row1.put("姓名", "张三"); row1.put("薪水", 20000); row1.put("入职日期", "2018.5.5"); Map<String,Object> row2 = new HashMap<>(); row2.put("id", 1002); row2.put("姓名", "李四"); row2.put("薪水", 30000); row2.put("入职日期", "2005.4.4"); Map<String,Object> row3 = new HashMap<>(); row3.put("id", 1003); row3.put("姓名", "王五"); row3.put("薪水", 3000); row3.put("入职日期", "2020.5.4"); List<Map<String,Object>> table1 = new ArrayList<>(); table1.add(row1); table1.add(row2); table1.add(row3); for(Map<String,Object> row:table1){ Set<String> keyset = row.keySet(); for (String key : keyset) { System.out.print(key+":"+row.get(key)+" "); } System.out.println(); } } }
(2)每一行数据使用javabean对象存储,整个表格使用一个map或list
/** * 测试表格数据的存储 * 体会ORM思想 * 每一行数据使用javabean对象存储,多行使用放到map或list中。 * @author Ma * */ public class TestStoreData2 { public static void main(String[] args) { User user1 = new User(1001, "张三", 20000, "2018.5.5"); User user2 = new User(1002, "李四", 30000, "2005.4.4"); User user3 = new User(1003, "王五", 3000, "2020.5.4"); List<User> list = new ArrayList<>(); list.add(user1); list.add(user2); list.add(user3); for(User u:list){ System.out.println(u); } Map<Integer,User> map = new HashMap<>(); map.put(1001, user1); map.put(1002, user2); map.put(1003, user3); Set<Integer> keyset = map.keySet(); for (Integer key : keyset) { System.out.println(key+"===="+map.get(key)); } } } class User { private int id; private String name; private double salary; private String hiredate; //一个完整的javabean。要有set和get方法,以及无参构造器! public User() { } public User(int id, String name, double salary, String hiredate) { super(); this.id = id; this.name = name; this.salary = salary; this.hiredate = hiredate; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getSalary() { return salary; } public void setSalary(double salary) { this.salary = salary; } public String getHiredate() { return hiredate; } public void setHiredate(String hiredate) { this.hiredate = hiredate; } @Override public String toString() { return "id:"+id+",name:"+name+",salary:"+salary+",hiredate:"+hiredate; } }
2019.5.12
1.相对路径与绝对路径
绝对路径:存在盘符
相对路径:不存在盘符,相对于当前目录user.dir
2.File类
Java文件类以抽象的方式代表文件名和目录路径名。该类主要用于文件和目录的创建、文件的查找和文件的删除等。
File对象代表磁盘中实际存在的文件和目录。通过以下构造方法创建一个File对象。
构造方法:
- 通过给定的父抽象路径名和子路径名字符串创建一个新的File实例。
File(File parent, String child);
- 通过将给定路径名字符串转换成抽象路径名来创建一个新 File 实例。
File(String pathname)
- 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
File(String parent, String child)
- 通过将给定的 file: URI 转换成一个抽象路径名来创建一个新的 File 实例。
File(URI uri)
创建File对象成功后,可以使用以下列表中的方法操作文件:
| 方法 | 说明 |
| public String getName() | 返回文件或目录的名称 |
| public String getParent() | 返回父路径名的字符串,如果没有指定父目录,则返回 null |
| public File getParentFile() | 返回父路径名的File对象,如果此路径名没有指定父目录,则返回 null |
| public String getPath() | 将此抽象路径名转换为一个路径名字符串 |
| public boolean isAbsolute() | 是否为绝对路径 |
| public String getAbsolutePath() | 返回抽象路径名的绝对路径名字符串 |
| public boolean canRead() | 是否可以读取此文件 |
| public boolean canWrite() | 是否可以修改此文件 |
| public boolean exists() | 文件或目录是否存在 |
| public boolean isDirectory() | 文件是否是一个目录 |
| public boolean isFile() | 是否是一个标准文件 |
| public long lastModified() | 返回文件最后一次被修改的时间 |
| public long length() | 返回文件的长度 |
| public boolean createNewFile() throws IOException | 当且仅当不存在指定的名称的文件时,原子地创建一个新的空文件 |
| public boolean delete() | 删除文件或目录 |
| public void deleteOnExit() | 在虚拟机终止时,请求删除文件或目录 |
| public String[] list() | 返回下级目录文件名称的字符串数组 |
| public String[] list(FilenameFilter filter) | 返回由包含在目录中的文件和目录的名称所组成的字符串数组,这一目录是通过满足指定过滤器的抽象路径名来表示的 |
| public File[] listFiles() | 返回下级目录文件名称的File对象数组 |
| public File[] listFiles(FileFilter filter) | 返回表示此抽象路径名所表示目录中的文件和目录的抽象路径名数组,这些路径名满足特定过滤器 |
| public boolean mkdir() | 创建指定的目录,确保上级目录存在,不存在创建失败 |
| public boolean mkdirs() | 创建指定的目录,上级目录不存在一同创建 |
| public boolean renameTo(File dest) | 重新命名此文件 |
| public boolean setLastModified(long time) | 设置指定文件或目录的最后一次修改时间 |
| public boolean setReadOnly() | 标记指定的文件或目录,以便只可对其进行读操作 |
| public static File createTempFile(String prefix, String suffix, File directory) throws IOException | 在指定目录中创建一个新的空文件,使用给定的前缀和后缀字符串生成其名称 |
| public static File createTempFile(String prefix, String suffix) throws IOException | 在默认临时文件目录中创建一个空文件,使用给定前缀和后缀生成其名称 |
| public int compareTo(File pathname) | 按字母顺序比较两个抽象路径名 |
| public int compareTo(Object o) | 按字母顺序比较抽象路径名与给定对象 |
| public boolean equals(Object obj) | 测试此抽象路径名与给定对象是否相等 |
| public String toString() | 返回路径名字符串 |
3.文件编码
字节->字符:编码(encode)
字符->字节:解码(decode)
/** * 编码: 字符串-->字节 * @author Ma * */ public class ContentEncode { public static void main(String[] args) throws IOException { String msg ="性命生命使命a"; //编码: 字节数组 byte[] datas = msg.getBytes(); //默认使用工程的字符集 System.out.println(datas.length); //编码: 其他字符集 datas = msg.getBytes("UTF-16LE"); System.out.println(datas.length); datas = msg.getBytes("GBK"); System.out.println(datas.length); } }
/** * 解码: 字节->字符串 * @author Ma * */ public class ContentDecode { public static void main(String[] args) throws UnsupportedEncodingException { String msg ="性命生命使命a"; //编码: 字节数组 byte[] datas = msg.getBytes(); //默认使用工程的字符集 //解码: 字符串 String(byte[] bytes, int offset, int length, String charsetName) msg = new String(datas,0,datas.length,"utf8"); System.out.println(msg); //乱码: //1)、字节数不够 msg = new String(datas,0,datas.length-2,"utf8"); System.out.println(msg); msg = new String(datas,0,datas.length-1,"utf8"); System.out.println(msg); //2)、字符集不统一 msg = new String(datas,0,datas.length-1,"gbk"); System.out.println(msg); } }
4.InputStream:字节输入流的父类,数据单位为字节
常用方法:
| 方法 | 说明 |
| void close() | 关闭此输入流并释放与流相关联的任何系统资源 |
| int read(byte[] b) | 从输入流中读取一些字节数,并将他们存储到缓冲器阵列b |
| int read(byte[] b,int off, int len) | 从输入流读取最多len个字节的数据到字节数组 |
| abstract int read() | 从输入流读取数据的下一个字节 |
/** * 四个步骤: 分段读取 文件字节输入流 * 1、创建源 * 2、选择流 * 3、操作 * 4、释放资源 * * @author Ma * */ public class IOTest03 { public static void main(String[] args) { //1、创建源 File src = new File("abc.txt"); //2、选择流 InputStream is =null; try { is =new FileInputStream(src); //3、操作 (分段读取) byte[] flush = new byte[1024*10]; //缓冲容器 int len = -1; //接收长度 while((len=is.read(flush))!=-1) { //字节数组-->字符串 (解码) String str = new String(flush,0,len); System.out.println(str); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { //4、释放资源 try { if(null!=is) { is.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
5.OutputStream:字节输出流的父类,数据单位为字节
常用方法:
| 方法 | 说明 |
| void close() | 关闭此输出流并释放与此流相关联的任何系统资源 |
| void flush() | 刷新此输出流并强制任何缓冲的输出字节被写出 |
| void write(byte[] b) | 将b.length字节从指定的字节数组写入此输出流 |
| void write(byte[] b,int off,int len) | 从指定的字节数组写入len字节,从偏移量off开始输出此输出流 |
| abstract void write(int b) | 将指定的字节写入此输出流 |
/** * 文件字节输出流 *1、创建源 *2、选择流 *3、操作(写出内容) *4、释放资源 * @author Ma * */ public class IOTest04 { public static void main(String[] args) { //1、创建源 File dest = new File("dest.txt"); //文件不存在创建文件 //2、选择流 OutputStream os =null; try { os = new FileOutputStream(dest,true); //true为追加操作 //3、操作(写出) String msg ="IO is so easy "; byte[] datas =msg.getBytes(); // 字符串-->字节数组(编码) os.write(datas,0,datas.length); os.flush(); }catch(FileNotFoundException e) { e.printStackTrace(); }catch (IOException e) { e.printStackTrace(); }finally{ //4、释放资源 try { if (null != os) { os.close(); } } catch (Exception e) { } } } }
6.Reader:字符输入流的父类,数据单位为字符
常用方法:
| 方法 | 说明 |
| void close() | 关闭此输入流并释放与流相关联的任何系统资源 |
| int read() | 读一个字符 |
| int read(char[] cbuf) | 将字符读入数组 |
| abstract int read(cbuf[] b,int off, int len) | 从输入流读取最多len个字符的数据到字符数组 |
/** * 四个步骤: 分段读取 文件字符输入流 * 1、创建源 * 2、选择流 * 3、操作 * 4、释放资源 * * @author Ma * */ public class IOTest05 { public static void main(String[] args) { //1、创建源 File src = new File("abc.txt"); //2、选择流 Reader reader =null; try { reader =new FileReader(src); //3、操作 (分段读取) char[] flush = new char[1024]; //缓冲容器 int len = -1; //接收长度 while((len=reader.read(flush))!=-1) { //字符数组-->字符串 String str = new String(flush,0,len); System.out.println(str); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { //4、释放资源 try { if(null!=reader) { reader.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
7.Writer:字节输出流的父类,数据单位为字符
常用方法:
| 方法 | 说明 |
| abstract void close() | 关闭流,先刷新 |
| abstract void flush() | 刷新流 |
| void write(int c) | 写入一个字符 |
| void write(String str) | 写入一个字符串 |
| void write(String str,int off,int len) | 写入字符串的一部分 |
| abstract void write(byte[] cbuf,int off,int len) | 写入字符数组的一部分 |
/** * 文件字符输出流 *1、创建源 *2、选择流 *3、操作(写出内容) *4、释放资源 * @author Ma * */ public class IOTest06 { public static void main(String[] args) { //1、创建源 File dest = new File("dest.txt"); //2、选择流 Writer writer =null; try { writer = new FileWriter(dest); //3、操作(写出) //写法一 // String msg ="IO is so easy 欢迎你"; // char[] datas =msg.toCharArray(); // 字符串-->字符数组 // writer.write(datas,0,datas.length); //写法二 /*String msg ="IO is so easy 欢迎你"; writer.write(msg); writer.write("add"); writer.flush();*/ //写法三 writer.append("IO is so easy ").append("欢迎你"); writer.flush(); }catch(FileNotFoundException e) { e.printStackTrace(); }catch (IOException e) { e.printStackTrace(); }finally{ //4、释放资源 try { if (null != writer) { writer.close(); } } catch (Exception e) { } } } }
2019.5.13
1.字节数组流(ByteArrayInputStream&ByteArrayOutputStream)
我们常见的节点流(FileInputStream/FileOutputStream FileReader/FileWrite)和常见处理流(BufferedInputStream/BufferedOutputStream BufferedReader/BufferedWriter),都是针对文件的操作,然后带上缓冲的节点流进行处理,但有时候为了提升效率,我们发现频繁的读写文件并不是太好,于是出现了字节数组流,即存放在内存中,也称为内存流;其中字节数组流也是一种节点流
(1)ByteArrayInputStream
字节数组输入流在内存创建一个字节数组缓冲区,从输入流读取的数据保存在该字节数组缓冲区中
(2)ByteArrayOutputStream
字节数组输出流在内存中创建一个字节数组缓冲区,所有发送到输出流的数据保存在该字节数组缓冲区中
/** *1、 图片读取到字节数组 *2、 字节数组写出到文件 * @author Ma * */ public class IOTest { public static void main(String[] args) { //图片转成字节数组 byte[] datas = fileToByteArray("p.png"); System.out.println(datas.length); byteArrayToFile(datas,"p-byte.png"); } /** * 1、图片读取到字节数组 * 1)、图片到程序 FileInputStream * 2)、程序到字节数组 ByteArrayOutputStream */ public static byte[] fileToByteArray(String filePath) { //1、创建源与目的地 File src = new File(filePath);//2、选择流 InputStream is =null; ByteArrayOutputStream baos =null; try { is =new FileInputStream(src); baos = new ByteArrayOutputStream(); //3、操作 (分段读取) byte[] flush = new byte[1024*10]; //缓冲容器 int len = -1; //接收长度 while((len=is.read(flush))!=-1) { baos.write(flush,0,len); //写出到字节数组中 } baos.flush(); return baos.toByteArray(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { //4、释放资源 try { if(null!=is) { is.close(); } } catch (IOException e) { e.printStackTrace(); } } return null; } /** * 2、字节数组写出到图片 * 1)、字节数组到程序 ByteArrayInputStream * 2)、程序到文件 FileOutputStream */ public static void byteArrayToFile(byte[] src,String filePath) { //1、创建源 File dest = new File(filePath); //2、选择流 InputStream is =null; OutputStream os =null; try { is =new ByteArrayInputStream(src); os = new FileOutputStream(dest); //3、操作 (分段读取) byte[] flush = new byte[5]; //缓冲容器 int len = -1; //接收长度 while((len=is.read(flush))!=-1) { os.write(flush,0,len); //写出到文件 } os.flush(); } catch (IOException e) { e.printStackTrace(); }finally { //4、释放资源 try { if (null != os) { os.close(); } } catch (Exception e) { } } } }
2.缓冲流
缓冲输入流相对于普通输入流的优势是,它提供了一个缓冲数组,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源(譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容部分或全部返回给用户.从缓冲区里读取数据远比直接从物理数据源(譬如文件)读取速度快。
(1)BufferedInputStream&BufferedOutputStream
/** * 文件拷贝:文件字节输入、输出流 * * @author Ma * */ public class Copy { public static void main(String[] args) { long t1 = System.currentTimeMillis(); copy("IO开篇.mp4","IO-copy.mp4"); long t2 = System.currentTimeMillis(); System.out.println(t2-t1); } public static void copy(String srcPath,String destPath) { //1、创建源 File src = new File(srcPath); //源头 File dest = new File(destPath);//目的地 //2、选择流 try( InputStream is=new BufferedInputStream(new FileInputStream(src)); OutputStream os =new BufferedOutputStream( new FileOutputStream(dest)); ) { //3、操作 (分段读取) byte[] flush = new byte[1024]; //缓冲容器 int len = -1; //接收长度 while((len=is.read(flush))!=-1) { os.write(flush,0,len); //分段写出 } os.flush(); }catch(FileNotFoundException e) { e.printStackTrace(); }catch (IOException e) { e.printStackTrace(); } } }
(2)BufferedReader&BufferedWriter
/** * 纯文本拷贝:文件字节输入、输出流 * * @author Ma * */ public class CopyTxt { public static void main(String[] args) { copy("abc.txt","abc-copy.txt"); } public static void copy(String srcPath,String destPath) { //1、创建源 File src = new File(srcPath); //源头 File dest = new File(destPath);//目的地 //2、选择流 try( BufferedReader br=new BufferedReader(new FileReader(src)); BufferedWriter bw =new BufferedWriter( new FileWriter(dest)); ) { //3、操作 (逐行读取) String line =null; while((line=br.readLine())!=null) { bw.write(line); //逐行写出 bw.newLine(); } bw.flush(); }catch(FileNotFoundException e) { e.printStackTrace(); }catch (IOException e) { e.printStackTrace(); } } }
3.转换流:InputStreamReader&OutputStreamWriter
- 以字符流的形式操作字节流(纯文本)
- 为字节流指定字符集
/** * 转换流: InputStreamReader OutputStreamWriter * 1、以字符流的形式操作字节流(纯文本的) * 2、指定字符集 * @author Ma * */ public class ConvertTest { public static void main(String[] args) { //操作System.in 和System.out try(BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter writer =new BufferedWriter(new OutputStreamWriter(System.out));){ //循环获取键盘的输入(exit退出),输出此内容 String msg =""; while(!msg.equals("exit")) { msg = reader.readLine(); //循环读取 writer.write(msg); //循环写出 writer.newLine(); writer.flush(); //强制刷新 } }catch(IOException e) { System.out.println("操作异常"); } } }
/** * 转换流: InputStreamReader OutputStreamWriter * 1、以字符流的形式操作字节流(纯文本的) * 2、指定字符集 * @author Ma * */ public class ConvertTest { public static void main(String[] args) { try(BufferedReader reader = new BufferedReader( new InputStreamReader( new URL("http://www.baidu.com").openStream(),"UTF-8")); BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream("baidu.html"),"UTF-8"));){ //3、操作 (读取) String msg ; while((msg=reader.readLine())!=null) { writer.write(msg); writer.newLine(); } writer.flush(); }catch(IOException e) { System.out.println("操作异常"); } } }
4.数据流:DataInputStream&DataOutputStream
- 保留了数据类型,方便处理基本 Java 数据类型
- 写出后读取
- 读取的顺序与写出保持一致
5.对象流:ObjectInputStream(反序列化)&ObjectOutputStream(序列化)
- 只有支持java.io.Serializable接口的对象才能序列化
- 写出后读取
- 读取的顺序与写出保持一致
/** * 对象流: 1、写出后读取 2、读取的顺序与写出保持一致 3、不是所有的对象都可以序列化Serializable * * ObjectOutputStream ObjectInputStream * * @author Ma * */ public class ObjectTest { public static void main(String[] args) throws IOException, ClassNotFoundException { // 写出 -->序列化 ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("obj.ser"))); // 操作数据类型 +数据 oos.writeUTF("编码辛酸泪"); oos.writeInt(18); oos.writeBoolean(false); oos.writeChar('a'); // 对象 oos.writeObject("谁解其中味"); oos.writeObject(new Date()); Employee emp = new Employee("马云", 400); oos.writeObject(emp); oos.flush(); oos.close(); // 读取 -->反序列化 ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream("obj.ser"))); // 顺序与写出一致 String msg = ois.readUTF(); int age = ois.readInt(); boolean flag = ois.readBoolean(); char ch = ois.readChar(); System.out.println(flag); // 对象的数据还原 Object str = ois.readObject(); Object date = ois.readObject(); Object employee = ois.readObject(); if (str instanceof String) { String strObj = (String) str; System.out.println(strObj); } if (date instanceof Date) { Date dateObj = (Date) date; System.out.println(dateObj); } if (employee instanceof Employee) { Employee empObj = (Employee) employee; System.out.println(empObj.getName() + "-->" + empObj.getSalary()); } ois.close(); } }
6.打印流
7.随机读取和写入流RandomAccessFile
8.CommonsIO
public class CIOTest01 { public static void main(String[] args) { //文件大小 long len =FileUtils.sizeOf(new File("src/com/sxt/commons/CIOTest01.java")); System.out.println(len); //目录大小 len = FileUtils.sizeOf(new File("D:/java300/IO_study04")); System.out.println(len); } }
/** * 列出子孙级 */ public class CIOTest02 { public static void main(String[] args) { Collection<File> files =FileUtils.listFiles(new File("D:\java300\IO_study04"), EmptyFileFilter.NOT_EMPTY, null); for (File file : files) { System.out.println(file.getAbsolutePath()); } System.out.println("---------------------"); files =FileUtils.listFiles(new File("D:\java300\IO_study04"), EmptyFileFilter.NOT_EMPTY, DirectoryFileFilter.INSTANCE); for (File file : files) { System.out.println(file.getAbsolutePath()); } System.out.println("---------------------"); files =FileUtils.listFiles(new File("D:\java300\IO_study04"), new SuffixFileFilter("java"), DirectoryFileFilter.INSTANCE); for (File file : files) { System.out.println(file.getAbsolutePath()); } System.out.println("---------------------"); files =FileUtils.listFiles(new File("D:\java300\IO_study04"), FileFilterUtils.or(new SuffixFileFilter("java"), new SuffixFileFilter("class"),EmptyFileFilter.EMPTY), DirectoryFileFilter.INSTANCE); for (File file : files) { System.out.println(file.getAbsolutePath()); } System.out.println("---------------------"); files =FileUtils.listFiles(new File("D:\java300\IO_study04"), FileFilterUtils.and(new SuffixFileFilter("java"), EmptyFileFilter.NOT_EMPTY), DirectoryFileFilter.INSTANCE); for (File file : files) { System.out.println(file.getAbsolutePath()); } } }
/** * 读取内容 * @author Ma * */ public class CIOTest03 { public static void main(String[] args) throws IOException { //读取文件 String msg =FileUtils.readFileToString(new File("emp.txt"),"UTF-8"); System.out.println(msg); byte[] datas = FileUtils.readFileToByteArray(new File("emp.txt")); System.out.println(datas.length); //逐行读取 List<String> msgs= FileUtils.readLines(new File("emp.txt"),"UTF-8"); for (String string : msgs) { System.out.println(string); } LineIterator it =FileUtils.lineIterator(new File("emp.txt"),"UTF-8"); while(it.hasNext()) { System.out.println(it.nextLine()); } } }
/** * 写出内容 * @author Ma * */ public class CIOTest04 { public static void main(String[] args) throws IOException { //写出文件 FileUtils.write(new File("happy.sxt"), "学习是一件伟大的事业 ","UTF-8"); FileUtils.writeStringToFile(new File("happy.sxt"), "学习是一件辛苦的事业 ","UTF-8",true); FileUtils.writeByteArrayToFile(new File("happy.sxt"), "学习是一件幸福的事业 ".getBytes("UTF-8"),true); //写出列表 List<String> datas =new ArrayList<String>(); datas.add("马云"); datas.add("马化腾"); datas.add("弼马温"); FileUtils.writeLines(new File("happy.sxt"), datas,"。。。。。",true); } }
/** * 拷贝 * @author Ma * */ public class CIOTest05 { public static void main(String[] args) throws IOException { //复制文件 //FileUtils.copyFile(new File("p.png"),new File("p-copy.png")); //复制文件到目录 //FileUtils.copyFileToDirectory(new File("p.png"),new File("lib")); //复制目录到目录 //FileUtils.copyDirectoryToDirectory(new File("lib"),new File("lib2")); //复制目录 //FileUtils.copyDirectory(new File("lib"),new File("lib2")); //拷贝URL内容 //String url = "https://pic2.zhimg.com/v2-7d01cab20858648cbf62333a7988e6d0_qhd.jpg"; //FileUtils.copyURLToFile(new URL(url), new File("marvel.jpg")); String datas =IOUtils.toString(new URL("http://www.163.com"), "gbk"); System.out.println(datas); } }
2019.5.16
1.IP地址
用来标识网络中的一个通用实体的地址2.
2.InetAddress
/** * InetAddress: * 1.getLocatHost:本机 * 2.getByName:根据域名DNS | IP地址--》IP * * 两个成员方法 * 1.getHostAddress:返回地址 * 2.getHostName:返回计算机名 * @author MA * */ public class IPTest { public static void main(String[] args) throws UnknownHostException { //使用getLocaHost方法创建InetAddress对象 本机 InetAddress addr = InetAddress.getLocalHost(); System.out.println(addr.getHostAddress());//返回IP地址 System.out.println(addr.getHostName());//输出计算机名 //根据域名得到InetAddress对象 addr = InetAddress.getByName("www.163.com"); System.out.println(addr.getHostAddress());//返回163服务器IP System.out.println(addr.getHostName());//输出:www.163.com //根据IP得到InetAddress对象 addr = InetAddress.getByName("123.56.138.176"); System.out.println(addr.getHostAddress());//返回shsxt的ip System.out.println(addr.getHostName());//输出ip而不是域名。如果这个IP地址不存在或DNS服务器不允许进行IP地址和域名的映射,getHostName方法就直接返回这个IP地址 } }
3.端口
IP地址用来标识一台计算机,电脑里的软件由端口区分。端口0~65535,0~1023为公认端口
8080-》tomact
1521-》oracle
3306-》mysql
查看所有端口:netstat -ano
查看指定端口:netstat -ano|findstr "808"
查看指定进程:tasklist|findstr "808"
查看具体程序:使用任务管理器查看PID
4.InetSocketAddress
包含端口,用于socket通信
/** * InetSocketAddress * 1.构造器 * new InetSocketAddress(地址|域名,端口); * 2.方法 * getAddress() * getport() * getHostName() * @author MA * */ public class PortTest { public static void main(String[] args) { //包含端口 InetSocketAddress socketAddress = new InetSocketAddress("127.0.0.1",8080); InetSocketAddress socketAddress2 = new InetSocketAddress("localhost",9000); System.out.println(socketAddress.getHostName()); System.out.println(socketAddress2.getAddress()); System.out.println(socketAddress2.getPort()); } }
5.URI(统一资源标志符)
(1)URN:统一资源名称(磁力链接)
(2)URL:统一资源定位符,互联网三大基石之一(html,http)区分资源
http://www.google.com:80/index.html
协议:http
主机域名:www.google.com
端口号:80
请求资源:index.html
public class URLTest01 { public static void main(String[] args) throws MalformedURLException { URL url = new URL("http://www.baidu.com:80/index.html?uname=shsxt&age=18#a"); System.out.println("协议:" + url.getProtocol()); System.out.println("域名|ip:" + url.getHost()); System.out.println("端口:" + url.getPort()); System.out.println("请求资源1:" + url.getFile()); System.out.println("请求资源2:" + url.getPath()); //参数 System.out.println("参数:" + url.getQuery()); //锚点 System.out.println("锚点:" + url.getRef()); } }
6.网络爬虫的原理
/** * 网络爬虫原理 * @author MA * */ public class SpiderTest { public static void main(String[] args) throws IOException { //获取URL URL url = new URL("https://www.jd.com"); //下载资源 InputStream is = url.openStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8")); String msg = null; while(null!=(msg=br.readLine())){ System.out.println(msg); } br.close(); //分析 //处理。。。 } }
/** * 网络爬虫原理 + 模拟浏览器 * @author MA * */ public class SpiderTest2 { public static void main(String[] args) throws IOException { //获取URL URL url = new URL("https://www.dianping.com"); //下载资源 HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("GET"); conn.setRequestProperty("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134"); BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8")); String msg = null; while(null!=(msg=br.readLine())){ System.out.println(msg); } br.close(); //分析 //处理。。。 } }
7.Socket 套接字
(1)TCP传输协议
一种面向连接的、可靠的、基于字节流的运输层通讯协议。
/** * 创建客户端 * 1.建立连接:使用Socket创建客户端+服务的地址和端口 * 2.操作:输入输出操作 * 3.释放资源 * @author MA * */ public class Client { public static void main(String[] args) throws UnknownHostException, IOException { //1.建立连接:使用Socket创建客户端+服务的地址和端口 Socket client = new Socket("localhost",8888); //2.操作:输入输出操作 DataOutputStream dos = new DataOutputStream(client.getOutputStream()); String data="hello"; dos.writeUTF(data); dos.flush(); //3.释放资源 dos.close(); client.close(); } } /** * 创建服务器 * 1.指定端口 使用ServerSocket创建服务器 * 2.阻塞式等待连接accept * 3.操作:输入输出流操作 * 4.释放资源 * @author MA * */ public class Server { public static void main(String[] args) throws IOException { //1.指定端口 使用ServerSocket创建服务器 ServerSocket server = new ServerSocket(9999); //2.阻塞式等待连接accept Socket client = server.accept(); //3.操作:输入输出流操作 DataInputStream dis = new DataInputStream(client.getInputStream()); String data = dis.readUTF(dis); //4.释放资源 dis.close(); client.close(); } }
(2)UDP协议
一种无连接的传输协议,提供面向事务的简单不可靠信息传送服务。
/** * 发送端 * 1.使用DatagrammSocket指定端口创建发送端 * 2.准备数据 一定转成字节数组 * 3.封装成DatagramPacket包裹,需要指定目的地 * 4.发送包裹send(DatagramPacket p) * 5.释放资源 * @author MA */ public class UdpClient { public static void main(String[] args) throws IOException { //1.使用DatagrammSocket指定端口创建发送端 DatagramSocket client = new DatagramSocket(8888); //2.准备数据 一定转成字节数组 String data = "Hello world!"; byte[] datas = data.getBytes(); //3.封装成DatagramPacket包裹,需要指定目的地 DatagramPacket packet = new DatagramPacket(datas,0,datas.length,new InetSocketAddress("localhost", 9999)); //4.发送包裹send(DatagramPacket p) client.send(packet); //5.释放资源 client.close(); } } /** * 接收端 * 1.使用DatagrammSocket指定端口创建接收端 * 2.准备容器 封装成DatagramPacket包裹 * 3.阻塞式接收包裹receive(DatagramPacket p) * 4.分析数据 * byte[] getData() * int getLength() * 5.释放资源 * @author MA */ public class UdpServer { public static void main(String[] args) throws IOException { //1.使用DatagrammSocket指定端口创建接收端 DatagramSocket server = new DatagramSocket(9999); //2.准备容器 封装成DatagramPacket包裹 byte[] container = new byte[1024*60]; DatagramPacket packet = new DatagramPacket(container,0,container.length); //3.阻塞式接收包裹receive(DatagramPacket p) server.receive(packet); //4.分析数据 byte[] datas = packet.getData(); int len = packet.getLength(); System.out.println(new String(datas,0,len)); //5.释放资源 server.close(); } }
2019.5.19
1.反射
反射Reflection:把java类中的各种结构(方法、属性、构造器、类名)映射成一个个的java对象。
/** * 反射:把java类中的各种结构(方法、属性、构造器、类名)映射成一个个的java对象。 * 1.获取Class对象 * 三种方式:Class.forName("完整路径") * 2.动态创建对象 * clz.getConstructor().newInstance() * @author MA */ public class ReflectTest { public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException, NoSuchMethodException, SecurityException { //三种方式 //1.对象,getClass() Class clz = new Iphone().getClass(); //2.类.class(); clz = Iphone.class; //3.Class.forName("包名.类名") clz = Class.forName("com.mxj.server.basic.Iphone"); //创建对象 /*Iphone iphone1 = (Iphone)clz.newInstance(); System.out.println(iphone1);*/ //JDK9推荐构造器的方式 Iphone iphone2 = (Iphone)clz.getConstructor().newInstance(); } } class Iphone{ public Iphone(){ } }
2.XML解析
XML:Extensible Markup Language,可扩展标记语言,作为数据的一种存储格式或用于存储软件的参数,程序解析配置文件,就可以达到不修改代码就能更改程序的目的。
(1)DOM解析
(2)SAX解析
XML:
<?xml version="1.0" encoding="UTF-8"?> <persons> <person> <name>张三</name> <age>20</age> </person> <person> <name>李四</name> <age>25</age> </person> </persons>
Person类:
package com.mxj.server.basic; public class Person { private String name; private int age; public Person() { super(); // TODO Auto-generated constructor stub } public Person(String name, int age) { super(); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
SAX解析:
/** * SAX解析流程 * 1.获取解析工厂 * 2.从解析工厂中获取解析器 * 3.加载文档Document注册处理器 * 4.编写处理器 * @author MA */ public class XmlTest01 { public static void main(String[] args) throws Exception, SAXException { //1.获取解析工厂 SAXParserFactory factory = SAXParserFactory.newInstance(); //2.从解析工厂中获取解析器 SAXParser parse = factory.newSAXParser(); //3.编写处理器 //4.加载文档Document注册处理器 PersonHandler handler = new PersonHandler(); //5.解析 parse.parse(Thread.currentThread().getContextClassLoader().getResourceAsStream("com/mxj/server/basic/person.xml"),handler); //获取数据 List<Person> persons = handler.getPersons(); for(Person p:persons){ System.out.println(p.getName()+"-->"+p.getAge()); } } } class PersonHandler extends DefaultHandler{ private List<Person> persons; private Person person; private String tag;//存储操作标签 //解析文档开始 @Override public void startDocument() throws SAXException { persons = new ArrayList<Person>(); } //解析标签(元素)开始 @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { if(qName!=null){ tag = qName;//存储标签名 } if(tag.equals("person")){ person = new Person(); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { String contents = new String(ch,start,length).trim(); if(null!=tag){ if(tag.equals("name")){ person.setName(contents); }else if(tag.equals("age")){ if(contents.length()>0){ person.setAge(Integer.valueOf(contents)); } } } } //解析标签(元素)结束 @Override public void endElement(String uri, String localName, String qName) throws SAXException { if(null!=qName){ if(qName.equals("person")){ persons.add(person); } } tag = null; } //解析文档结束 @Override public void endDocument() throws SAXException { } public List<Person> getPersons() { return persons; } }
3.HTML
Hyper Text Markup Language:超文本标记语言,简单理解为浏览器使用的语言
4.HTTP协议
超文本传输协议(HTTP,Hyper Text Transfer Protocol)是互联网上应用最为广泛的一种网络协议,所有的www文件都必须遵守这个标准。
2019.5.21
1.注解Annotation
Annotation是从JDK5.0开始引入的新技术,可以被其他程序(比如:编辑器)读取,可以附加在package,class,method,field等上面,相当于给他们添加了额外的辅助信息,我们可以通过反射机制编程实现对这些元数据的访问。
(1)@Override
定义在java.lang.Override中,此注释只使用于修饰方法,表示一个方法声明打算重写超类中的另一个方法声明。
(2)@Deprecated
定义在java.lang.Deprecated中,此注释可用于修饰方法、属性、类,表示不鼓励程序员使用这样的元素,通常是因为它很危险或存在更好的选择。
2.内置注解
(1)@SuppressWarning
定义在java.lang.SuppressWarning中,用来抑制编译时的警告信息。
| 参数 | 说明 |
| deprecation | 使用了过时的类或方法的警告 |
| unchecked | 执行了未检查的转换时的警告,如使用集合时未指定泛型 |
| fallthrough | 当在switch语句使用时发生case穿透 |
| path | 在类路径、源文件路径等中有不存在路径的警告 |
| serial | 当在可序列化的类上缺少serialVersionUID定义时的警告 |
| finally | 任何finally子句不能完成时的警告 |
| all | 关于以上所有情况的警告 |
3.自定义注解
使用@interface自定义注解时,自动继承了java.lang.annotation.Anntation接口
格式:public @interface 注解名 {定义体}
4.元注解
元注解的作用就是负责注解其他注解。java定义了4个标准的meta-annotation类型,它们被用来提供对其他annotation类型作说明。
(1)@Target
用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
| 所修饰范围 | 取值ElementType |
| package包 | PACKAGE |
| 类、接口、枚举、Annotation类型 | TYPE |
| 类型成员(方法、构造方法、成员变量、枚举值) |
CONSTRUCTOR:用于描述构造器 FIELD:用于描述域 METHOD:用于描述方法 |
| 方法参数和本地变量 |
LOCAL_VARIABLE:用于描述局部变量 PARAMETER:用于描述参数 |
(2)@Retention
表示需要在什么级别保存该注释信息,用于描述注解的声明周期
| 取值RetentionPolicy | 作用 |
| SOURCE | 在源文件有效(即源文件保留) |
| CLASS | 在class文件中有效(即class保留) |
| RUNTIME |
在运行时有效(即运行时保留) 为Runtime可以被反射机制读取 |
(3)@Documented
(4)@Inherited
Eg:
@Target(value=ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface MyAnnotation01 { String studentName() default ""; int age() default 0; String[] value(); }
5.ORM(Object relationship Mapping)对象关系映射
类和表结构对应
属性和字段对应
对象和记录对应
@Target(value=ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) public @interface SxtTable { String value(); } @Target(value=ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface SxtField { String columnName(); String type(); int length(); } @SxtTable("tb_student") public class Student { @SxtField(columnName="id",type="int",length=10) private int id; @SxtField(columnName="sname",type="varchar",length=10) private String studentName; @SxtField(columnName="age",type="int",length=3) private int age; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getStudentName() { return studentName; } public void setStudentName(String studentName) { this.studentName = studentName; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } /** * 使用反射读取注解的信息,模拟处理注解信息的流程 * @author MA * */ public class Demo3 { public static void main(String[] args) throws NoSuchFieldException, SecurityException { try { Class clazz = Class.forName("com.mxj.test.annotation.Student"); //获得类的所有注解 Annotation[] annotations = clazz.getAnnotations(); for(Annotation a:annotations){ System.out.println(a); } //获得类的指定的注解 SxtTable table = (SxtTable) clazz.getAnnotation(SxtTable.class); System.out.println(table.value()); //获得类的属性的注解 Field f = clazz.getDeclaredField("studentName"); SxtField sxtField = f.getAnnotation(SxtField.class); System.out.println(sxtField.columnName()+"---"+sxtField.type()+"---"+sxtField.length()); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
6.反射机制 reflection
反射机制指的是可以在运行时加载、探知、使用编译期间完全未知的类。程序在运行状态中,可以动态加载一个只有名称的类,对于任意一个已加载的类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;
Class c = Class. forName ("com.mxj.test.User");
加载完类之后,在堆内存中,就产生了一个 Class 类型的对象(一个类只有一个 Class 对象),这个对象就包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。
/** * 应用反射的API,获取类的信息(类的名字,属性,方法,构造器等) * @author MA * */ public class Demo02 { public static void main(String[] args) throws Exception { String path = "com.mxj.test.bean.User"; try { Class clazz = Class.forName(path); //获取类的名字 System.out.println(clazz.getName());//获得包名+类名 System.out.println(clazz.getSimpleName());//获得类名:User //获得属性信息 //Field[] fields = clazz.getFields();//只能获得public的属性 Field[] fields = clazz.getDeclaredFields();//获得所有的field Field f = clazz.getDeclaredField("uname"); //获得方法信息 Method[] method = clazz.getDeclaredMethods(); Method m01 = clazz.getDeclaredMethod("getUname", null); Method m02 = clazz.getDeclaredMethod("setUname", String.class); //获得构造器信息 Constructor[] constructors = clazz.getDeclaredConstructors();//获得所有构造器 Constructor c1 = clazz.getDeclaredConstructor(null);//获取无参构造器 Constructor c2 = clazz.getDeclaredConstructor(int.class,int.class,String.class); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }
/** * 通过反射API动态的操作:构造器、方法、属性 * @author MA * */ public class Demo03 { public static void main(String[] args) { String path = "com.mxj.test.bean.User"; try { Class clazz = Class.forName(path); //通过动态调用构造方法,构造对象 User u1 = (User) clazz.newInstance();//其实调用了User的无参构造方法 Constructor<User> c= clazz.getConstructor(int.class,int.class,String.class); User u2 = c.newInstance(1001,18,"22"); //通过反射API调用普通方法 User u3 = (User) clazz.newInstance(); Method method = clazz.getDeclaredMethod("setUname", String.class); method.invoke(u3, "333"); //通过反射API操作属性 User u4 = (User) clazz.newInstance(); Field f = clazz.getDeclaredField("uname"); f.setAccessible(true);//这个属性不用做安全检查(private),可以直接访问 f.set(u4, "4444"); //通过反射直接写属性 System.out.println(u4.getUname());//通过对象调用 System.out.println(f.get(u4));//通过反射直接读属性 } catch (Exception e) { e.printStackTrace(); } } }
反射机制性能问题:
setAccessible启用和禁用访问安全检查的开关,值为true则反射的对象在使用时应该取消java语法访问检查,值为false则反射的对象应该实施java语言访问检查。禁止安全检查,可以提高反射的运行速度。
7.动态编译
应用场景:上传服务器编译和运行的在线评测系统
服务器动态加载某些类文件进行编译
动态编译的两种做法:
(1)通过Runtime调用javac,启动新的进程去操作
Runtime run = Runtime.getRuntime();
Process process = run.exec("javac -cp d:/myjava/ HelloWorld.java");
(2)通过javaCompiler动态编译
public class Demo01 { public static void main(String[] args) {
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); int result = compiler.run(null, null, null, "D:/HelloWorld.java"); System.out.println(result==0?"编译成功":"编译失败"); } }
动态运行编译好的类:
(1)通过Runtime. getRuntime() 运行启动新的进程运行
Runtime run = Runtime.getRuntime(); Process process = run.exec("java -cp d:/myjava HelloWorld"); // Process process = run.exec("java -cp "+dir+" "+classFile);
(2)通过反射运行编译好的类
//通过反射运行程序 public static void runJavaClassByReflect(String dir,String classFile) throws Exception{ try { URL[] urls = new URL[] {new URL("file:/"+dir)}; URLClassLoader loader = new URLClassLoader(urls); Class c = loader.loadClass(classFile); //调用加载类的main方法 Method m = c.getMethod("main",String[].class);
m.invoke(null, (Object)newString[]{}); } catch (Exception e) { e.printStackTrace(); } }
8.java脚本引擎(JDK6.0之后添加的新功能)
脚本引擎介绍:
- 使得 Java 应用程序可以通过一套固定的接口与各种脚本引擎交互,从而达到在 Java 平台上调用各种脚本语言的目的。
- Java 脚本 API 是连通 Java 平台和脚本语言的桥梁。
- 可以把一些复杂异变的业务逻辑交给脚本语言处理,这又大大提高了开发效率。
/** * 测试脚本引擎执行javascript代码 * @author MA * */ public class Demo01 { public static void main(String[] args) throws Exception { //获得脚本引擎对象 ScriptEngineManager sem = new ScriptEngineManager(); ScriptEngine engine = sem.getEngineByName("JavaScript"); //定义变量,存储到引擎上下文中 engine.put("msg", "HelloWorld!"); String str = "var user = {name:'mxj',age:18,schools:['清华大学','sau']};"; str += "print(user.name);"; //执行脚本 engine.eval(str); engine.eval("msg = '12455';"); System.out.println(engine.get("msg")); System.out.println("###################"); //定义函数 engine.eval("function add(a,b){var sum = a+b; return sum;}"); //取得调用接口 Invocable jsInvoke = (Invocable) engine; //执行脚本中定义的方法 Object result = jsInvoke.invokeFunction("add",new Object[]{13,20}); System.out.println(result); //导入其他java包,使用其他包中的java类 String jsCode = "var list=java.util.Arrays.asList(["1232","mxj","hello"]);"; engine.eval(jsCode); List<String> list2 = (List<String>) engine.get("list"); for(String temp : list2){ System.out.println(temp); } //执行一个js文件 URL url = Demo01.class.getClassLoader().getResource("a.js"); engine.eval(new FileReader(url.getPath())); } }
2019.5.22
1.java动态性的两种常见实现方式
字节码操作:比反射开销小,性能高
反射
2.JAVAssist库的简单使用
/** * 测试使用javassist生成一个新的类 * @author MA * */ public class Demo01 { public static void main(String[] args) throws Exception { ClassPool pool = ClassPool.getDefault(); CtClass cc = pool.makeClass("com.mxj.bean.Emp"); //创建属性 CtField f1 = CtField.make("private int empno;", cc); CtField f2 = CtField.make("private String ename;", cc); cc.addField(f1); cc.addField(f2); //创建方法 CtMethod m1 = CtMethod.make("public int getEmpno(){return empno;}", cc); CtMethod m2 = CtMethod.make("public void setEmpno(int empno){this.empno = empno;}", cc); cc.addMethod(m1); cc.addMethod(m2); //添加构造器 CtConstructor constructor = new CtConstructor(new CtClass[]{CtClass.intType,pool.get("java.lang.String")}, cc); constructor.setBody("{this.empno=empno;this.ename=ename;}"); cc.addConstructor(constructor); cc.writeFile("D:\develop\xuexi\TestJavassist");//将构建好的类写入到工作空间 System.out.println("生成类成功"); } }
2019.5.30
1.单例模式
(1)单例模式的优点:
由于单例模式只生成一个实例,减少了系统性能开销,当一个对象的产生需要比较多的资源时,如读取配置、产生其他依赖对象时,则可以通过在应用启动时直接产生一个单例对象,然后永久驻留内存的方式来解决单例模式可以在系统设置全局的访问点,优化环共享资源访问,例如可以设计一个单例类,负责所有数据表的映射处理
(2)常见的五种单例模式实现方式:
主要:
• 饿汉式(线程安全,调用效率高。 但是,不能延时加载。)
• 懒汉式(线程安全,调用效率不高。 但是,可以延时加载。)
其他:
• 双重检测锁式(由于JVM底层内部模型原因,偶尔会出问题。不建议使用)
• 静态内部类式(线程安全,调用效率高。 但是,可以延时加载)
• 枚举式(线程安全,调用效率高,不能延时加载。并且可以天然的防止反射和反序列化漏洞!)
(3)如何选用?
单例对象 占用 资源 少,不需要 延时加载:枚举式 好于 饿汉式
单例对象 占用 资源 大,需要 延时加载:静态内部类式 好于 懒汉式
(4)双重检测锁实现
public class SingletonDemo03 { private static SingletonDemo03 instance = null; public static SingletonDemo03 getInstance() { if (instance == null) { SingletonDemo03 sc; synchronized (SingletonDemo03.class) { sc = instance; if (sc == null) { synchronized (SingletonDemo03.class) { if(sc == null) { sc = new SingletonDemo03(); } } instance = sc; } } } return instance; } private SingletonDemo03() { } }
(5)静态内部类实现方式(也是一种懒加载方式)
public class SingletonDemo04 { private static class SingletonClassInstance { private static final SingletonDemo04 instance = new SingletonDemo04(); } public static SingletonDemo04 getInstance() { return SingletonClassInstance.instance; } private SingletonDemo04() { } }
(6) 使用枚举实现单例模式
public enum SingletonDemo05 { /** * 定义一个枚举的元素,它就代表了Singleton 的一个实例。 */ INSTANCE; /** * 单例可以有自己的操作 */ public void singletonOperation(){ // 功能处理 } }
public static void main(String[] args) { SingletonDemo05 sd = SingletonDemo05.INSTANCE; SingletonDemo05 sd2 = SingletonDemo05.INSTANCE; System.out.println(sd==sd2); }
(7) 反射可以破解上面几种(不包含枚举式)实现方式!(可以在构造方法中手动抛出异常控制)
public class SingletonDemo01 implements Serializable { private static SingletonDemo01 s; private SingletonDemo01() throws Exception{ if(s!=null){ // 通过手动抛出异常,避免通过反射创建多个单例对象! throw new Exception(" 只能创建一个对象"); } } //私有化构造器 }
(8)反序列化可以破解上面几种((不包含枚举式))实现方式!(可以通过定义readResolve()防止获得不同对象)
反序列化时,如果对象所在类定义了readResolve(),(实际是一种回调),定义返回哪个对象。
public class SingletonDemo01 implements Serializable { private static SingletonDemo01 s; public static synchronized SingletonDemo01 getInstance() throws Exception{ if(s!=null){ // 通过手动抛出异常,避免通过反射创建多个单例对象! throw new Exception(" 只能创建一个对象"); } return s; }
//反序列化时,如果对象所在类定义了readResolve() ,(实际是一种回调),定义返回哪个对象。 private Object readResolve() throws ObjectStreamException { return s; } }
2.工厂模式
(1)工厂模式:
实现了创建者和调用者的分离。
详细分类:
简单工厂模式:用来生产同一等级结构中的任意产品
工厂方法模式:用来生产同一等级结构中的固定产品
抽象工厂模式:用来生产不同产品族的全部产品
(2)核心本质:
实例化对象,用工厂方法代替new操作。
将选择实现类、创建对象统一管理和控制。从而将调用者跟我们的实现类解耦。
(3)面向对象设计的基本原则:
OCP(开闭原则,Open-Closed Principle):一个软件的实体应当对扩展开放,对修改关闭。
DIP(依赖倒转原则,Dependence Inversion Principle):要针对接口编程,不要针对实现编程。
LoD(迪米特法则,Law of Demeter):只与你直接的朋友通信,而避免和陌生人通信。
3.适配器adapter模式
(1)什么是适配器模式?
将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作。
(2)模式中的角色
目标接口(Target):客户所期待的接口。目标可以是具体的或抽象的类,也可以是接口。
需要适配的类(Adaptee):需要适配的类或适配者类。
适配器(Adapter):通过包装一个需要适配的对象,把原接口转换成目标接口。
类适配器:
class Adapter extends Adaptee implements Target{ public void request() { super.specificRequest(); } }
对象适配器:
class Adapter implements Target{ private Adaptee adaptee; public Adapter (Adaptee adaptee) { this.adaptee = adaptee; } public void request() { this.adaptee.specificRequest(); } }
2019.6.3
1.MySQL数据库的命令操作
- 配置环境变量
将bin目录配置到path中
- 命令行操作
| 登陆操作 | mysql -hlocalhost –uroot –p123456 |
| 退出操作 | exit |
| 数据库操作 | 建库:create database 库名; 卸载库:drop database 库名; 显示所有数据库:show databases; 选择库:use testjdbc; |
| 表操作 | 建表的sql语句; 显示库中所有表:show tables; 显示某个表的结构:describe testjdbc; |
| SQL操作 | select语句;Insert语句; update语句; delete语句; 表操作DDL语句(create, alter, drop等); |
2.什么是JDBA?
JDBC(Java Database Connection)为java开发者使用数据库提供了统一的编程接口,它由一组java类和接口组成。是java程序与数据库系统通信的标准API。JDBC API 使得开发人员可以使用纯java的方式来连接数据库,并执行操作。
3.JDBC常用接口
(1) Driver接口
Driver接口由数据库厂家提供,对于java开发者而言,只需要使用Driver接口就可以了。
在编程中要连接数据库,必须先装载特定厂商的数据库驱动程序。不同的数据库有不同的装载方法。
驱动:就是各个数据库厂商实现的Sun公司提出的JDBC接口。 即对Connection等接口的实现类的jar文件
装载MySql驱动
Class.forName("com.mysql.jdbc.Driver");
装载Oracle驱动
Class.forName("oracle.jdbc.driver.OracleDriver");
(2)DriverManager接口
DriverManager是JDBC的管理层,作用于用户和驱动程序之间。
DriverManager跟踪可用的驱动程序,并在数据库和相应的驱动程序之间建立连接。
(3)Connection接口
Connection与特定数据库的连接(会话),在连接上下文中执行 SQL语句并返回结果。
DriverManager的getConnection()方法建立在JDBC URL中定义的数据库Connection连接上
连接MYSQL数据库:
Connection con =
DriverManager.getConnection("jdbc:mysql://host:port/database","user","password");
连接ORACLE数据库:
Connection con =
DriverManager.getConnection("jdbc:oracle:thin:@host:port:databse","user","password");
(4) Statement接口
用于执行静态 SQL 语句并返回它所生成结果的对象。
三种Statement类:
• Statement:
由createStatement创建,用于发送简单的SQL语句。(不带参数的)
• PreparedStatement:
继承自Statement接口,由prepareStatement创建,用于发送含有一个或多个输入参数的sql语句。PreparedStatement对象比Statement对象的效率更高,并且可以防止SQL注入。我们一般都用PreparedStatement.
• CallableStatement:
继承自PreparedStatement 。由方法prePareCall创建,用于调用存储过程。
常用的Statement方法:
• execute():运行语句,返回是否有结果集。
• executeQuery():运行select语句,返回ResultSet结果集。
• executeUpdate():运行insert/update/delete操作,返回更新的行数。
(5)ResultSet接口
Statement执行SQL语句时返回ResultSet结果集。
ResultSet提供的检索不同类型字段的方法,常用的有:
• getString():获得在数据库里是varchar、char等数据类型的对象。
• getFloat():获得杂数据库里是Float类型的对象。
• getDate():获得在数据库里面是Date类型的数据。
• getBoolean():获得在数据库里面是Boolean类型的数据
依序关闭使用之对象及连接:ResultSet -》Statement-》 Connection
/** * 测试PreparedStatement的基本用法 * @author MA * */ public class Demo03 { public static void main(String[] args) { Connection conn = null; PreparedStatement ps = null; try { //加载驱动类 Class.forName("com.mysql.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/testjdbc","root","123456"); String sql="insert into t_user(username,pwd)values(?,?);"; //?占位符 ps = (PreparedStatement) conn.prepareStatement(sql); ps.setString(1, "mxj"); //参数索引从1开始计算 ps.setString(2, "123456"); ps.execute(); } catch (Exception e) { e.printStackTrace(); }finally{ if(ps!=null){ try { ps.close(); } catch (SQLException e) { e.printStackTrace(); } } if(conn!=null){ try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } }
/** * 测试resultSet结果集的基本用法 * @author MA * */ public class Demo04 { public static void main(String[] args) { Connection conn = null; PreparedStatement ps = null; ResultSet rs = null; try { //加载驱动类 Class.forName("com.mysql.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/testjdbc","root","123456"); String sql="select id,username,pwd from t_user where id > ?"; ps = (PreparedStatement) conn.prepareStatement(sql); ps.setObject(1, 2); rs = ps.executeQuery(); while(rs.next()){ System.out.println(rs.getInt(1)+"---"+rs.getString(2)+"---"+rs.getString(3)); } } catch (Exception e) { e.printStackTrace(); }finally{ if(rs!=null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if(ps!=null){ try { ps.close(); } catch (SQLException e) { e.printStackTrace(); } } if(conn!=null){ try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } }
4.批处理
/** * 批处理的基本用法 * @author MA * */ public class Demo05 { public static void main(String[] args) { Connection conn = null; Statement stmt = null; ResultSet rs = null; try { //加载驱动类 Class.forName("com.mysql.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/testjdbc","root","123456"); conn.setAutoCommit(false);//设置手动提交 stmt = (Statement) conn.createStatement(); for(int i=0;i<20000;i++){ stmt.addBatch("insert into t_user(username,pwd,regTime)values('ma"+i+"',666666,now())"); } stmt.executeBatch(); conn.commit(); } catch (Exception e) { e.printStackTrace(); }finally{ if(rs!=null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stmt!=null){ try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if(conn!=null){ try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } }
5.事务的基本概念
一组要么同时执行成功,要么同时执行失败的SQL语句。是数据库操作的一个执行单元!
(1)事务的四大特点(ACID)
atomicity(原子性)
• 表示一个事务内的所有操作是一个整体,要 么全部成功,要么全失败;
consistency(一致性)
• 表示一个事务内有一个操作失败时,所有的更改过的数据都必须回滚到修改前的状态;
isolation(隔离性)
• 事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。
durability(持久性)
• 持久性事务完成之后,它对于系统的影响是永久性的。
(2)事务隔离级别从低到高:
读取未提交(Read Uncommitted)
读取已提交(Read Committed)
可重复读(Repeatable Read)
序列化(serializable)