
Datax的执行过程
要想进行调优,一般先要了解执行过程,执行过程如下: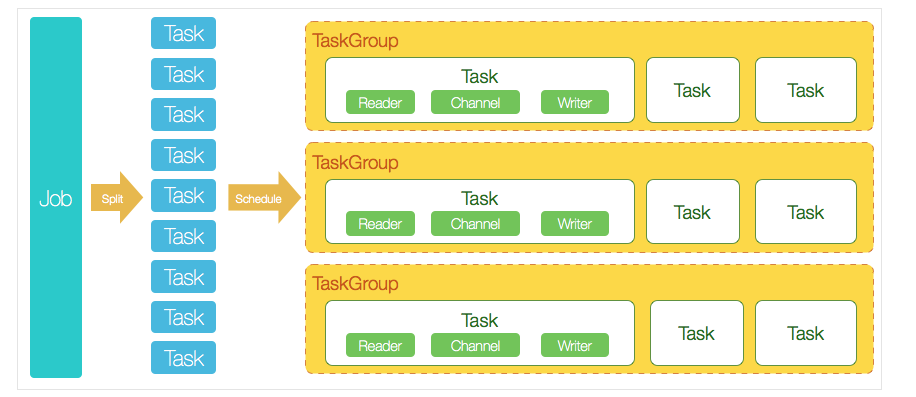
过程详细说明如下:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
简单总结过程如下:
一个DataX Job会切分成多个Task,每个Task会按TaskGroup进行分组,一个Task内部会有一组Reader->Channel->Writer。Channel是连接Reader和Writer的数据交换通道,所有的数据都会经由Channel进行传输
根据过程,我们可以进行如下优化
优化1:提升每个channel的速度
在DataX内部对每个Channel会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是1MB/s,可以根据具体硬件情况设置这个byte速度或者record速度,一般设置byte速度,比如:我们可以把单个Channel的速度上限配置为5MB
优化2:提升DataX Job内Channel并发数 并发数=taskGroup的数量每一个TaskGroup并发执行的Task数 (默认单个任务组的并发数量为5)。
提升job内Channel并发有三种配置方式:
- 配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
- 配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
- 直接配置Channel个数.
配置含义:
job.setting.speed.channel : channel并发数
job.setting.speed.record : 全局配置channel的record限速
job.setting.speed.byte:全局配置channel的byte限速
core.transport.channel.speed.record:单channel的record限速
core.transport.channel.speed.byte:单channel的byte限速
方式1:
举例如下:core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以Channel个数 = 全局Byte限速 / 单Channel Byte限速=5242880/1048576=5个,配置如下:
{ "core": { "transport": { "channel": { "speed": { "byte": 1048576 } } } }, "job": { "setting": { "speed": { "byte" : 5242880 } }, ... } }
方式2:
举例如下:core.transport.channel.speed.record=100,job.setting.speed.record=500,所以配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速=500/100=5
{ "core": { "transport": { "channel": { "speed": { "record": 100 } } } }, "job": { "setting": { "speed": { "record" : 500 } }, ... } }
方式3:
举例如下:直接配置job.setting.speed.channel=5,所以job内Channel并发=5个
{ "job": { "setting": { "speed": { "channel" : 5 } }, ... } }
注意事项
- 当提升DataX Job内Channel并发数时,调整JVM heap参数,原因如下:
- 当一个Job内Channel数变多后,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。
- 例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止jvm报内存溢出等错误,调大jvm的堆参数。
- 通常我们建议将内存设置为4G或者8G,这个也可以根据实际情况来调整
- 调整JVM xms xmx参数的两种方式:一种是直接更改datax.py;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json
- Channel个数并不是越多越好, 原因如下:
- Channel个数的增加,带来的是更多的CPU消耗以及内存消耗。
- 如果Channel并发配置过高导致JVM内存不够用,会出现的情况是发生频繁的Full GC,导出速度会骤降,适得其反。这个可以通过观察日志发现
测试使用datax从mysql到mysql,不同配置测试效果如下:
使用默认单个channel 限速1M/s,测试情况如下,1660s跑完: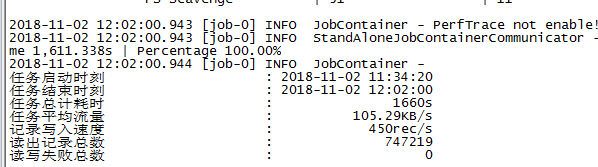
使用单通道,5M/s,测试情况如下,50s跑完: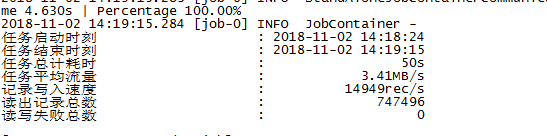
使用5通道,5M/s,测试情况如下,10s跑完: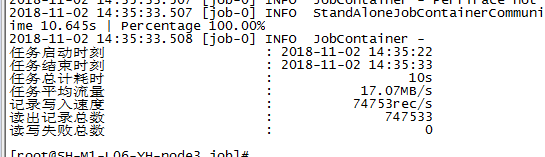
注意:
MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能,splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据,第三个测试不配置splitPk测试不出来效果
调优没有固定的,先了解原理,再根据原理及执行过程进行局部或者全局的调优,谢谢各位阅读