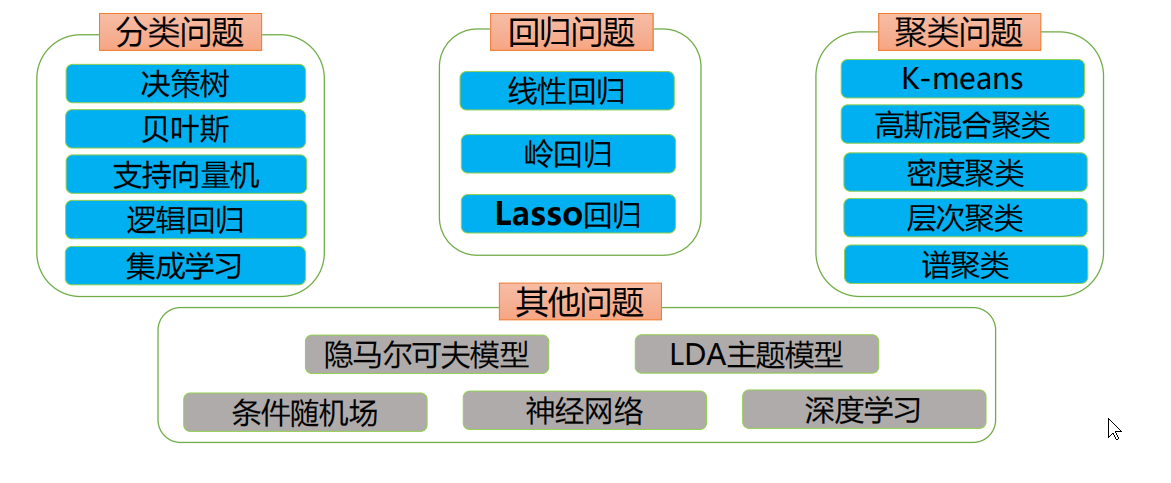
今天学的机器学习部分,做一些总结:
机器学习的一般过程

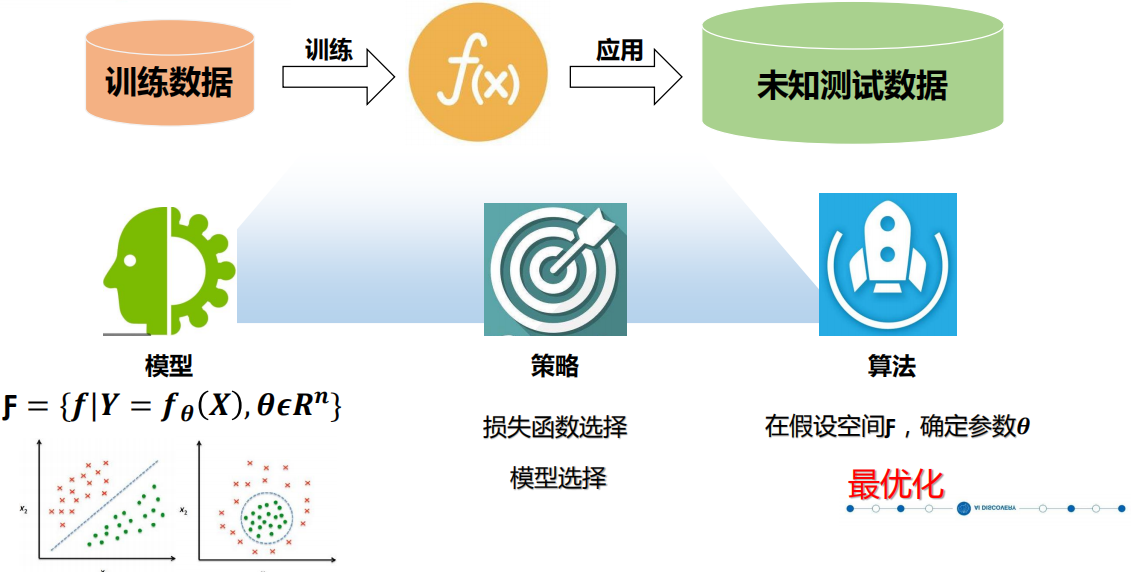
机器学习方法
有监督学习(supervised learning):从给定的有标注的训练数据集中学习出一 个函数(模型参数),当新的数据到来时可以根据这个函数预测结果。 常见任务包 括分类与回归。
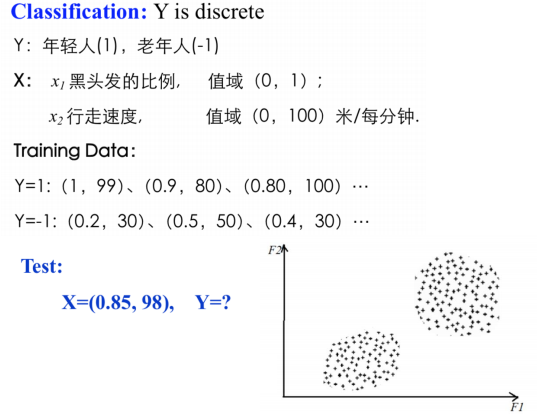
分类:输出是类别标签
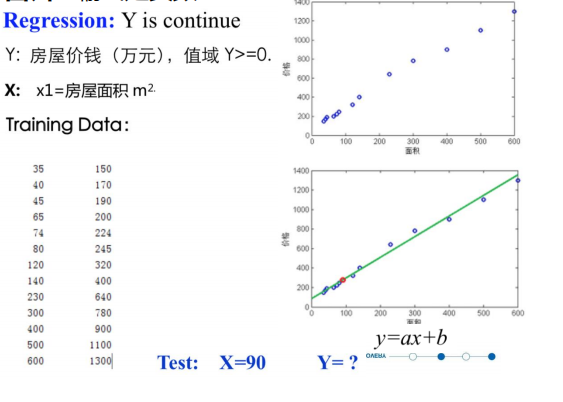
回归:输出是实数
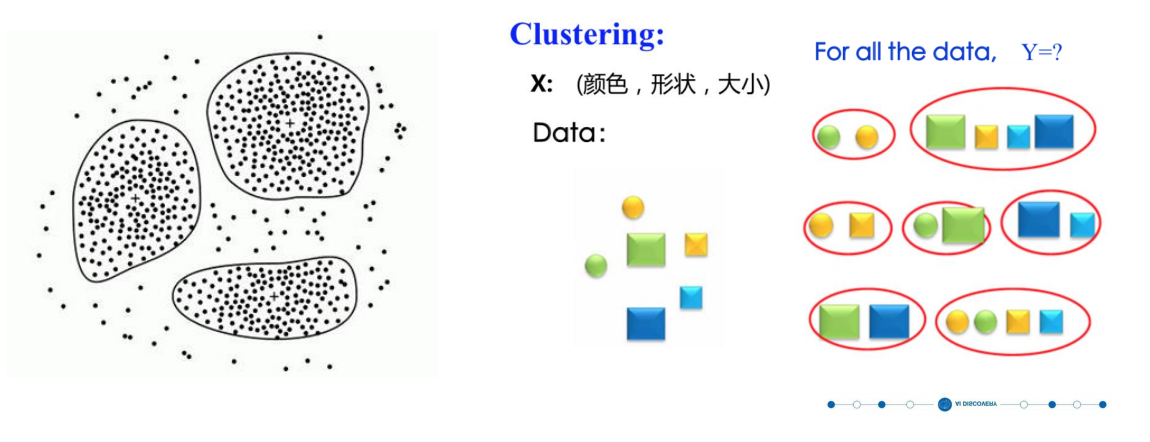
无监督学习(unsupervised learning):没有标注的训练数据集,需要根据样 本间的统计规律对样本集进行分析,常见任务如聚类等。
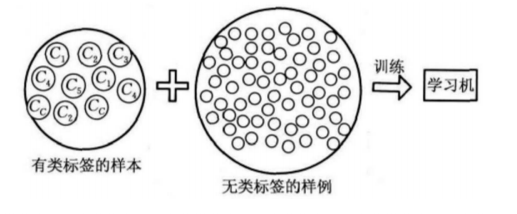
半监督学习(Semi-supervised learning): 结合(少量的)标注训练数据和(大量的)未标 注数据来进行数据的分类学习。
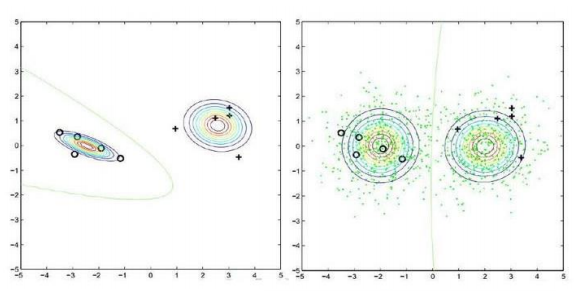
两个基本假设:
• 聚类假设:处在相同聚类中的样本示 例有较大的可能拥有相同的标记。
• 流形假设:处于一个很小的局部区域 内的样本示例具有相似的性质,因此, 其标记也应该相似。
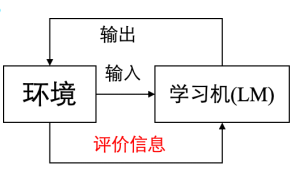
增强学习(Reinforcement Learning):外部环境对输出只给出评价信息而非正确答案,学习机通过强化受奖励的动作来改善自身的性能。
如:让计算机学着去玩Flappy Bird
我们不需要设置具体的策略,比如先飞到上面,再飞到下面,我们只是需要给算法定一个“小目标”!比如当计算机玩的好的时候,我们就给
它一定的奖励,它玩的不好的时候,就给它一定的惩罚,在这个算法框架下,它就可以越来越好,超过人类玩家的水平。
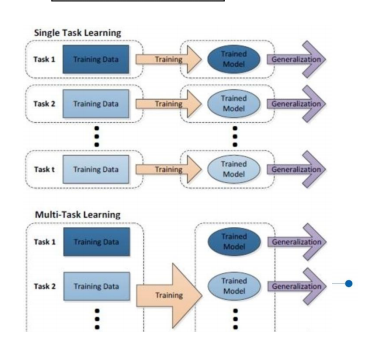
多任务学习(Multi-task Learning):把多个相关 (related)的任务放在一起同时学习。 单任务学习时,各个任务之间的模型空间(Trained Model)是相互 独立的,但现实世界中很多问题不能分解为一个一个独立的子问题, 且这样忽略了问题之间所包含的丰富的关联信息。多任务学习就是为 了解决这个问题而诞生的。多个任务之间共享一些因素,它们可以在 学习过程中,共享它们所学到的信息,相关联的多任务学习比单任务 学习具备更好的泛化(generalization)效果。
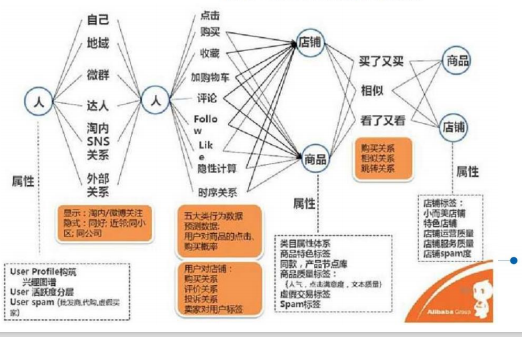
利用点:
搜素引擎:网页、图片、视频、新闻、学术、地图
信息推荐:新闻、商品、游戏、书籍
图片识别:人像、用品、动物、交通工具
用户分析:社交网络、影评、商品评论 机
器翻译、摘要生成……
生物信息学……
机器学习准备
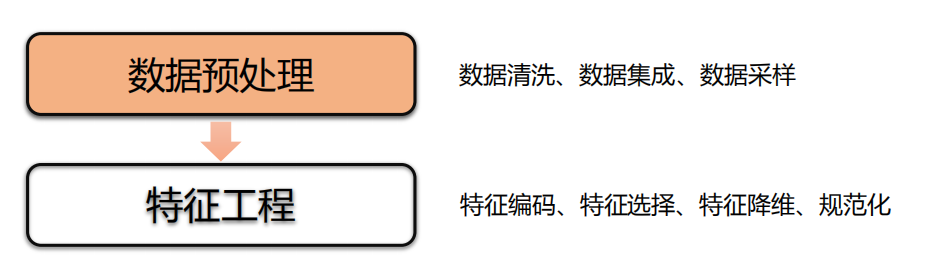
数据清洗:

数据采样

数据集拆分

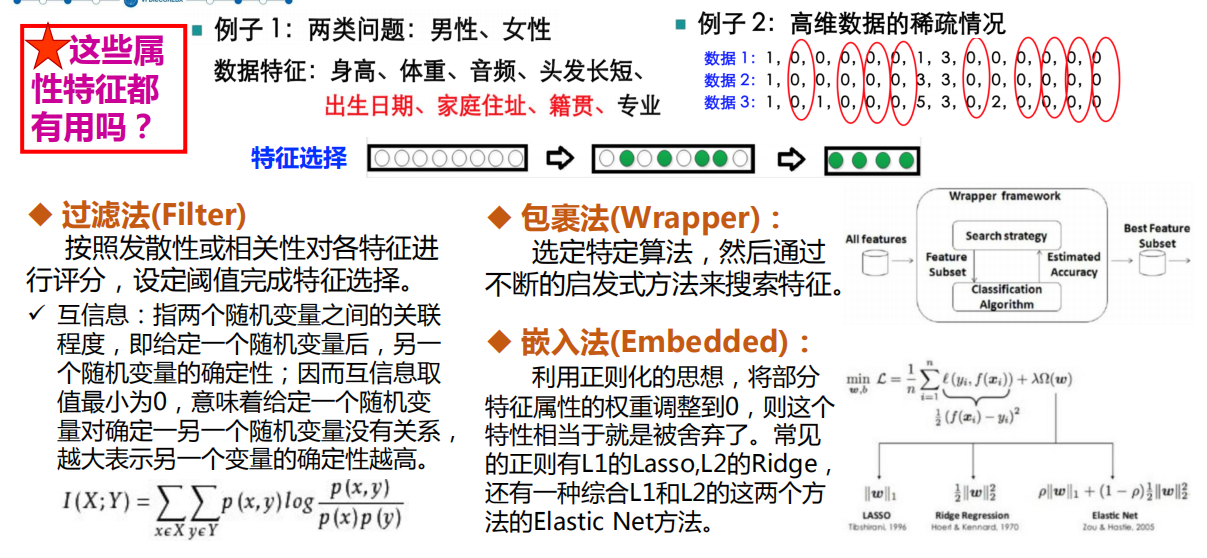
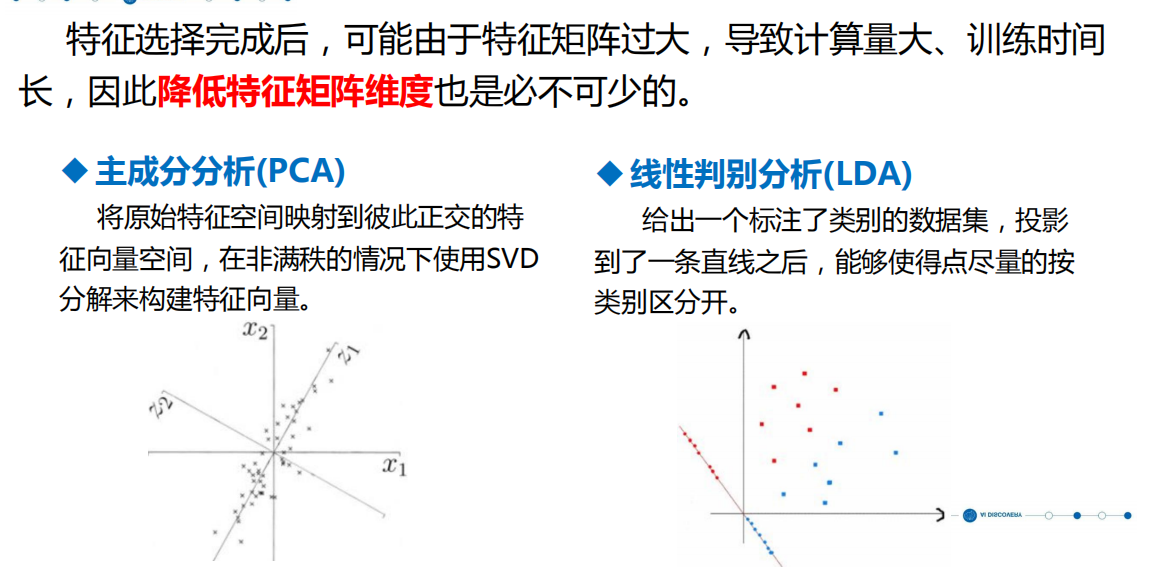
特征选择:
特征降维
特征编码


规范化

举例子:

以下是扩展: