kafka学习推荐网站:orcHome(https://www.orchome.com/kafka/index)
消息系统的两种模式
1.生产者/消费者模式:
Producer(生产者):在数据管道一段生产消息的应用程序。
Consumer(消费者):在数据管道一端消费消息的应用程序。
- 生产者将消息发送至队列,如果此时没有任何消费者连接队列、消费消息,那么消息将会保存在队列中,直到队列满或者有消费者上线。
- 生产者将消息发送至队列,如果此时有多个消费者连接队列,那么对于同一条消息而言,仅会发送至其中的某一个消费者。因此,当有多个消费者时,实际上就是一个天然的负载均衡。
2.发布/订阅模式:
Publisher(发布者):在数据管道一端生成事件的应用程序。
Subscriber(订阅者):在数据管道一端响应事件的应用程序。
- 发布者发布事件,如果此时队列上没有连接任何订阅者,则此事件丢失,即没有任何应用程序对该事件作出响应。将来如果有订阅者上线,也不会重新收到该事件。
- 发布者发布事件,如果此时队列上连接了多个订阅者,则此事件会广播至所有的订阅者,每个订阅者都会收到完全相同的事件。所以不存在负载均衡。
Kafka是分布式发布-订阅消息系统
三个主要作用:
- 发布&订阅:和其他消息系统一样,发布订阅流式数据。
- 处理:编写流处理应用程序,对实时事件进行响应。
- 存储:在一个分布式、容错的集群中安全地存储流式数据。
Kafka角色
官方文档: http://kafka.apache.org/intro
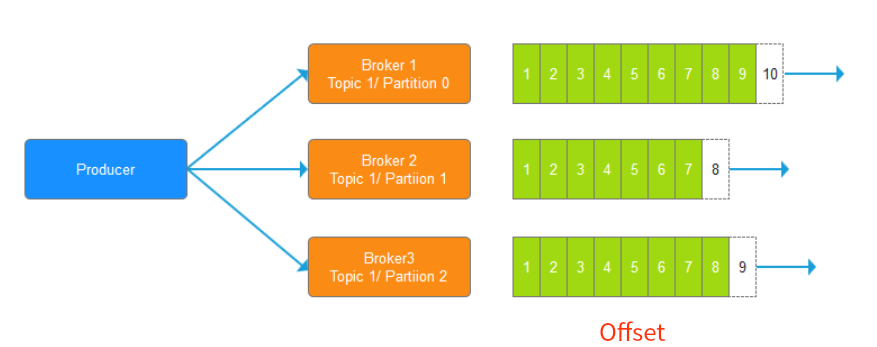
Broker
集群的一台机器中的一个Kafka,就是一个Broker,可以认为是一个kafka节点
Topic
逻辑概念上的消息集和;
- 一个Topic可分为多个Partition分区,多个partition中有一个leader和多个follower;
- 每个broker中只会存在同一个Topic的其中一个partition;
Partition
官方文档描述:
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log.
The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
简而言之:partition是一个有序(offset维护),不可变的记录集,每个记录都有唯一的offset标识;
生产者发送消息,只会发送到topic的其中一个分区内!!
但是会经过同步到不同节点的同一个partition的副本下!!
也就意味着,一个topic下的,某条消息,只会被同一组内的某一个消费者消费!
- 发往Partition的每条消息将获得一个递增id,称为offset(偏移量),一次来保持消息的有序
- 分区越多,并行处理数就越多。通常的建议是主机数x2,例如如果集群中有3台服务器,则对每个主题可以创建6个分区。
- 当消息被写入分区后,就不可变了,无法再进行修改。除非重建主题,修改数据后重新发送。
- 当没有key时,数据会被发往主题的任意一个分区;当有key时,相同key的数据会被发往同一个分区。
为什么要分区?
- 降低每个broker(服务器)的负载;
- 方便地在集群中扩展;
- 多副本能提高容错;
- 读数据的时候,提高并发;
offset
单独写一篇:
【kafka】offset
Message
Partition中存储的消息即Message
每条Message包含有三个属性:
- Offset:消息的唯一标示(long类型)上图所示,每一个标示都是一条消息
- MessageSize:消息长度(Int类型)
- data:Message具体内容
Producer
发布消息的对象,往某个topic中发布消息,也负责选择发布到topic中的哪个分区。
- Producer只需要指定Topic的名称(Name)Kafka会自动进行负载均衡,并将对写入操作进行路由,从而写入到正确的Partition当中
Consumer
Consumer采取pull模式,从broker中拉取数据;
缺点:如果broker中没有数据,消费者会一直返回空数据;针对这点,kafka会在消费者消费的时候给出一个时长参数timeout,如果broker没数据,Consumer会等待timeout时长,之后再返回;
分区分配策略
一个消费者组有多个Consumer,一个Topic有多个Partition;
一个组内的Consumer不能消费同一个Partition,一个partition只会被同一个消费组内的一个消费者消费;
那么如何分配Partition和消费者之间是如何分配订阅的 ?
有两种策略:
-
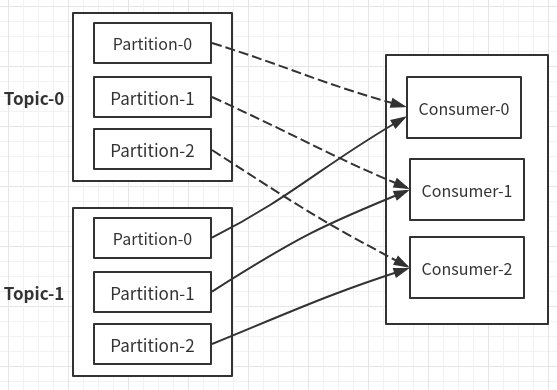
RoundRobin(轮讯):
使用前提:此消费者组内Consumer订阅的Topic一致;因为轮讯会把订阅的Topic当成整体进行分发;
按顺序,每个Topic的第一个分区,分给Consumer-0;
然后第二个分区分给Consumer-1,依次类推;
-
Range(默认分区策略):
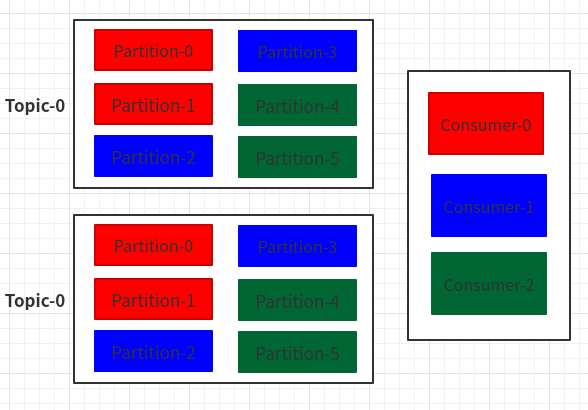
先根据Partition数量和消费者数量,算出,每个消费者应该分几个Paritition,然后,按顺序分发;
消费者故障维护
消费者故障,恢复之后,需要维护offset,从故障前的offset重新开始消费;
所以:Consumer需要实时记录自己消费到的offset,故障恢复后,继续消费;
在Kafka0.9之后,消费者的offset默认保存在了Kafka本地的topic中;
rebalance
在partition和消费者,之间已经分配好订阅关系之后,如果出现如下情况,将发生rebalance
- 组成员发生变更
- 订阅主题的分区数发生变更
- 订阅主题数发生变更
rebalance情况复杂:
扔个大佬连接:
https://www.cnblogs.com/songanwei/p/9202803.html
集群架构方式
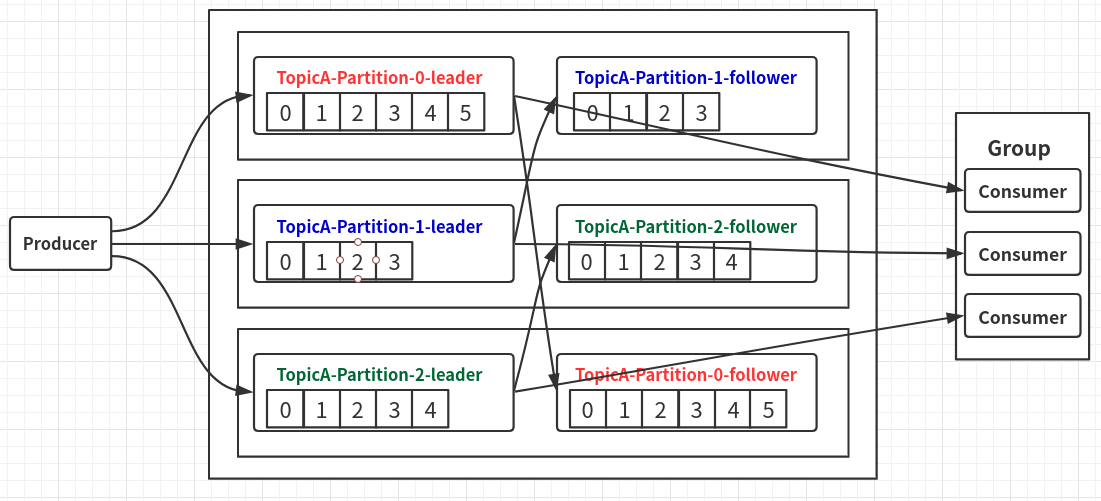
上图是:一个Topic,3个分区,2份备份的流程:
- Producer生产一个Topic,创建了3个分区,每个分区都会先有一个Leader,然后在其他机器中,创建自己分区的follower(副本);